湖仓一体之前,数据分析经历了数据库、数据仓库和数据湖分析三个时代。
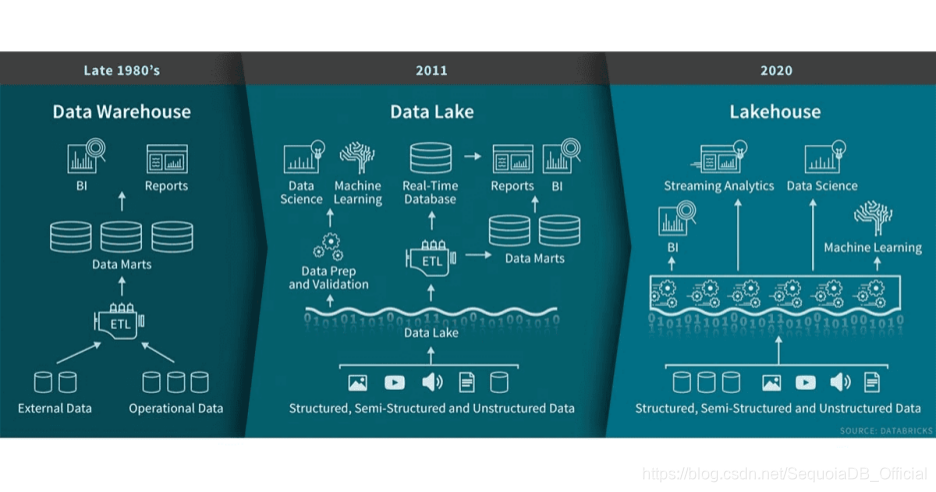
- 首先是数据库,它是一个最基础的概念,主要负责联机事务处理,也提供基本的数据分析能力。
- 随着数据量的增长,出现了数据仓库,它存储的是经过清洗、加工以及建模后的高价值的数据,供业务人员进行数据分析。
- 数据湖的出现,主要是为了去满足企业对原始数据的存储、管理和再加工的需求。这里的需求主要包括两部分,首先要有一个低成本的存储,用于存储结构化、半结构化,甚至非结构化的数据;另外,就是希望有一套包括数据处理、数据管理以及数据治理在内的一体化解决方案。
