
钱大妈是社区生鲜连锁品牌的开拓者,经过十一年的稳健运营,已成为行业内的领军品牌,截至 2023 年 7 月已全国布局超 30 多座城市,门店总数 3000 余家,服务家庭超 1000 万。近年来,随着业务的高速发展以及门店的快速扩张,钱大妈需要对生鲜产品的采购、销售、库存等数据进行实时监控和分析,以保障食品的新鲜度及品质。同时需要管理众多门店与供应链信息,以了解各区域销售趋势和顾客偏好,从而优化商品结构和库存管理。
在此背景下,钱大妈基于 Apache Doris 搭建了实时数仓,为业务用户提供实时精准的数据查询及分析服务。自引入 Apache Doris 后,钱大妈的报表和 BI 分析能力有了质的飞跃,能够轻松面对海量数据的处理,并实现秒级别的查询响应。凭借 Apache Doris 强大的性能,钱大妈能够实时监控生鲜产品的流通情况,为商品结构的优化和食品新鲜度的保障提供坚实的数据支撑。
读写分离需求背景
在当前的数据仓库架构中,从 ODS 层 - DWD 层 - DWS 层 - ADS 层的数仓分层均在 Apache Doris 内部构建,采用微批调度机制实现数据分层加工处理。随着业务的迅猛发展,需要存储和应用的数据规模愈加庞大,带来最明显的变化是数据写入规模与查询频次的急剧攀升,如果在执行调度任务的同时进行数据查询,可能出现系统资源抢占问题。一旦资源出现紧缺,将导致写入和查询任务性能下降,甚至出现任务失败或系统宕机,给集群稳定性带来影响。
因此,钱大妈考虑通过读写分离策略来解决这一问题。 具体而言,就是将经过高度加工处理的 ADS 层数据同步至另一个 Doris 集群,专供用户查询使用。这样不仅可以保证集群的稳定性,还能避免不规范的业务查询对数据导入和加工产生干扰。而读写分离方案的实现,就需要依赖跨集群数据复制能力。
早期方案
在之前版本中,由于备份恢复的方式难以保证数据的实时性和强一致性,因此我们决定借助 Doris 的多源数据目录 Multi-Catalog 来暂解燃眉之急。Multi-Catalog 核心能力旨在更便捷地对接外部多种数据源,提供跨源联邦查询的能力,尽管这并不是应对跨集群复制的最佳解决方案,但我们思考是否能巧借这一能力,间接实现集群间的复制。在这一思路指引下,我们通过编写脚本,利用 Catalog 方式实现增量数据的拉取,同步流程如下图所示:
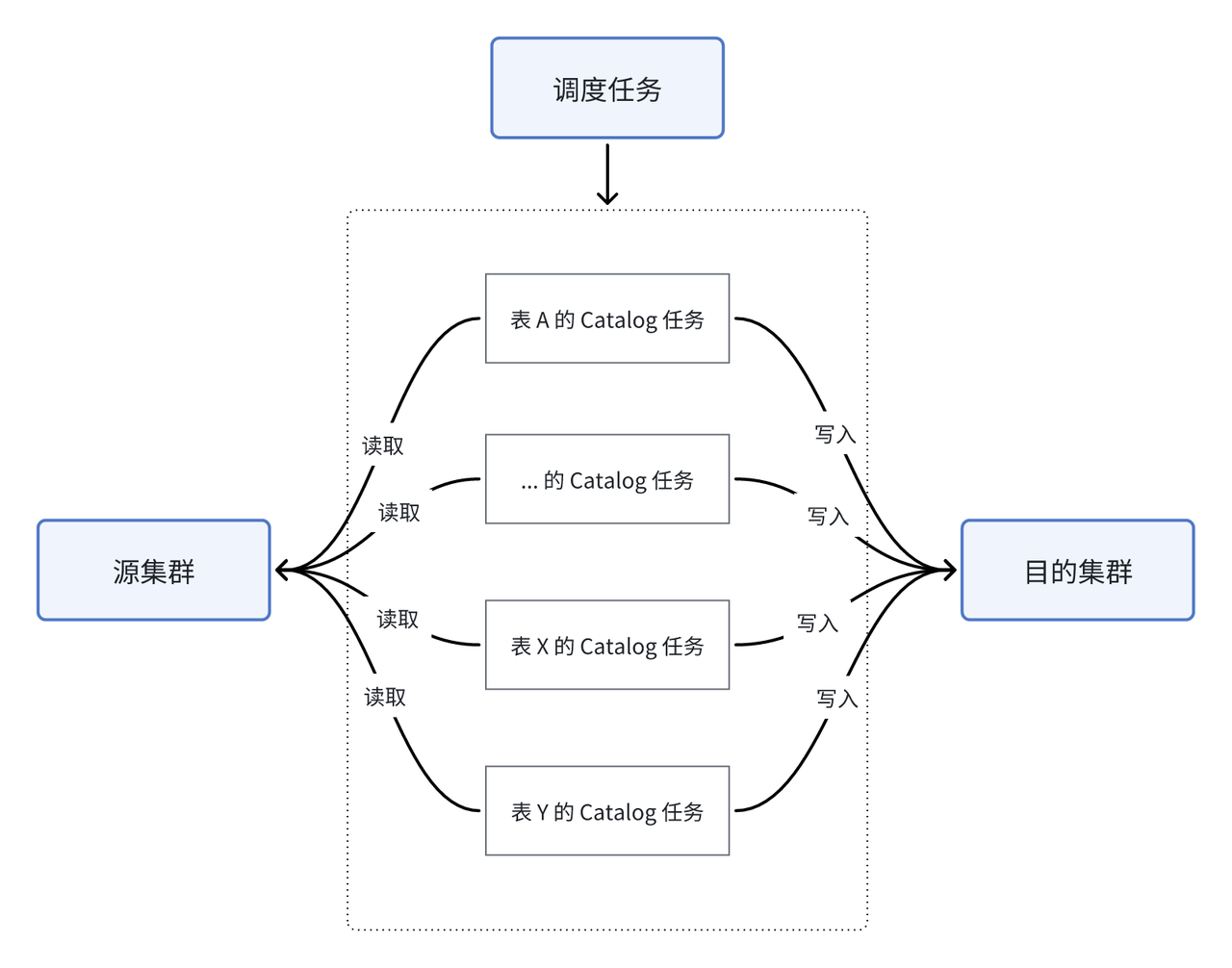
我们在目的集群中建立了多个源集群数据表的 Catalog,通过定期执行调度任务将源表中的数据导入进目的集群中,由于每次导入时无法自动识别增量数据,因此增加了最近更新时间这一字段来进行标识。由于数据时效性的保证依赖于外部调度任务的执行,因此目的集群中的数据表存在较高的时延、难以满足业务对数据实时性的需求。另一方面,每一张表的导入 SQL 都需要增加对最近更新时间的逻辑判断,一旦缺少判断则需要对整表进行删除后重新导入,这无疑增加了开发难度和数据出错率。
