
引言
在上一篇文章《Apache Doris 4.0 AI 能力揭秘(一):AI 函数之 LLM 函数介绍》中,我们介绍了 Apache Doris 4.0 如何通过原生集成 LLM 函数,将大语言模型的强大能力引入 SQL 分析场景,实现文本处理的智能化与内部分析的无缝化。这一能力不仅拓展了数据库的边界,也为数据密集型业务注入了全新的智能维度。
然而,技术能力的落地并不止于功能实现,真正的价值在于其在企业复杂场景中的稳定、高效与可管理的实践。随着 AI 函数在更多业务线中使用,如何将其从“可用”推进到“好用”、“可控”、“可规模化”,成为企业级应用的关键挑战。 在本篇文章中,我们将深入探讨在真实生产环境中应用 AI 函数的核心考量:Apache Doris LLM Function 的技术架构、核心功能特性、典型应用场景及性能优化策略,为相关技术实践提供参考。
LLM Function 核心价值
在传统的企业级数据分析架构中,文本数据的 AI 处理通常采用分离式模式:数据从数据库导出,应用层调用外部 AI API 进行处理,然后将结果写回数据库。这种架构模式在实际生产环境中面临数据一致性难以保障、性能瓶颈、运维复杂等挑战。Apache Doris LLM Function 通过将大语言模型能力原生集成到 SQL 执行引擎中,从根本上解决了传统架构的痛点,最显著的优势在于实现了事务一致性保障:AI 分析和数据操作在同一个 SQL 事务中完成,对于金融风控、订单处理等对数据一致性要求极高的场景而言,带来了至关重要的提升。
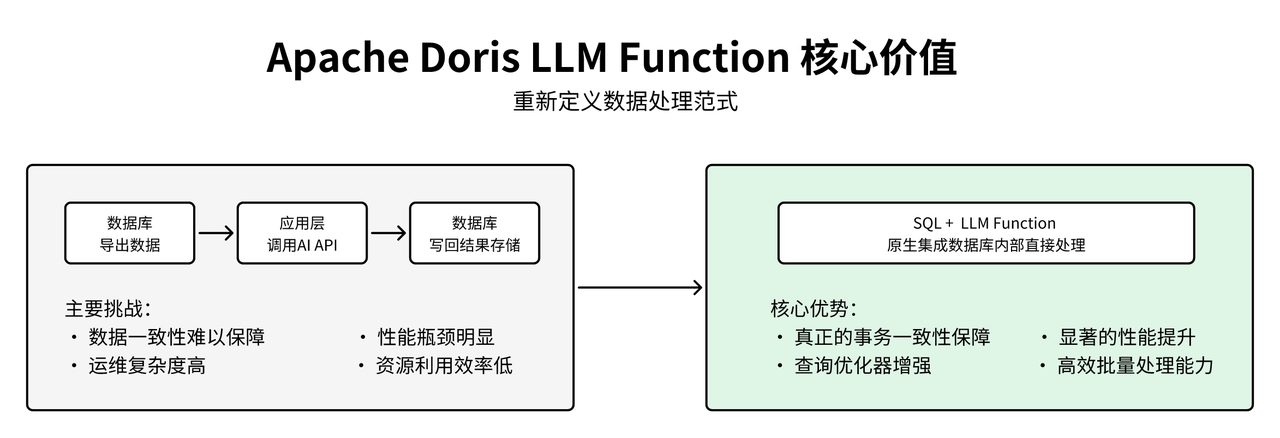
LLM Function 在性能上展现出显著优势:通过将 AI 处理内置于数据库中,省去数据导出导入环节,大幅降低网络与传输开销,使处理时间从分钟级缩短至毫秒级,显著提升实时决策效率。此外,Apache Doris 查询优化器可对包含 LLM 函数的 SQL 进行整体优化,支持并行执行、顺序调度与缓存复用,结合 SQL 的批量处理能力,有效避免了逐条调用外部 API 的性能瓶颈,实现高效、可扩展的智能分析。
数据库原生 AI 能力
01 技术架构设计思路深度解析
Apache Doris LLM Function 的设计理念体现了现代数据库架构演进的重要趋势:将 AI 能力深度集成到数据处理引擎的核心。这种设计思路与传统的“数据导出 - 外部处理 - 结果回流”模式形成鲜明对比,代表了一种更加高效、一体化的技术路径。
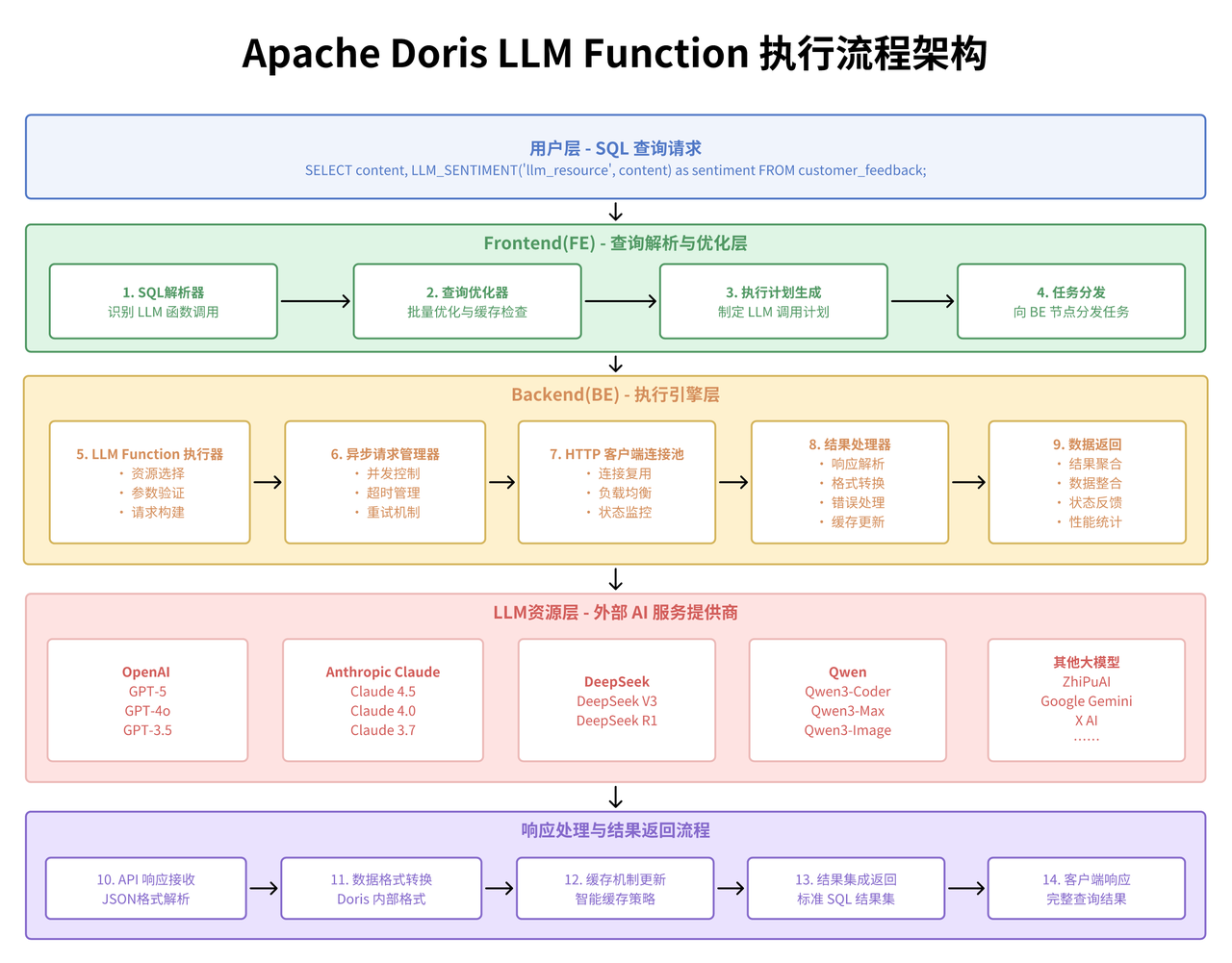
从架构层面来看,LLM Function 采用了资源池化管理的设计模式。通过 CREATE RESOURCE 语句建立的 LLM 资源池,实现了对不同 AI 服务提供商(OpenAI、Anthropic、Gemini 等)的统一管理和动态调用。这种设计的技术优势在于:首先是接口标准化,不同的 LLM 提供商通过统一的资源接口进行管理,避免了业务代码与具体 AI 服务的强耦合;其次是负载均衡****能力,可以根据不同的业务场景和性能要求,灵活选择最适合的 LLM 资源;最后是故障隔离机制,单个 LLM 服务的异常不会影响到整个数据分析流程的稳定性。
在具体的技术实现上,LLM Function 的核心价值体现在其 SQL 原生集成能力。传统的文本分析流程通常需要将数据从数据库中导出,通过外部程序调用 AI 接口,然后将结果写回数据库。这个过程不仅涉及复杂的数据流转,还存在数据一致性、事务管理、性能瓶颈等多个技术挑战。而 LLM Function 通过将 AI 调用能力直接嵌入到 SQL 执行引擎中,实现了数据处理和 AI 分析的无缝融合。
从数据库引擎的角度来看,LLM Function 的实现涉及了多个关键技术层面。在查询优化器层面,需要对包含 LLM 函数的查询进行特殊的优化处理,包括合理的执行顺序安排、批量调用优化、缓存策略等。在执行引擎层面,需要处理异步 API 调用、超时管理、错误重试等复杂逻辑。在资源管理层面,需要实现对外部 API 调用的配额控制、并发限制、成本监控等功能。
02 AI 函数功能详解
Apache Doris 提供的 10 个 LLM 函数覆盖了文本处理的主要应用场景,每个函数都有其特定的技术特点和最佳适用场景。
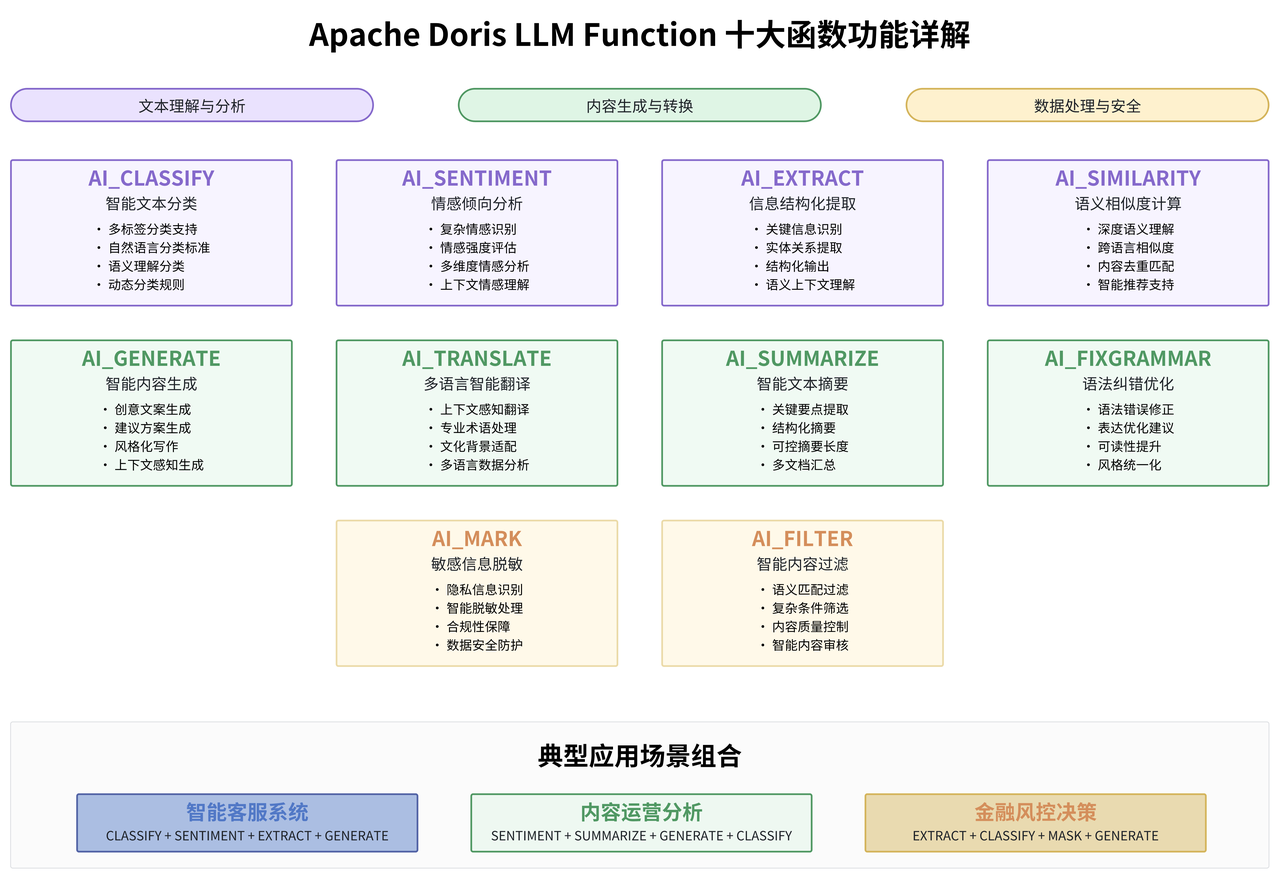
AI_CLASSIFY 函数 是文本分类场景的核心工具:
