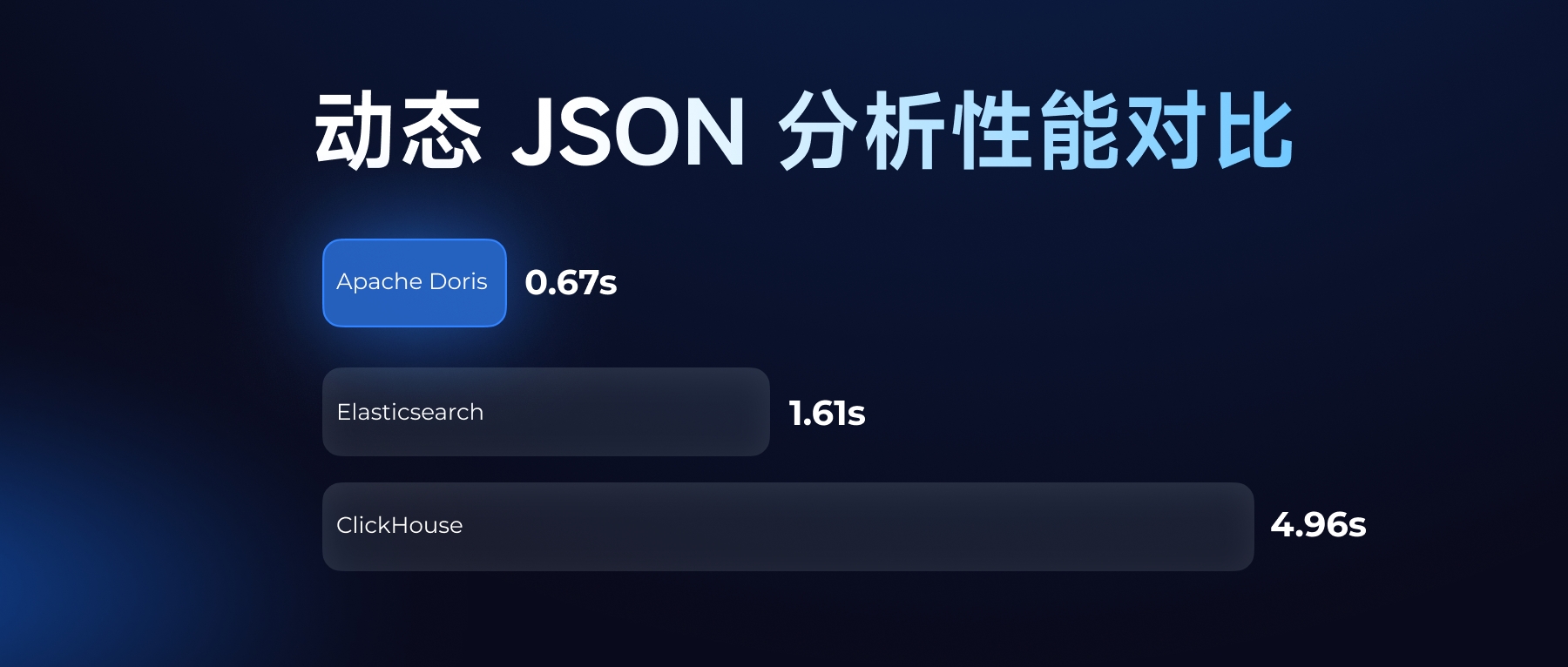
在过去一年,大模型能力的飞跃与推理成本的降低,使得 AI 不再是远期的概念,而成为企业当下必须拥抱的变革。几乎每一家企业都在积极探讨 AI、规划 AI 项目,寻找技术赋能业务的真实路径。在此背景下,Apache Doris 4.0 围绕 AI,系统性地引入并完善了一系列核心能力:
- 半结构化数据分析能力(Variant):轻松处理 JSON、XML 等灵活的数据类型
- 智能索引能力升级:
- 全文检索:内置
BM25算法,支持高性能关键词搜索与相关性排序,应对精确匹配场景。 - 向量检索: 集成
ANN算法索引,支持高维向量相似性搜索,实现基于语义的匹配。 - 混合检索与分析(Hybrid Search):可同时结合关键词、向量及结构化过滤进行查询,大幅提升召回率与准确度。
- 全文检索:内置
- AI 原生化:内置
AI Functions,可直接调用 Embedding 模型、大语言模型(LLM)等。 - 面向 Agent 的 MCP 交互能力:支持与 AI Agent 便捷且高效协同,使其成为智能体可信赖的数据与工具中枢。
这些能力相互协作,共同推动 Apache Doris 从被动存储分析,转向主动智能数据分析服务与洞察生成。
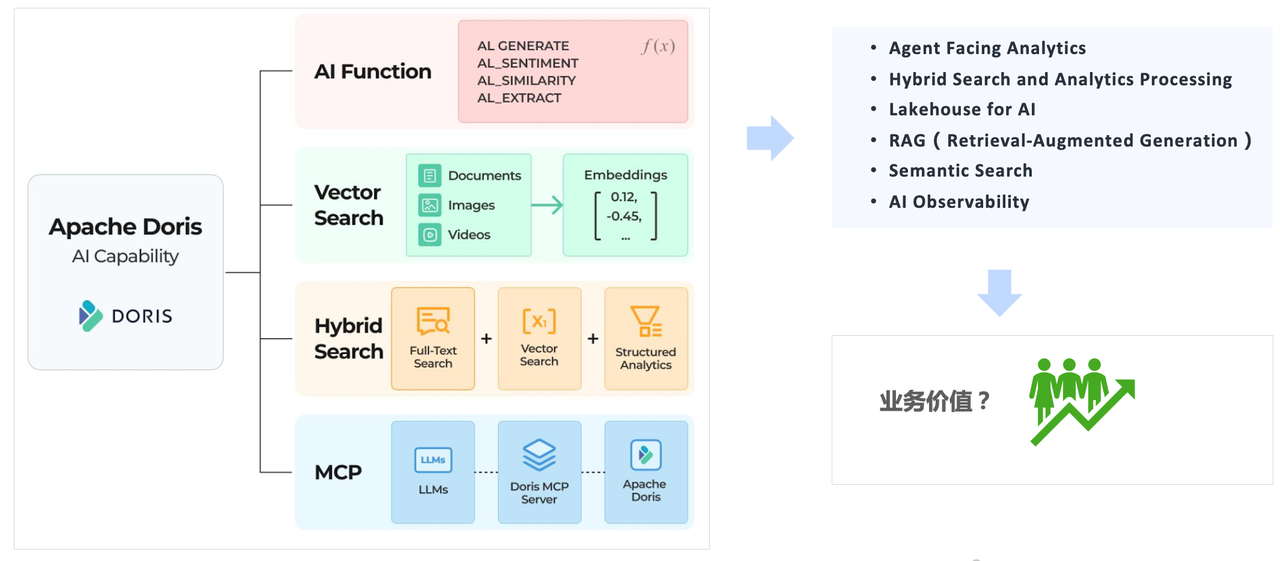 正因如此,Doris 吸引了众多探寻“Data + AI”可能性的新用户涌入尝试,也促使大量存量用户基于 Doris 4.0 率先探索,将 AI 能力应用于具体业务。其典型场景包括:
正因如此,Doris 吸引了众多探寻“Data + AI”可能性的新用户涌入尝试,也促使大量存量用户基于 Doris 4.0 率先探索,将 AI 能力应用于具体业务。其典型场景包括:
- 用户画像与行为分析:融合用户的结构化行为数据(点击、购买)与非结构化反馈(评论、客服对话),通过 AI 理解情绪与意图,自动关联行为异动与根本原因,实现从“看到现象”到“解释原因”的闭环。
- 智能风控与审计:在传统规则和指标风控基础上,引入交易备注、申诉文本等非结构化数据,通过语义分析识别潜在欺诈模式,将隐形的风险信号转化为可预警的规则。
- 制造与 IoT 预测性维护:关联设备时序传感器数据与维修日志文本,通过混合检索快速匹配历史故障案例,实现故障根因的智能定位与预测性维护建议。
- 产品反馈与洞察分析:汇聚来自论坛、工单、客服的分散用户反馈,通过 Doris + AI 将海量非结构化内容转化为可量化、可分析的产品洞察,驱动功能优化与决策。
SelectDB Cloud 和阿里云数据库 SelectDB 版均基于 Apache Doris 内核构建,全面继承了上述 Doris AI 能力。此外,两者均采用存算分离架构,支持弹性扩缩容,能够精准匹配业务流量波动,有效降低成本。同时,通过创建多个独立计算集群,可实现不同业务负载的隔离(如读写分离、离在线分析隔离),避免相互干扰,保障业务稳定性。
- SelectDB Cloud 不绑定特定云厂商,可在阿里云、华为云、AWS 等多个云平台上以 SaaS 模式部署,并支持 BYOC(自带云)模式,充分满足数据合规与成本控制需求。
- 阿里云瑶池数据库 SelectDB 版 作为阿里云原生服务,与 VPC、RAM 权限、监控等云服务无缝集成,提供类似在用户 VPC 内部署的网络体验,让用户享受更便捷的云端管理能力。
无论是寻求多云部署的灵活性,还是希望深度集成阿里云生态,两者都能为企业构建“Data + AI”应用提供坚实、高效的数据底座。
场景实战:基于 SelectDB + AI 的产品反馈洞察系统
那么,具体如何实现呢?在接下来的实战指南中,我们将以 SelectDB 产品经理的身份讲解。以“物化视图”这一功能为例,我们是如何借助 SelectDB + AI,搭建一个用于收集、整合与分析全域用户反馈的智能洞察系统。