数据仓库解决了数据快速分析的需求,数据湖解决了数据的存储和管理的需求,而湖仓一体要解决的就是如何让数据能够在数据湖和数据仓库之间进行无缝的集成和自由的流转,从而帮助用户直接利用数据仓库的能力来解决数据湖中的数据分析问题,同时又能充分利用数据湖的数据管理能力来提升数据的价值。
核心技术解析
Doris 设计的湖仓一体是如何实现加速数据湖的分析能力的,以下五个核心技术是关键:
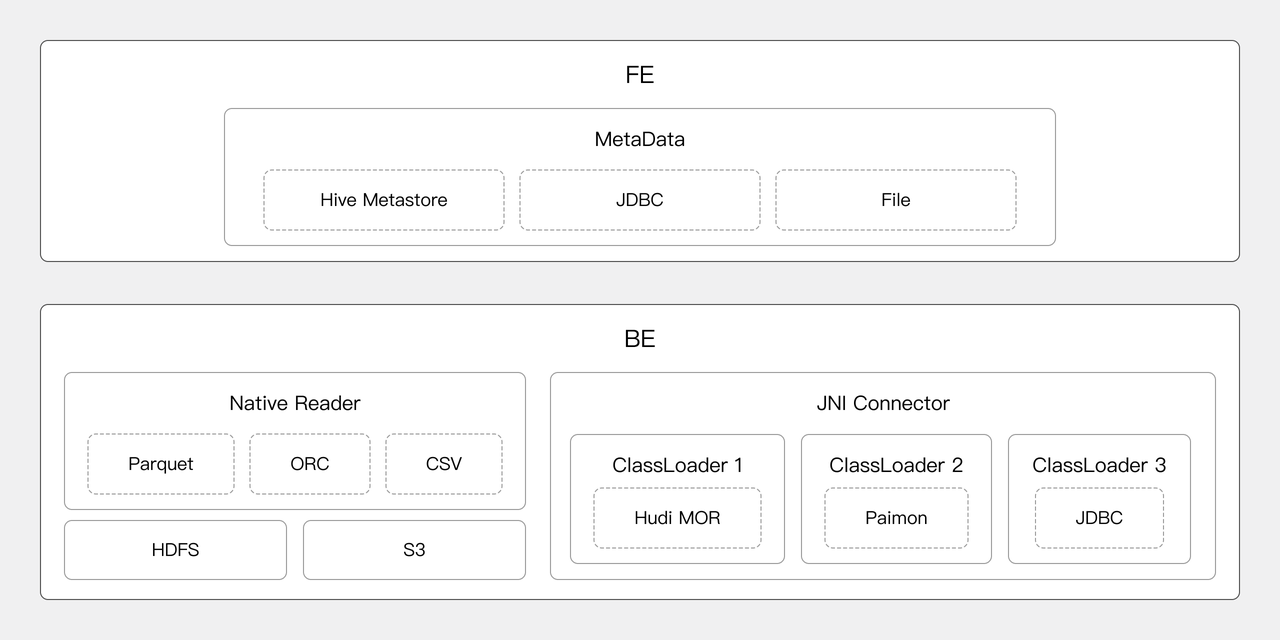
可扩展的连接框架
在数据的对接中包括元数据的对接和数据的读取。
-
元数据对接:元数据对接在 FE 完成,通过 FE 的 MetaData 管理器来实现基于 HiveMetastore、JDBC 和文件的元数据对接和管理工作。
-