目标方案
为克服上述问题,钱大妈亟需寻找更为高效、便捷的解决方案,并期望新的方案可以满足以下要求:
- 实时数据同步时延需低于 2 秒。
- 具备完善监控及告警机制,对数据同步任务进行实时监控。当数据同步出现问题时,将立即触发告警,并通过企业微信、邮件等方式通知,以保障数据同步的稳定性。
- 完备的应急方案,当出现问题时可以在不影响查询的情况下快速恢复(如隐式表)
- 数据同步支持分区替换的命令,如
ALTER TABLE tbl1 REPLACE PARTITION
在这期间,钱大妈也尝试过其他解决方案,直到去年Apache Doris 在 2.0 版本中实现了跨集群复制(CCR)功能。在深入了解及调研后,决定选择这款轻量级工具,相对于外部集成其优势在于:
- 进程设计极其轻量级,数据同步任务进行时仅占用极少量的机器资源,能够在不影响系统整体性能的前提下,高效稳定地运行。
- 操作非常简单,用户只需通过一条 POST 请求即可完成配置,大大降低了用户的使用门槛,即使是非专业的技术人员也能快速上手。
- 数据迁移能力强,迁移能力的上限完全取决于Doris 集群的配置。用户可以根据实际需求对集群进行灵活配置,以达到最佳的迁移效果。
- 支持 DDL 同步,源集群执行的 DDL 语句可以自动同步到目标集群,从而保证了数据的一致性。
- 较高灵活性,用户也以根据需求灵活选择全量或者增量同步,为数据同步的提供了较好的灵活性。
最新方案
跨集群数据复制(CCR )的操作非常简单,只需在源集群和目标集群中开启 Binlog 即可启动进程,并将等待同步的库名或者表名发送给 CRR ,它便能够自动开始存量和增量数据的同步任务。流程图如下所示:
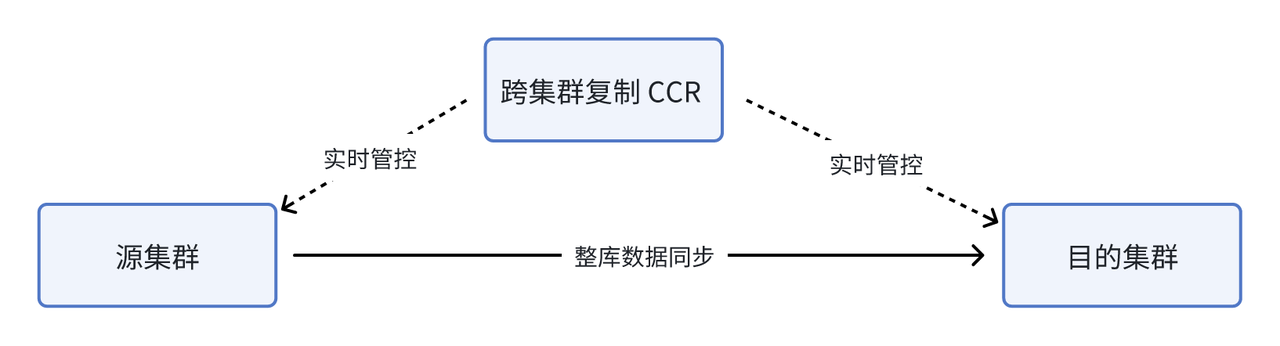
当前钱大妈选取了多张表进行表级别的数据同步,单表每天约有 5000 万的增量数据。经过一个月的试运行之后,同步任务表现稳定且性能优异,带来包括数据稳定性、数据准确性、研发效率和导入性能的全方位提升:
1. 稳定性与准确性。 同步任务运行平稳,使用至今暂未出现任务失败或数据无法同步的问题;数据准确性极大增强,确保了每一条数据都能准确无误地保存和传输。基于 CCR 成功实现了集群的读写分离,将读压力有效地迁移至只读集群,进一步提升了整个集群的稳定性。
2. 缩短同步流程,研发效率大幅提升。
在使用 CCR 之前:需要对每张表创建 SQL 以 Catalog 方式写入;对于没有