用户对“物化视图”功能的反馈,常分散在论坛、工单等多个渠道,且大部分为非结构化数据,价值难以提炼。如果依赖人工阅读,效率低下。而利用 SelectDB + AI,我们可以构建一个自动化的智能洞察系统。
第一步:初始化
1. 新建 SelectDB Cloud 集群
前往 SelectDB 官网,选择专有仓库(SaaS)产品,该产品提供为期 14 天的免费试用:https://www.selectdb.com/download/cloud
根据页面引导新建 SelectDB Cloud 计算集群。
2. 创建表与原始数据同步
首先,在 SelectDB 中创建三张核心表,分别存储原始数据、向量化内容及 AI 解析结果。
A. 创建明细数据表
创建存储论坛数据的明细数据表,并对 content 字段添加了倒排索引,以支持全文检索和打分。
CREATE TABLE forum_questions (
question_id BIGINT, --问题ID
user_id BIGINT, --提问用户ID
title STRING, --标题
content STRING, --用户提问和回复的内容
INDEX idx_content (`content`) USING INVERTED PROPERTIES("lower_case" = "true", "parser" = "chinese", "support_phrase" = "true")
)
UNIQUE KEY(question_id)
DISTRIBUTED BY HASH(question_id) BUCKETS 2
PROPERTIES (
"replication_num" = "1"
);
B. 创建向量表
创建存储论坛问答的向量表,并对 embedding 字段创建了 ANN 索引,以支持向量检索。
CREATE TABLE forum_question_embeddings (
user_id BIGINT NOT NULL, -- 原问题所属用户
question_id BIGINT NOT NULL, -- 原问题ID
chunk_id BIGINT NOT NULL AUTO_INCREMENT, -- 文本切片 ID(每片对应一条向量)
content_chunk STRING NOT NULL, -- 文本切片内容
embedding array<float> NOT NULL, -- 1024维向量
INDEX ann_index (embedding) USING ANN PROPERTIES(
"index_type"="hnsw",
"metric_type"="inner_product",
"dim"="1024",
"quantizer"="flat"
)
)
DUPLICATE KEY(user_id, question_id, chunk_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 2
PROPERTIES (
"replication_num" = "1"
);
C. 创建结果表
该表主要用于:对 AI 函数对论坛问答的原始数据进行解析提取之后,存储结果的表。由于不同分析需求以及 AI 函数对文本解析的灵活性,其中的 parsed_data 使用了 Schema Free 的 VARIANT 数据类型。
CREATE TABLE parsed_results (
id BIGINT NOT NULL AUTO_INCREMENT, -- 主键ID
feedback_id BIGINT NOT NULL, -- 用户反馈ID(外键关联 forum_questions)
parsed_data VARIANT NOT NULL -- 解析结果(任意 JSON 数据)
)