数据读取:通过 NativeReader 可以高效的读取存放在 HDFS、对象存储上的 Parquet、ORC、Text 格式数据。也可以通过 JniConnector 对接 Java 大数据生态。
高效缓存策略
Doris 通过元数据缓存、数据缓存和查询结果缓存来提升查询性能。
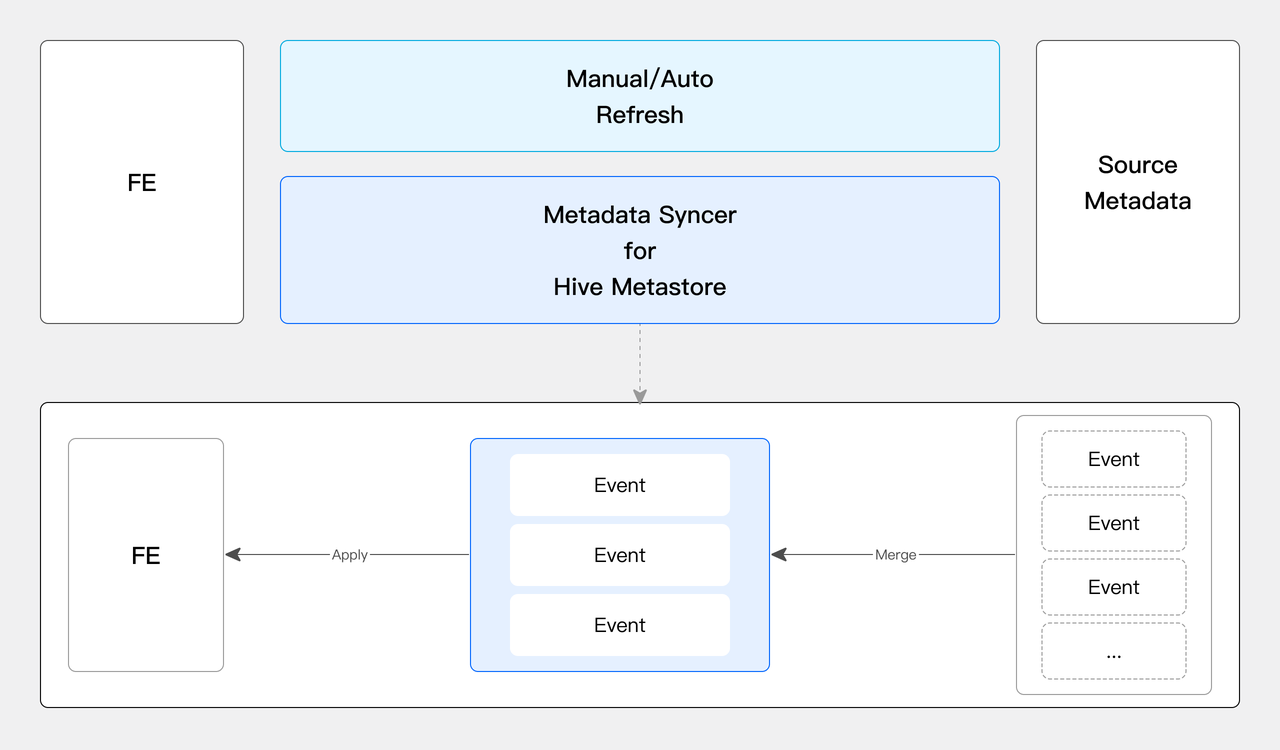
元数据缓存
Doris 提供了手动同步元数据、定期自动同步元数据、元数据订阅(只支持 HiveMetastore)三种方式来同步数据湖的元数据信息到 Doris,并将元数据存储在 Doris 的 FE 的内存中。当用户发起查询后 Doris 直接从内存中获取元数据并快速生成查询规划。保障了元数据的实时和高效。在元数据同步上 Doris 通过并发的元数据事件合并实现高效的元数据同步,其每秒可以处理 100 个以上的元数据事件。