在技术实现上,该函数接受文本内容和分类标签作为参数,通过大语言模型的理解能力进行智能分类。与传统的机器学习分类方法相比,AI_CLASSIFY 的最大优势在于无需预训练和特征工程,可以通过自然语言描述的分类标准直接进行分类。在电商平台的用户评价分析中,传统的方法可能需要预先定义大量的关键词规则或训练专门的分类模型,而 AI_CLASSIFY 可以通过语义理解,对复杂的用户反馈进行精准分类。
-- AI_CLASSIFY多维度分类示例 SELECT feedback_id, content, AI_CLASSIFY('primary_llm', content, '产品质量,物流服务,客户服务') as category, AI_CLASSIFY('primary_llm', content, '紧急,重要,普通') as priority FROM user_feedback WHERE create_time >= CURRENT_DATE - INTERVAL 1 DAY;AI_SENTIMENT 函数提供了比传统情感分析更加细腻的情感识别能力:
传统的情感分析主要基于词汇情感词典或简单的机器学习模型,往往只能识别基本的正面、负面、中性情感,而且容易被表面的情感词汇误导。AI_SENTIMENT 通过深度的语义理解,能够识别复杂的情感表达,包括讽刺、反语、多重情感等复杂情况。比如"虽然价格有点贵,但是确实物有所值"这样的表述,传统的情感分析可能会因为"贵"这个词而判断为负面,但 AI_SENTIMENT 能够理解整体的正面倾向。
-- AI_SENTIMENT情感分析示例 SELECT review_id, review_text, AI_SENTIMENT('primary_llm', review_text) as sentiment, AI_EXTRACT('primary_llm', review_text, '提取关键问题点') as key_issues FROM product_reviews WHERE review_date >= CURRENT_DATE - INTERVAL 7 DAY;AI_EXTRACT 函数在信息提取场景中展现出了强大的结构化能力:
该函数能够从非结构化的文本中提取特定的信息实体,其技术优势在于能够理解语义上下文,准确识别和提取关键信息。传统的正则表达式提取在面对复杂的非结构化文本时往往力不从心,特别是当目标信息以不同的表达方式出现时。而 AI_EXTRACT 通过大语言模型的语义理解能力,可以识别同一概念的不同表达方式,大大提升了信息提取的准确性和覆盖面。
AI_GENERATE 函数是创意性文本生成的强大工具: 该函数可以基于给定的上下文和要求,生成符合特定风格和内容要求的文本。在实际应用中,这个功能可以用于自动生成产品描述、客服回复模板、营销文案等多种场景。与传统的模板化生成不同,AI_GENERATE 能够根据具体的上下文信息,生成更加个性化和相关性更强的内容。
AI_TRANSLATE 函数提供了高质量的多语言翻译能力: 与传统的机器翻译相比,基于大语言模型的翻译能够更好地理解上下文和语言的细微差别,产生更加自然和准确的翻译结果。这对于跨国企业的多语言数据分析具有重要价值。
AI_SUMMARIZE 函数可以对长文本进行智能摘要: 该函数能够理解文本的主要内容和结构,提取关键信息并生成简洁的摘要。在处理大量文档、新闻文章、用户反馈等场景中,该功能可以大大提高信息处理的效率。
AI_SIMILARITY 函数在文本相似度计算方面具有强大的语义理解能力: 传统的相似度计算主要基于词汇重叠(如余弦相似度、Jaccard 相似度)或者简单的向量距离,这些方法往往无法捕捉语义层面的相似性。AI_SIMILARITY 通过大语言模型的语义表示能力,能够识别表达方式不同但语义相近的文本,在内容去重、相似问题匹配、推荐系统等场景中具有重要应用价值。
AI_FIXGRAMMAR 函数专注于文本的语法纠错和优化: 该函数不仅能够识别和修正语法错误,还能够改善文本的表达方式和可读性。这在处理用户生成内容、文档质量改进等场景中具有重要应用。
AI_MASK 函数提供了智能化的敏感信息脱敏能力: 该函数能够识别文本中的敏感信息(如个人身份信息、财务数据等),并进行适当的脱敏处理,这在数据安全和隐私保护方面具有重要价值。
AI_FILTER 函数可以根据指定的条件对文本进行智能过滤: 该函数能够理解复杂的过滤条件,并根据语义匹配进行文本筛选,在内容审核、质量控制等场景中具有重要应用。
03 资源管理和配置实践深解
LLM Function 的资源管理机制是其技术架构的核心组成部分,理解和掌握资源配置的最佳实践对于系统的稳定运行至关重要。