UNIQUE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 2
PROPERTIES (
"replication_num" = "1"
);
3. AI 资源初始化
创建 Embedding 模型和大语言模型的资源,以便后续在 SQL 中使用。
CREATE RESOURCE "qwen-text-embedding-v4"
PROPERTIES (
'type' = 'ai',
'ai.provider_type' = 'QWen',
'ai.endpoint' = 'https://dashscope.aliyuncs.com/compatible-mode/v1',
'ai.model_name' = 'text-embedding-v4',
'ai.api_key' = 'xxx',
'ai.temperature' = '0.7',
'ai.max_token' = '1024',
'ai.max_retries' = '3',
'ai.retry_delay_second' = '1',
'ai.dimensions' = '1024'
);
CREATE RESOURCE "glm-4-flash-250414"
PROPERTIES (
'type' = 'ai',
'ai.provider_type' = 'QWen',
'ai.endpoint' = 'https://dashscope.aliyuncs.com/compatible-mode/v1',
'ai.model_name' = 'qwen-flash',
'ai.api_key' = 'xxx',
'ai.temperature' = '0.7',
'ai.max_token' = '-1',
'ai.max_retries' = '3',
'ai.retry_delay_second' = '1'
);
第二步:数据处理
1. Chunking & Embedding
在本示例中,我们采用了简单的定长切分策略,以每 400 字为一个文本片段进行 Embedding 与向量存储。当前方案仅为演示,未来 SelectDB 将通过支持 Python UDF 实现更灵活、更贴合业务场景的 Chunking。
WITH raw AS (
SELECT
question_id,
user_id,
content,
LENGTH(content) AS content_len
FROM forum_questions
),
t AS (
SELECT 0 AS d UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4
UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9
),
num AS (
SELECT
(a.d * 100 + b.d * 10 + c.d + 1) AS n
FROM t a
CROSS JOIN t b
CROSS JOIN t c
),
chunks AS (
SELECT
r.user_id,
r.question_id,
SUBSTRING(r.content, (n - 1) * 400 + 1, 400) AS content_chunk
FROM raw r
JOIN num ON (n - 1) * 400 + 1 <= r.content_len
)
INSERT INTO forum_question_embeddings (user_id, question_id, content_chunk, embedding)
SELECT
user_id,
question_id,
content_chunk,
EMBED("qwen-text-embedding-v4", content_chunk) AS embedding
FROM chunks;