last_update_time的表,只能在目标集群删表后再全量同步。Insert into catalog1.db.destination_table_1 select * from catalog1.db.source_table1 where time > xxx Insert into catalog1.db.destination_table_2 select * from catalog1.db.source_table2 where time > xxx … Insert into catalog1.db.destination_table_x select * from catalog1.db.source_table_x ```在使用 CCR 过后,整库同步只需要一条
post请求,即可快速完成跨集群的数据同步:curl -X POST -H "Content-Type: application/json" -d '{ "name": "ccr_test", "src": { "host": "localhost", "port": "9030", "thrift_port": "9020", "user": "root", "password": "", "database": "demo", "table": "" }, "dest": { "host": "localhost", "port": "9030", "thrift_port": "9020", "user": "root", "password": "", "database": "ccrt", "table": "" } }' http://127.0.0.1:9190/create_ccr ```
3. 数据导入速率显著提升。 对于一整天数据的同步,使用 Catalog 方式则需要 30+ 秒同步完成,而使用 CCR 仅需要 3-4 秒即可同步完成。对于实时数据的同步,如果使用 Catalog 方式则依赖手动更新或定期调度,而使用 CCR 同步可以在 1 秒左右完成,实现亚秒级数据同步。
结束语
Apache Doris 跨集群复制(CCR) 功能的引入,为钱大妈带来了显著的收益。这一功能使得数据同步变得更为便捷高效,不仅大幅提升了数据同步的效率,同时增强了 Doris 集群的计算稳定性,为读写分离提供了更适配的解决方案。
随着 CCR 功能的不断完善和优化,钱大妈也将逐步将 ADS 以外的其他分层数据纳入同步范畴,实现更为广泛的数据整合与共享。并将基于CCR 功能在异地灾备、测试环境数据同步等场景进行应用,以提供更为安全可靠的使用体验,确保业务的稳定连续运行。
在此也欢迎有相关需求的同学积极反馈需求或问题,也可以通过下方二维码加入 CCR 专项支持群,我们将为您提供全面的技术支持和服务。