在生产环境中,LLM 资源的配置需要考虑多个关键因素。首先是 API 配额管理,不同的 LLM 服务提供商都有各自的调用频率限制和计费模式。OpenAI 的 GPT 系列模型按照 token 数量计费,每分钟有调用次数限制;Anthropic 的 Claude 系列有类似的限制机制;而 Google 的 Gemini 系列又有不同的配额策略。在配置资源时,需要根据业务的实际调用量和预算情况,合理选择服务提供商和模型类型。
-- 创建生产环境的分层LLM资源配置
CREATE RESOURCE "high_performance_llm" PROPERTIES (
'type' = 'llm',
'llm.provider_type' = 'openai',
'llm.model_name' = 'gpt-4',
'llm.api_key' = '${OPENAI_API_KEY}',
'llm.max_tokens' = '2000',
'llm.temperature' = '0.3',
'llm.retry_times' = '3'
);
CREATE RESOURCE "cost_effective_llm" PROPERTIES (
'type' = 'llm',
'llm.provider_type' = 'openai',
'llm.model_name' = 'gpt-3.5-turbo',
'llm.api_key' = '${OPENAI_API_KEY}',
'llm.max_tokens' = '1000',
'llm.temperature' = '0.1'
);
在资源选择策略上,Apache Doris 提供了两种方式:显式指定和默认资源设置。在实际项目中,建议根据不同的业务场景采用不同的策略。对于批量处理场景,可以使用 SET default_AI_resource 设置默认资源,简化 SQL 语句的编写;对于实时查询场景,建议在函数调用中显式指定资源,确保调用的确定性和可控性。
-- 设置默认资源并进行智能资源选择
SET default_AI_resource = 'cost_effective_llm';
-- 根据任务复杂度智能选择资源
SELECT
customer_id,
feedback_text,
CASE
WHEN LENGTH(feedback_text) > 500 OR feedback_text LIKE '%复杂%'
THEN AI_SENTIMENT('high_performance_llm', feedback_text)
ELSE AI_SENTIMENT(feedback_text) -- 使用默认资源
END as sentiment_analysis
FROM customer_feedback
WHERE create_time >= CURRENT_DATE - INTERVAL 1 DAY;
资源的性能调优也是生产环境部署的重要考虑因素。max_tokens 参数直接影响 API 调用的成本和响应时间,需要根据具体的文本处理需求进行调整。对于简单的分类和情感分析任务,通常 500-1000 个 token 就足够了;对于复杂的信息提取和文本生成任务,可能需要 2000 个或更多的 token。temperature 参数控制 AI 模型输出的随机性,对于需要确定性结果的分类和提取任务,建议设置较低的 temperature 值(0.1-0.3);对于创意性的文本生成任务,可以适当提高 temperature 值(0.7-0.9)。
LLM Function 深度应用场景实践
01 智能客户服务系统
在现代企业的客户服务体系中,海量的客户反馈、咨询和投诉信息的处理一直是一个技术挑战。传统的人工处理方式效率低下,而简单的关键词匹配又难以准确理解客户的真实意图。通过 Apache Doris LLM Function,我们可以构建一个高度智能化的客户服务分析系统。
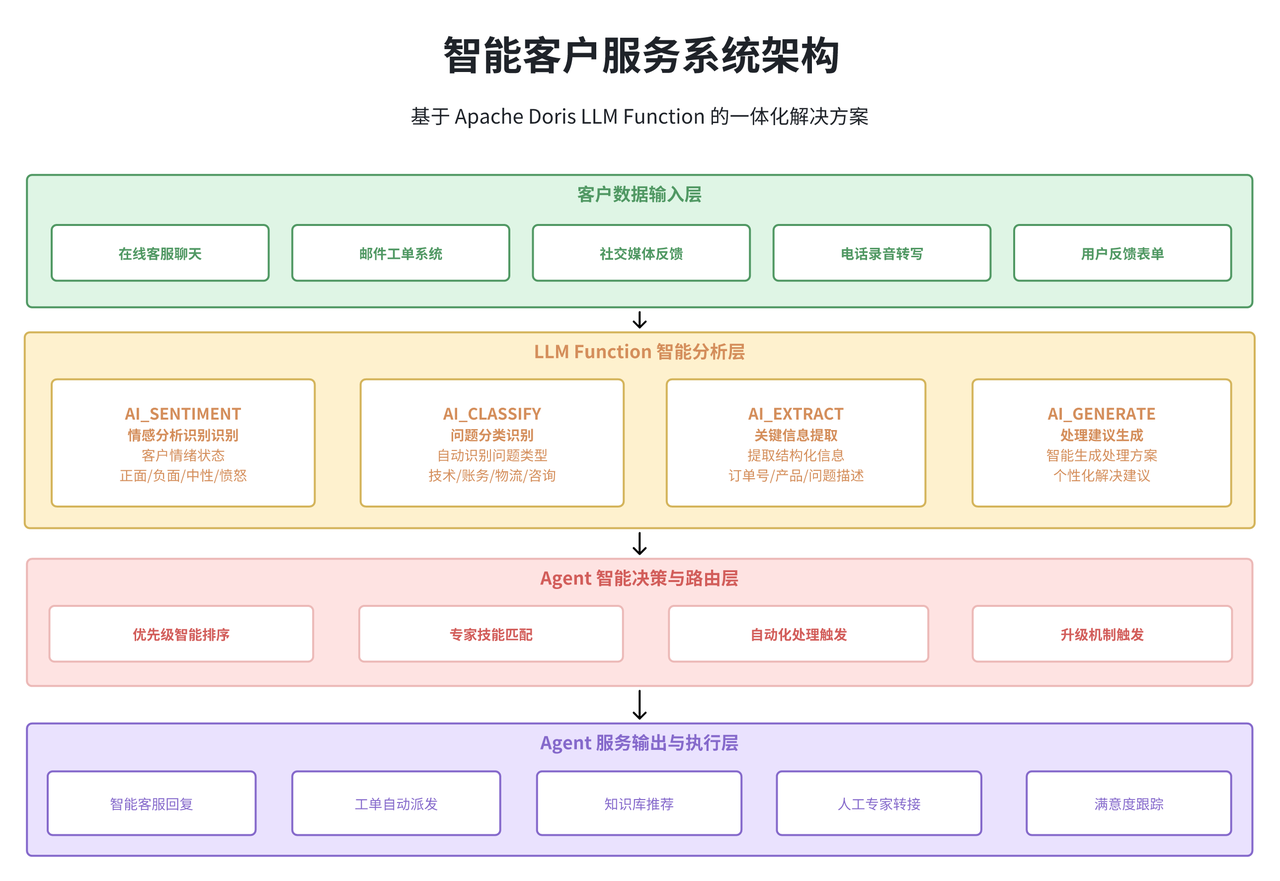
系统的核心价值在于能够在数据处理的同时完成 AI 分析,避免了传统方案中数据在不同系统间流转带来的性能损耗和一致性问题。通过 SQL 原生的 AI 能力,客服团队可以实时获得智能化的分析结果,大大提升处理效率和服务质量。
-- 智能客户服务综合分析系统
WITH customer_analysis AS (
SELECT
ticket_id,
customer_id,
content,
create_time,
-- 情感分析:识别客户情绪状态