2. 关键信息 AI 提取
利用 AI Function 提取用户反馈中的关键信息,并以 Variant 类型存储。
SET @extract_prompt = "你是一名专业的产品反馈分析助手。现提供一段来自用户的反馈文本(feedback_text),请从中提取与“物化视图(Materialized View, MV)”相关的关键信息,并以严格的 JSON 格式输出。
如果反馈文本与 MV 无关,或无法识别任何相关信息,则直接返回字符串 NULL。
请从 feedback_text 中提取以下信息并生成 JSON:
{
\"used_external_source\": \"用户是否提到使用了哪些外部数据源,例如 MySQL、Oracle、Hive、Iceberg 等。如果未提及则为 null。\",
\"transparent_rewrite\": \"是否使用或提到透明改写(true / false / null)。\",
\"usage_scenario\": \"用户描述的使用场景。若无则为 null。\",
\"problems_or_gaps\": \"用户认为 MV 不足或存在的问题。若无则为 null。\",
\"other_insights\": \"任何与 MV 相关、对产品改进有价值的额外信息。若无则为 null。\"
}
要求:
1. 输出内容必须是纯 JSON,对象必须以 { 开头、以 } 结尾。
2. 禁止输出任何 Markdown 代码块标记,如 json、、json、``` 等。
3. 禁止输出任何额外文字、描述、解释、前缀或后缀。
4. 不得在 JSON 外输出换行、空格或注释。";
INSERT INTO parsed_results (feedback_id, parsed_data)
SELECT
question_id,
AI_GENERATE(
'glm-4-flash-250414',
concat(@extract_prompt ,'\nfeedback_text: ```' ,content, '```')
) AS extracted_info
FROM forum_questions where search('content:物化视图');
第三步:混合检索与分析
当数据准备就绪后,便可针对具体产品问题展开检索分析。
示例 A:
我们将对该问题进行检索分析:物化视图功能中,用户最常使用哪些外部数据源,分别有多少用户反馈?
如下代码所示,直接对上一步中反馈结果的解析表进行聚合分析。
SELECT
lower(CAST(c.used_external_source AS string)) AS used_external_source,
COUNT(*)
FROM (
SELECT
a.parsed_data.usage_scenario,
a.parsed_data.transparent_rewrite,
a.parsed_data.used_external_source AS used_external_source,
a.parsed_data.problems_or_gaps,
a.parsed_data.other_insights,
b.content
FROM parsed_results a
JOIN forum_questions b ON a.feedback_id = b.question_id
WHERE a.parsed_data.used_external_source != ""
AND a.parsed_data.used_external_source != "null"
) c
GROUP BY lower(CAST(c.used_external_source AS string));
示例 B:
我们将对该问题进行检索分析:有多少用户提到了数据时效性的痛点或需求,他们都使用了什么数据源?