高效的数据缓存
-
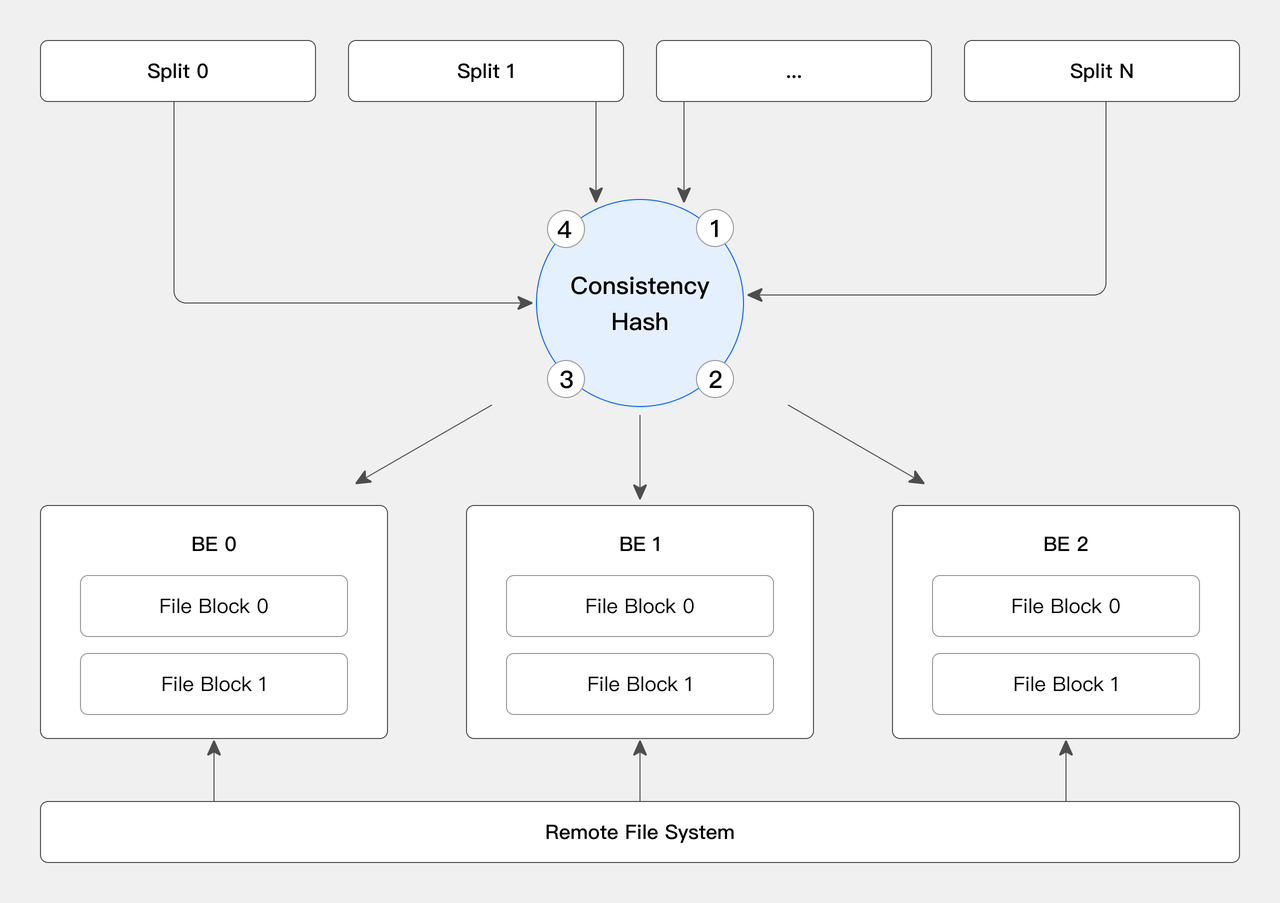
文件缓存:Doris 通过将数据湖中的热点数据存储在本地磁盘上,减少数据扫描过程中网络数据的传输,提高数据访问的性能。
-
缓存分布策略:在数据缓存中 Doris 通过一致性哈希将数据分布在各个 BE 节点上,尽量避免节点扩缩容带来的缓存失效问题。
-
缓存淘汰(更新)策略:同时当 Doris 发现数据文件对应的元数据更新后,会及时淘汰缓存以保障数据的一致性。
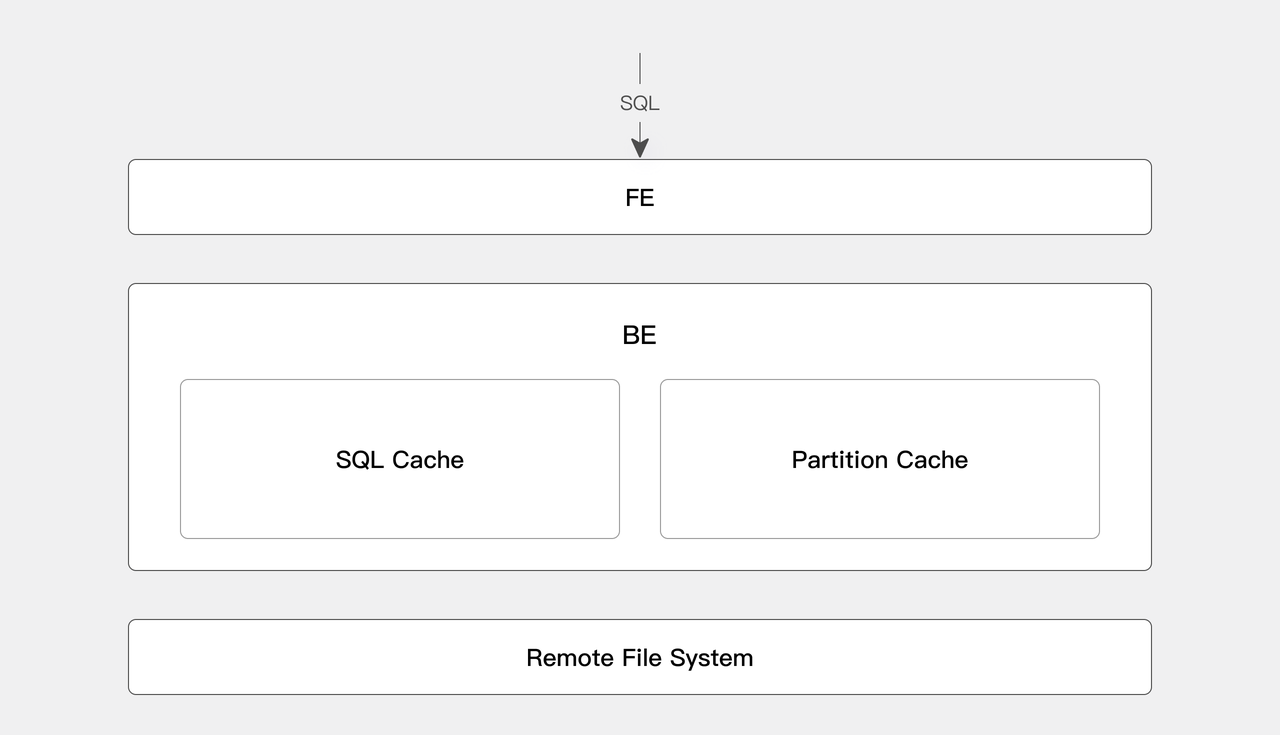
查询结果缓存和分区缓存
-
查询结果缓存:Doris 根据 SQL 语句将之前查询的结果缓存起来,当下次相同的查询再次发起时可以直接从缓存中获取数据返回到客户端,极大的提高了查询的效率和并发。