AI_SENTIMENT('primary_llm', content) as sentiment_score,
-- 问题分类:自动识别问题类型
AI_CLASSIFY('primary_llm', content,
'技术故障,账务问题,物流查询,产品咨询,投诉建议') as issue_category,
-- 关键信息提取:自动提取结构化信息
AI_EXTRACT('primary_llm', content,
'提取订单号、产品名称、问题描述、期望解决方案') as key_info,
-- 紧急程度评估:确定处理优先级
AI_CLASSIFY('primary_llm', content, '紧急,重要,普通,低优先级') as priority_level
FROM customer_service_tickets
WHERE create_time >= CURRENT_DATE - INTERVAL 1 DAY
AND status IN ('new', 'in_progress')
)
SELECT
ca.*,
-- 生成处理建议
AI_GENERATE('primary_llm',
CONCAT('基于客户问题分析,生成专业的处理建议:',
'问题类型:', ca.issue_category,
',客户情绪:', ca.sentiment_score,
',关键信息:', ca.key_info),
300) as processing_suggestion
FROM customer_analysis ca
ORDER BY
CASE ca.priority_level
WHEN '紧急' THEN 1
WHEN '重要' THEN 2
WHEN '普通' THEN 3
ELSE 4
END,
ca.create_time DESC;
在实际的生产环境部署中,这类分析查询通常会被封装成视图或者存储过程,供客服管理系统调用。系统可以实时展示智能分析结果,帮助客服代表快速理解客户问题、制定处理策略、提供个性化服务。
02 内容运营智能化分析平台
对于内容驱动的企业(如电商平台、媒体公司、在线教育等),内容质量和用户反馈的分析是业务优化的关键环节。传统的内容分析往往依赖于简单的统计指标(如点击量、评论数等),难以深入理解内容的实际质量和用户的真实反馈。
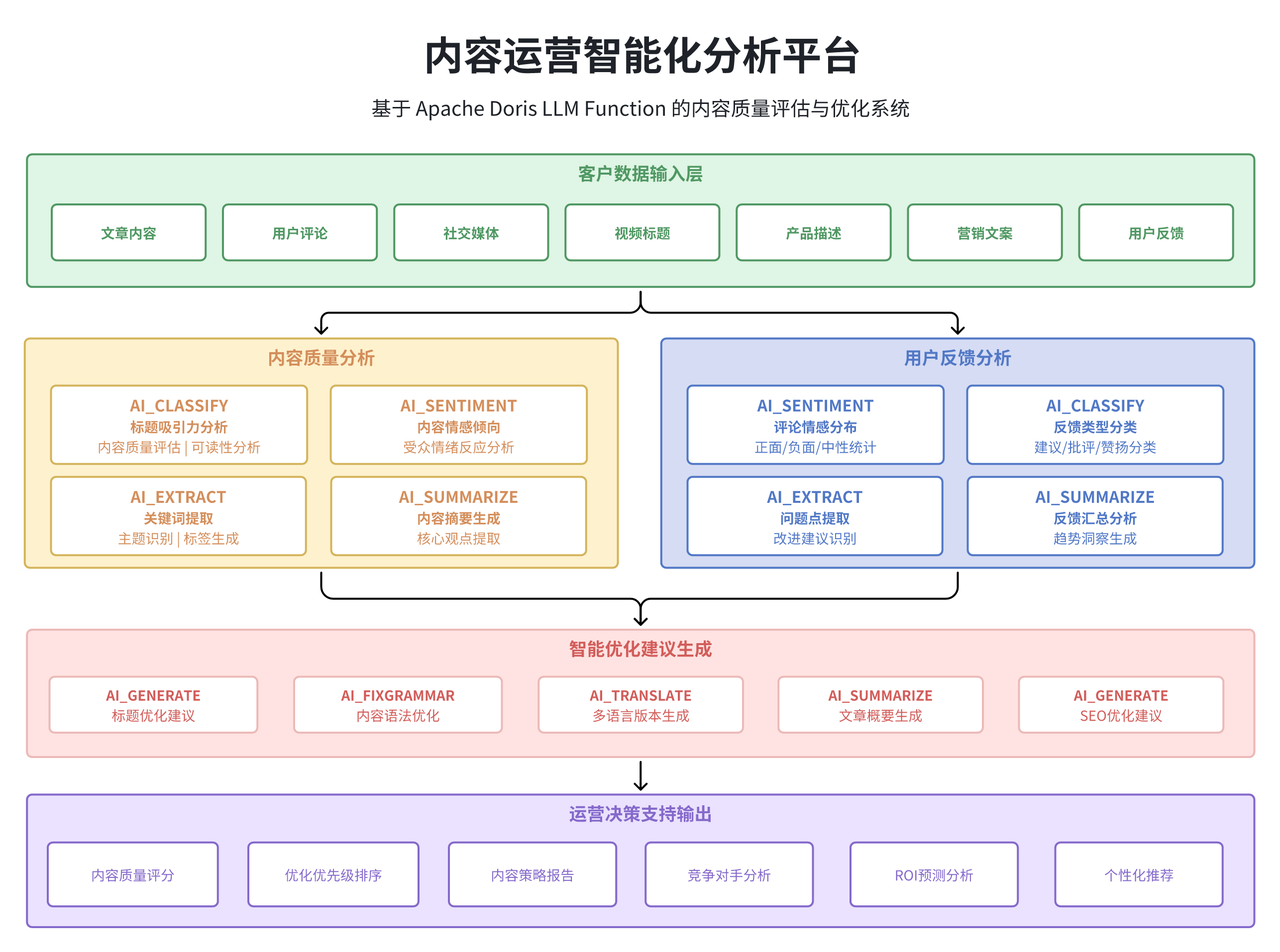
通过 Apache Doris LLM Function,我们可以构建一个深度的内容智能分析平台。这个平台不仅能够分析内容的基础数据,还能理解内容的语义质量、用户反馈的情感倾向,甚至可以自动生成内容优化建议。
-- 内容运营智能分析平台
WITH content_analysis AS (
SELECT
c.content_id,
c.title,
c.author_id,
c.publish_time,
c.view_count,
c.comment_count,
-- 标题质量分析
AI_CLASSIFY('primary_llm', c.title,
'高吸引力,中等吸引力,低吸引力') as title_appeal,
-- 内容质量评估
AI_CLASSIFY('primary_llm', SUBSTRING(c.content, 1, 1000),
'优质内容,良好内容,普通内容,低质内容') as content_quality,
-- 可读性评估
AI_CLASSIFY('primary_llm', SUBSTRING(c.content, 1, 1000),
'易读,中等,困难') as readability_level
FROM content_posts c
WHERE c.publish_time >= CURRENT_DATE - INTERVAL 7 DAY
AND c.status = 'published'
),
user_feedback_analysis AS (
SELECT
uc.content_id,
COUNT(*) as total_comments,
-- 用户评论情感分布统计
SUM(CASE WHEN AI_SENTIMENT('cost_effective_llm', uc.comment_text) LIKE '%正面%'
THEN 1 ELSE 0 END) as positive_comments,
SUM(CASE WHEN AI_SENTIMENT('cost_effective_llm', uc.comment_text) LIKE '%负面%'