为了回答这个问题,我们需要结合关键词匹配和语义搜索,检索出有“数据时效性的痛点或需求”的用户,然后对这些用户进行聚合分析,代码如下所示。
--向量检索文本
SET @search_text="数据时效性差、 ETL 延迟、物化视图刷新不及时、数据不实时、实时查询不满足业务、报表延迟、同步滞后、时延高、更新慢、不能满足实时监控需求、数据落地慢、数据延时影响决策";
--存储有"数据时效性的痛点或需求"的用户的临时表
CREATE TEMPORARY TABLE retrieved_question_ids (
question_id BIGINT
)
UNIQUE KEY(question_id)
DISTRIBUTED BY HASH(question_id) BUCKETS 2
PROPERTIES (
"replication_num" = "1"
);
insert into retrieved_question_ids(question_id)
SELECT question_id --向量检索
FROM forum_question_embeddings
where inner_product_approximate(
embedding,
EMBED("qwen-text-embedding-v4", @search_text)
) > 0.5
union ALL
select a.question_id from
(
SELECT question_id,score() as relevance --全文检索
FROM forum_questions
where content MATCH_ANY '时效性 实时 延迟 延时 更新不及时 刷新慢 滞后'
ORDER BY relevance DESC
LIMIT 100
)a;
SELECT
lower(CAST(c.used_external_source AS STRING)) AS used_external_source,
COUNT(DISTINCT c.question_id) AS feedback_cnt
FROM (
SELECT
a.feedback_id AS question_id,
a.parsed_data.used_external_source AS used_external_source
FROM parsed_results a
JOIN retrieved_question_ids r
ON a.feedback_id = r.question_id
WHERE a.parsed_data.used_external_source IS NOT NULL
AND a.parsed_data.used_external_source != ""
AND lower(a.parsed_data.used_external_source) != "null"
) c
GROUP BY lower(CAST(c.used_external_source AS STRING))
ORDER BY feedback_cnt DESC;
通过以上步骤,一个能够自动处理非结构化反馈、并支持智能问答式分析的洞察系统便搭建完成。这套方法不仅适用于产品反馈,也可平移到客服质检、舆情分析、风控线索挖掘等众多需要理解文本的领域。
结束语
当我们把目光从用户反馈扩展到更广泛的企业数据,我们发现,几乎所有成熟的业务分析系统,都天然伴随着大量非结构化数据。只是长期以来,这些数据并未被系统性纳入分析体系,更多停留在“可存储、不可分析”的状态。
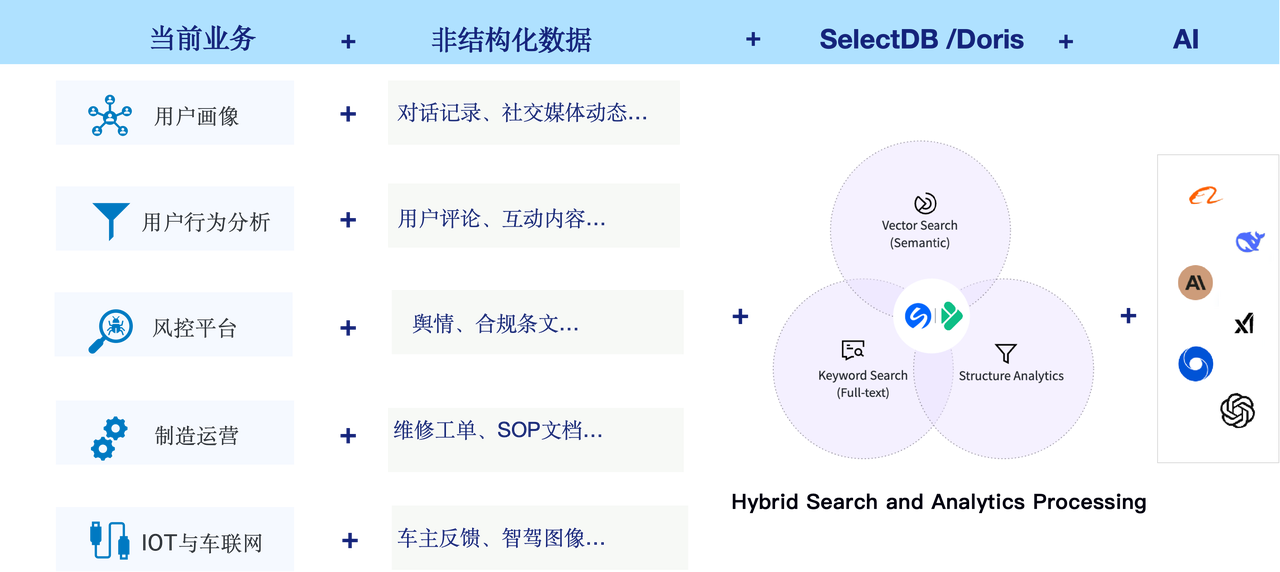
我们所做的,正是通过 HSAP 能力在一个统一平台中融合实时分析、智能检索与 AI 推理能力,唤醒这些数据资产的价值。这并非简单地引入 AI,而是让企业已有的数据基础能够自然、平滑地智能化升级,让数据真正成为驱动业务决策的核心力量。
我们欢迎您基于文中的案例开始探索,让 SelectDB / Apache Doris 成为您业务智能化进程中统一、高效的数据基座。