-
分区缓存:Doris 还支持将部分分区数据缓存在 BE 端提升查询效率。比如查询最近 7 天的数据,可以将前 6 天的计算后的缓存结果,和当天的事实计算结果进行合并,得到最终查询结果,最大限度减少实时计算的数据量,提升查询效率。
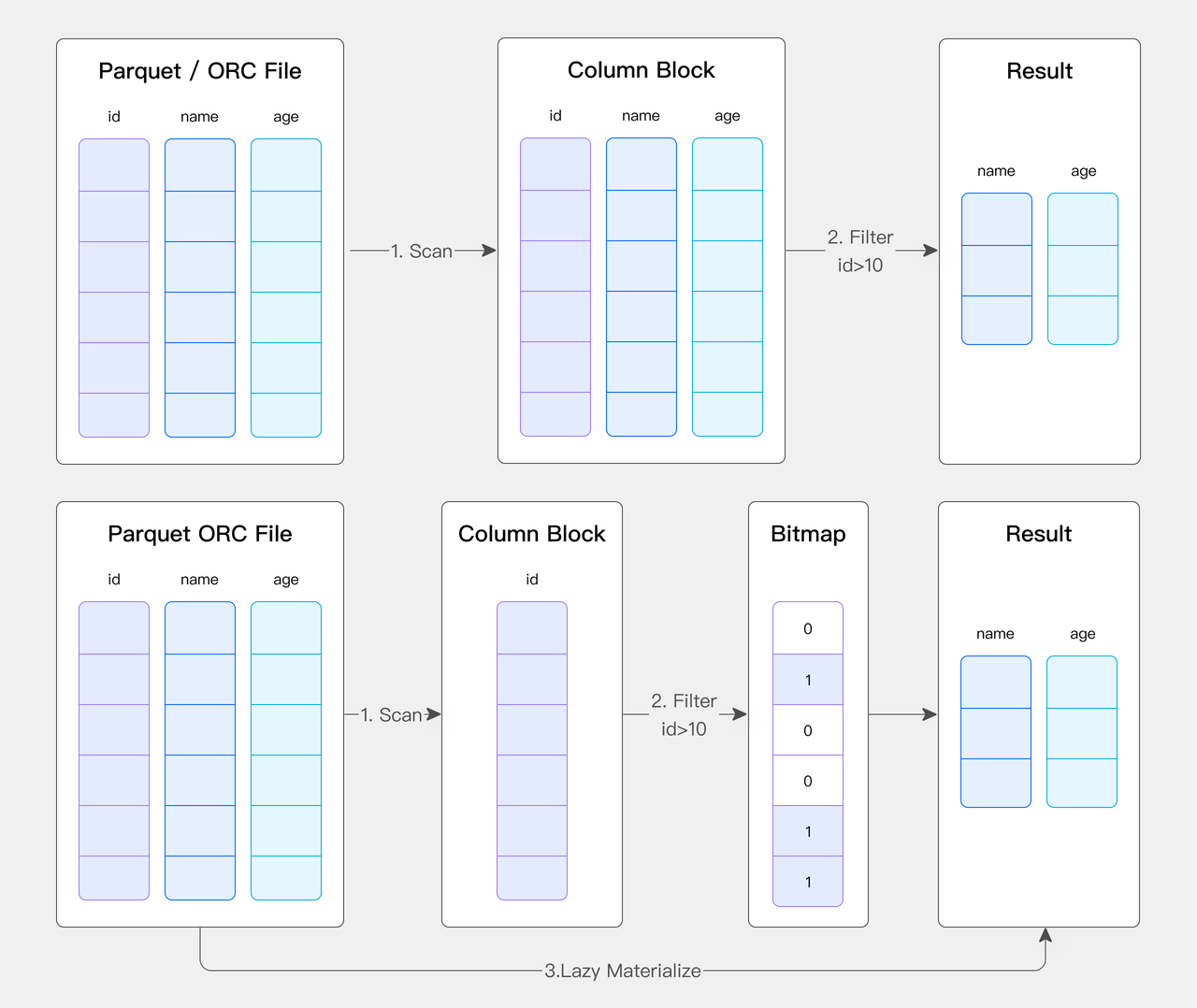
高效的 Native Reader
-
自研 Native Reader 避免数据转换:Doris 在数据分析时有其自身的列存方式,同时 Parquet、ORC 也有自身的列存格式。如果直接使用开源的 Parquet 或者 ORC Reader 的话就会存在一个 Doris 列存和 Parquet/ORC 列存的转换过程。