THEN 1 ELSE 0 END) as negative_comments,
-- 用户建议汇总
AI_SUMMARIZE('primary_llm',
GROUP_CONCAT(CASE WHEN AI_CLASSIFY('cost_effective_llm', uc.comment_text, '建议,批评,赞扬') = '建议'
THEN uc.comment_text ELSE NULL END SEPARATOR ' | '),
200) as user_suggestions
FROM user_comments uc
WHERE uc.create_time >= CURRENT_DATE - INTERVAL 7 DAY
GROUP BY uc.content_id
)
SELECT
ca.*,
ufa.total_comments,
ufa.positive_comments,
ufa.negative_comments,
ROUND(ufa.positive_comments * 100.0 / NULLIF(ufa.total_comments, 0), 2) as positive_ratio,
ufa.user_suggestions,
-- 生成优化建议
AI_GENERATE('primary_llm',
CONCAT('基于内容分析数据,提供具体的优化建议:',
'标题吸引力:', ca.title_appeal,
',内容质量:', ca.content_quality,
',用户建议:', COALESCE(ufa.user_suggestions, '暂无')),
300) as optimization_suggestions
FROM content_analysis ca
LEFT JOIN user_feedback_analysis ufa ON ca.content_id = ufa.content_id
ORDER BY
CASE ca.content_quality
WHEN '优质内容' THEN 1
WHEN '良好内容' THEN 2
WHEN '普通内容' THEN 3
ELSE 4
END,
ca.view_count DESC;
03 金融风控智能决策系统
金融行业的风险控制一直是数据分析技术应用的重要领域。传统的风控模型主要基于结构化数据(如交易金额、频次、地理位置等),而对于非结构化的文本数据(如客户描述、申请材料、通话记录等)的利用相对有限。
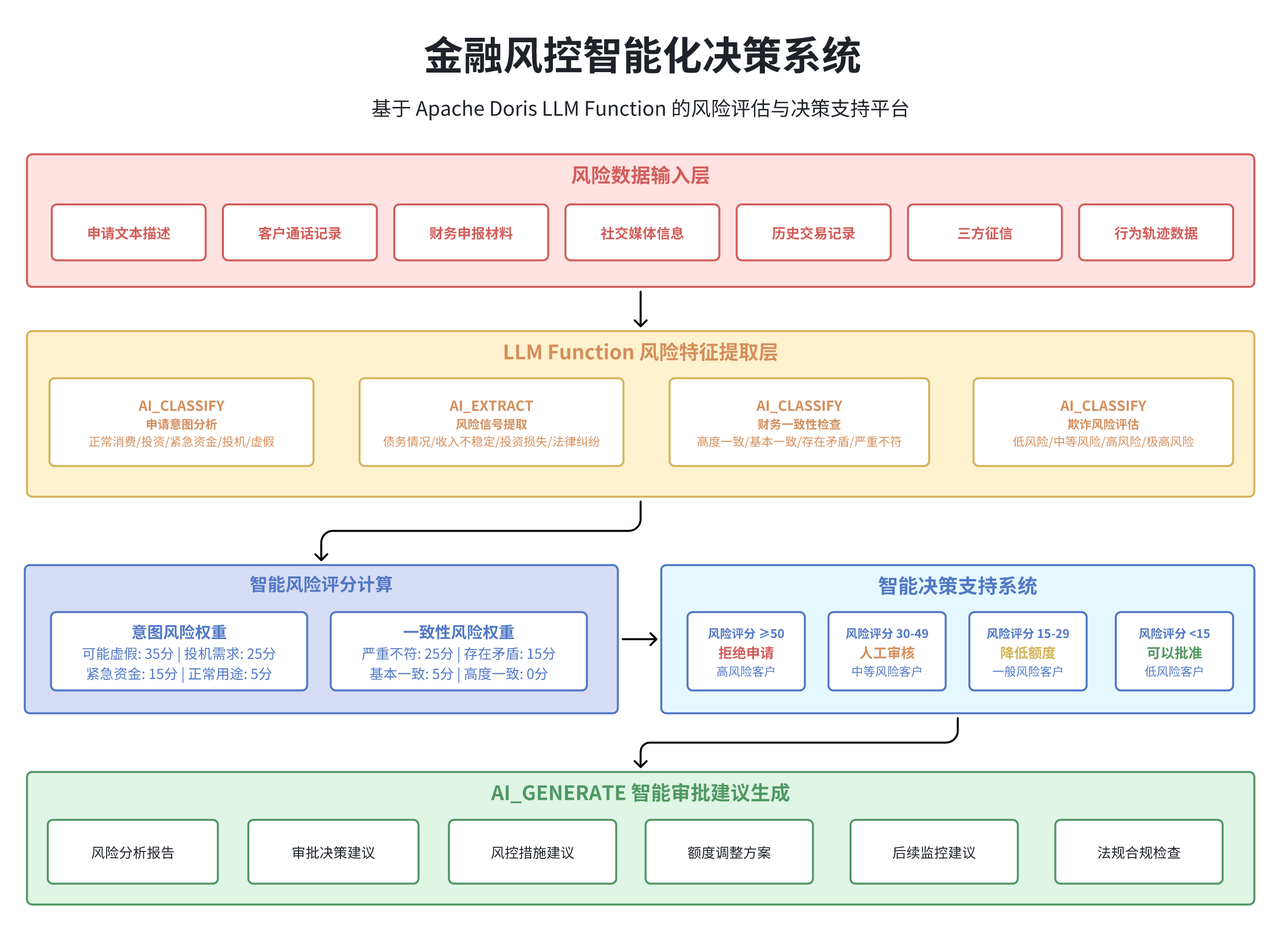
LLM Function 的引入为金融风控提供了新的技术手段。通过自然语言处理能力,可以更好地理解和分析客户的行为模式、风险倾向和潜在欺诈信号,大大提升风控决策的准确性和效率。
-- 金融风控智能决策系统
WITH risk_assessment AS (
SELECT
application_id,
customer_id,
application_text,
declared_income,
requested_amount,
-- 申请意图分析
AI_CLASSIFY('high_performance_llm', application_text,
'正常消费,正常投资,紧急资金,投机需求,可能虚假') as intention_analysis,
-- 风险关键词提取
AI_EXTRACT('high_performance_llm', application_text,
'提取风险信号:债务情况、收入不稳定、投资损失、法律纠纷') as risk_indicators,
-- 财务一致性检查
AI_CLASSIFY('high_performance_llm',
CONCAT('申请描述:', application_text, ' 声明收入:', declared_income, ' 申请金额:', requested_amount),
'高度一致,基本一致,存在矛盾,严重不符') as financial_consistency,
-- 欺诈风险评估
AI_CLASSIFY('high_performance_llm', application_text,
'低风险,中等风险,高风险,极高风险') as fraud_risk_level
FROM loan_applications
WHERE application_date >= CURRENT_DATE - INTERVAL 1 DAY
AND status = 'pending_review'
),
risk_scoring AS (
SELECT
*,
-- 计算综合风险评分
(CASE intention_analysis
WHEN '可能虚假' THEN 35
WHEN '投机需求' THEN 25
WHEN '紧急资金' THEN 15
ELSE 5
END +
CASE financial_consistency
WHEN '严重不符' THEN 25
WHEN '存在矛盾' THEN 15
ELSE 0
END +
CASE fraud_risk_level
WHEN '极高风险' THEN 30
WHEN '高风险' THEN 20
WHEN '中等风险' THEN 10
ELSE 0
END) as total_risk_score
FROM risk_assessment
)
SELECT
*,
-- 自动决策建议
CASE
WHEN total_risk_score >= 50 THEN '拒绝申请'
WHEN total_risk_score >= 30 THEN '人工审核'
WHEN total_risk_score >= 15 THEN '降低额度'
ELSE '可以批准'
END as decision_recommendation,
-- 生成详细审批建议
AI_GENERATE('high_performance_llm',
CONCAT('基于风险分析,提供审批建议:',
'总风险评分:', total_risk_score,
',主要风险:', intention_analysis,
',风险指标:', risk_indicators),
250) as detailed_recommendation
FROM risk_scoring
ORDER BY total_risk_score DESC;
性能优化与成本控制策略深度解析
01 API 调用成本优化的系统性方法
在 LLM Function 的实际应用中,API 调用成本往往是需要重点考虑的因素。不同的 LLM 服务提供商有着不同的计费模式,而且同一个提供商的不同模型在性能和成本之间也存在明显的权衡关系。构建一个成本效益最优的 LLM 应用需要从多个维度进行系统性的优化。
分层资源策略是成本优化的核心思路。根据不同任务的复杂程度和准确性要求,选择合适的模型资源。对于简单的分类和情感分析任务,使用较小的模型(如 GPT-3.5-turbo)通常能够获得足够好的效果,而成本显著低于大模型;对于复杂的信息提取和生成任务,则需要使用更强大的模型来保证输出质量。
-- 智能化的成本控制策略
WITH task_complexity_assessment AS (
SELECT
feedback_id,
feedback_text,
LENGTH(feedback_text) as text_length,
CASE
WHEN LENGTH(feedback_text) < 100 AND feedback_text NOT REGEXP '[复杂|详细|具体]'
THEN '简单任务'
WHEN LENGTH(feedback_text) BETWEEN 100 AND 500
THEN '中等任务'
ELSE '复杂任务'
END as task_complexity
FROM customer_feedback
WHERE create_time >= CURRENT_DATE - INTERVAL 1 HOUR
)
SELECT
feedback_id,
feedback_text,
task_complexity,
-- 根据任务复杂度选择合适的资源
CASE task_complexity
WHEN '简单任务' THEN
AI_SENTIMENT('cost_effective_llm', feedback_text)
WHEN '中等任务' THEN
AI_SENTIMENT('balanced_llm', feedback_text)
ELSE
AI_SENTIMENT('high_performance_llm', feedback_text)
END as sentiment_analysis,
-- 成本估算
CASE task_complexity
WHEN '简单任务' THEN 0.01
WHEN '中等任务' THEN 0.03
ELSE 0.08
END as estimated_cost
FROM task_complexity_assessment;