这样的话就会多一次格式转换的开销,为了解决这个问题 我们自研了一套 Parquet/ORC NativeReader,直接读取 Parquet、ORC 文件来提高查询效率。
-
延迟物化:同时我们实现的 Native Reader 还能很好的利用智能索引和过滤器提高数据读取效率。比如说在某些场景下我可能只针对 ID 列去做一个过滤。我们的优化做法是首先第一步我会把 ID 列单独读出来。然后在这一列上做完过滤以后,我会把这个过滤后的剩余下来的这个行号记录下来。拿这个行号再去读剩下两列,这样来进一步的减少数据扫描,加速文件的分析性能。
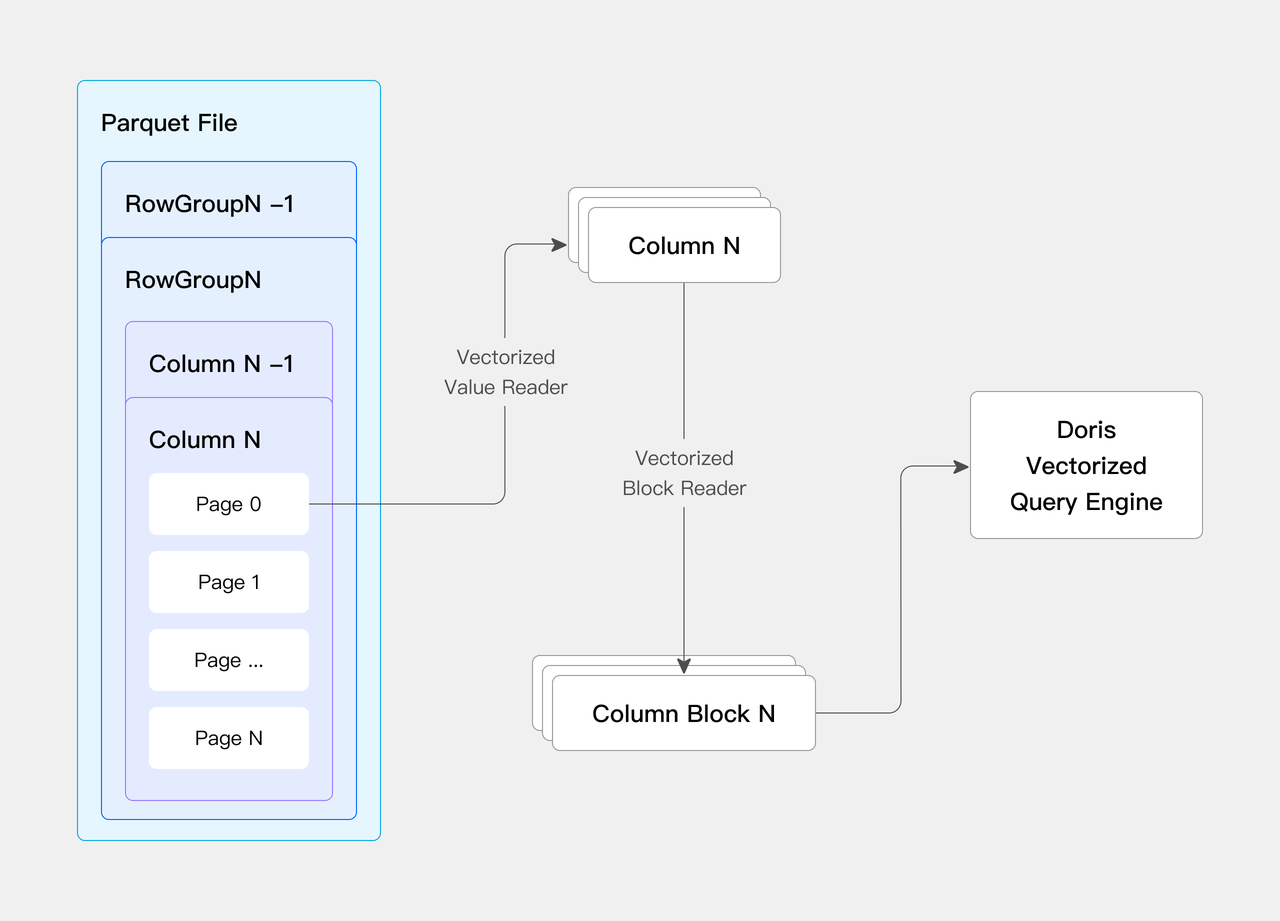
- 向量化读取数据:同时在文件数据的读取过程中我们引入向量化的方式读取数据,极大加速了数据读取效率。