智能缓存策略是另一个重要的成本优化手段。对于相同或相似的文本输入,可以通过建立缓存机制避免重复的 API 调用。在 Apache Doris 中,可以通过创建专门的缓存表来实现这一功能:
-- 智能缓存系统
CREATE TABLE AI_cache (
content_hash VARCHAR(64),
function_name VARCHAR(50),
original_text TEXT,
result_text TEXT,
confidence_score DECIMAL(3,2),
cache_time DATETIME,
hit_count INT DEFAULT 1,
INDEX idx_hash_function (content_hash, function_name)
) DISTRIBUTED BY HASH(content_hash);
-- 使用缓存的查询逻辑
SELECT
cf.feedback_id,
cf.feedback_text,
COALESCE(
CASE WHEN lc.result_text IS NOT NULL AND
AI_SIMILARITY('cost_effective_llm', cf.feedback_text, lc.original_text) > 0.9
THEN lc.result_text
ELSE AI_SENTIMENT('primary_llm', cf.feedback_text)
END
) as sentiment_result,
CASE WHEN lc.result_text IS NOT NULL THEN 'cache_hit' ELSE 'api_call' END as source
FROM customer_feedback cf
LEFT JOIN AI_cache lc
ON MD5(cf.feedback_text) = lc.content_hash
AND lc.function_name = 'AI_SENTIMENT'
AND lc.cache_time >= CURRENT_DATE - INTERVAL 7 DAY
WHERE cf.create_time >= CURRENT_DATE - INTERVAL 1 HOUR;
02 查询性能调优的最佳实践
LLM Function 的查询性能优化涉及多个层面,从 SQL 查询结构的优化到系统资源的合理配置,都需要进行系统性的考虑。
在查询结构优化方面,合理的 JOIN 顺序和 WHERE 条件的放置对于整体性能有重要影响。由于 LLM Function 的调用成本较高,应该尽可能地在早期阶段过滤数据,减少需要进行 AI 分析的数据量:
-- 性能优化的查询结构设计
WITH filtered_data AS (
-- 第一步:基础数据过滤,减少后续AI分析的数据量
SELECT *
FROM customer_feedback
WHERE create_time >= CURRENT_DATE - INTERVAL 1 DAY
AND content IS NOT NULL
AND LENGTH(content) BETWEEN 20 AND 2000
AND customer_id IN (
SELECT customer_id
FROM active_customers
WHERE last_activity >= CURRENT_DATE - INTERVAL 30 DAY
)
),
priority_analysis AS (
-- 第二步:先进行简单的优先级分类
SELECT
*,
AI_CLASSIFY('cost_effective_llm', content, '高优先级,普通优先级') as priority_class
FROM filtered_data
)
-- 第三步:只对高优先级内容进行详细分析
SELECT
feedback_id,
customer_id,
content,
priority_class,
CASE
WHEN priority_class = '高优先级' THEN
AI_SENTIMENT('high_performance_llm', content)
ELSE
AI_SENTIMENT('cost_effective_llm', content)
END as sentiment_analysis
FROM priority_analysis
WHERE sentiment_analysis IS NOT NULL
ORDER BY
CASE priority_class WHEN '高优先级' THEN 1 ELSE 2 END;