Merge IO
在网络中难免会出现大量小文件的网络 IO 请求取影响 IO 性能,在这种情况下我们采用 IO 合并去优化这种情况。
比如我们设置一个策略将小于 3MB 的 IO 请求合并(Merge IO)在一次请求中处理。那么之前可能是有 8 次的小的 IO 请求,我们可以把 8 次合并成 5 次 IO 请求去去读取数据。这样减少了网络 IO 请求的速度,提高了网络访问数据的效率。
Merge IO 的确定是它可能会读取一些不必要的数据,因为它把中间可能不必要读取的数据合并起来一块读过来了。但是从整体的吞吐上来讲其性能有很大的提高,在碎文件(比如:1KB - 1MB)较多的场景优化效果很明显。同时我们通过控制 Merge IO 的大小来达到整体的平衡。

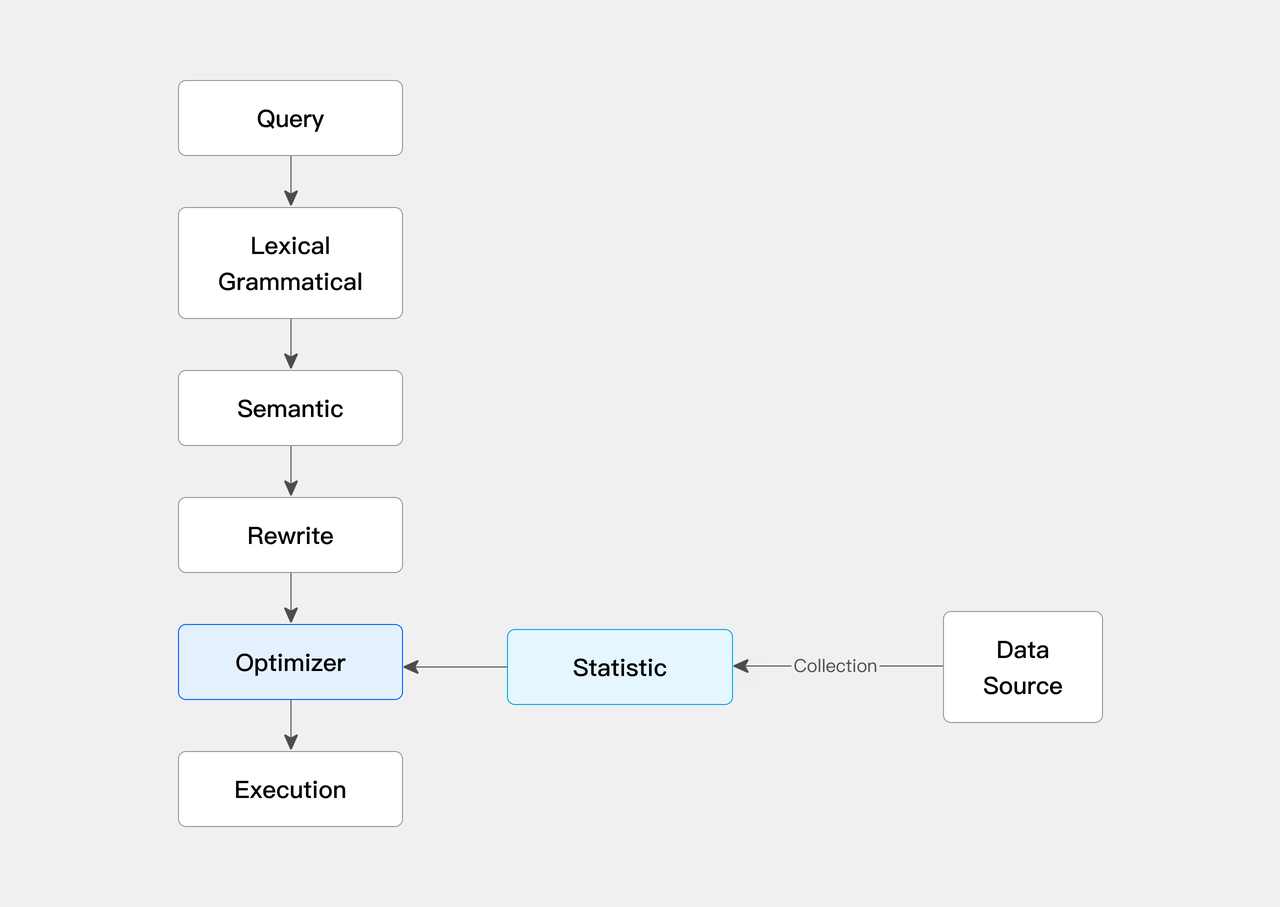
统计信息提高查询规划效果
Doris 通过收集统计信息有助于优化器了解数据分布特性,在进行 CBO(基于成本优化)时优化器会利用这些统计信息来计算谓词的选择性,并估算每个执行计划的成本。从而选择更优的计划以大幅提升查询效率。在数据湖场景我们可以通过收集外表的统计信息来提升查询规划器的效果。
统计信息的收集方式包括手动收集和自动收集。
同时为了保证收集统计信息不会对 BE 产生压力,我们支持了采样收集统计信息。
在一些场景下用户历史数据可能很少查找,但是热数据会被经常访问,因此我们也提供了基于分区的统计信息收集在保障热数据高效的查询效率和统计信息收集对 BE 产生负载的中间取得平衡。