03 权限管理与安全控制
Apache Doris LLM Function 在 4.0 预览版中已经提供了基础的权限控制体系,确保 LLM 资源的安全使用。当前的权限管理主要基于 Apache Doris 的统一权限框架,对 LLM 资源实施访问控制。
在当前版本中,权限控制主要通过 Usage_priv 权限实现,管理员可以控制哪些用户或角色能够使用特定的 LLM 资源。这种权限控制机制确保了只有授权用户才能调用 LLM Function,避免了资源的滥用和安全风险。权限的分配可以基于角色进行管理,也可以直接分配给特定用户,提供了灵活的权限管理方式。
-- LLM资源权限管理示例
-- 创建专门的LLM用户角色
CREATE ROLE AI_analyst;
-- 为角色分配LLM资源使用权限
GRANT USAGE_PRIV ON RESOURCE 'primary_llm' TO ROLE 'AI_analyst';
GRANT USAGE_PRIV ON RESOURCE 'cost_effective_llm' TO ROLE 'AI_analyst';
-- 将角色分配给特定用户
GRANT 'AI_analyst' TO 'data_scientist@company.com';
需要注意的是,当前版本的权限控制粒度相对较粗,主要针对资源级别的访问控制。对于更细粒度的控制需求,如单用户的 LLM API 并发度限制、MaxTokens 参数控制、成本配额管理等功能,将在 Apache Doris 4.0 正式版中得到完善。同时,4.0 正式版还将加入完整的 LLM Function 调用监控和统计系统,包括调用频次、成本分析、性能监控等关键指标的自动收集和分析功能,为企业级应用提供更加完善的运维支持。
技术发展趋势和未来展望
01 AI 原生数据库的演进方向
Apache Doris LLM Function 的推出标志着数据库技术向 AI 原生方向演进的重要里程碑。这种演进不仅仅是功能层面的简单叠加,而是代表了数据处理架构的根本性变革。
从技术发展的历史脉络来看,数据库系统经历了从简单的数据存储到复杂的分析计算的演进过程。早期的数据库主要关注数据的持久化和基本的查询功能,随后发展出了复杂的分析函数、存储过程等高级特性。而 AI 能力的原生集成,代表了数据库技术演进的下一个重要阶段。
计算下推的深度扩展是这一演进的核心特征。传统的计算下推主要针对结构化数据的统计和聚合操作,目标是减少数据在网络中的传输量,提高查询性能。而 AI 计算的下推则扩展到了非结构化数据的语义理解和智能分析。这种扩展不仅提高了处理效率,更重要的是改变了数据分析的范式,使得复杂的 AI 分析可以与传统的 SQL 查询无缝融合。
在未来的发展中,多模态 AI 集成将是一个重要的发展方向。除了当前的文本处理功能外,图像识别、语音分析、视频理解等 AI 能力都有可能成为数据库的原生功能。这将使得数据库能够处理更加丰富和复杂的数据类型,为企业提供更加全面的智能化数据分析能力。
边缘 AI 计算将是另一个重要的发展趋势。随着 AI 模型的小型化和优化技术的发展,越来越多的 AI 计算可能会直接在数据库引擎内部进行,而不是依赖外部 API 服务。这种变化将带来显著的性能提升和成本降低,同时也会增强数据的安全性和隐私保护。
02 企业级 AI 数据分析的发展趋势
从企业应用的角度来看,AI 数据分析正在从辅助工具向核心基础设施转变。这种转变对企业的数据架构、组织结构和业务流程都产生了深远的影响。
数据治理的智能化是一个明显的发展趋势。传统的数据治理主要依赖人工定义的规则和策略,这种方式在面对海量数据和复杂业务场景时往往力不从心。而 AI 能力的引入使得数据治理可以变得更加智能和自适应。通过 LLM Function,企业可以自动识别敏感数据、发现数据质量问题、推荐数据分类标准、生成数据字典等,大大提升数据治理的效率和准确性。
决策支持的实时化是另一个重要趋势。在数字化转型的浪潮中,企业对实时决策支持的需求越来越强烈。传统的数据分析往往需要较长的处理时间,难以满足实时决策的需求。通过 LLM Function,企业可以构建实时的智能决策系统,在业务事件发生的同时进行 AI 分析和决策支持,大大提升业务响应的速度和准确性。
成本效益的平衡优化将成为企业级 AI 应用的关键考量因素。随着 AI 技术的普及,如何在保证分析效果的同时控制成本,将是企业面临的重要挑战。这需要在技术架构、资源配置、业务流程等多个层面进行系统性的优化,实现成本效益的最佳平衡。
总结
Apache Doris LLM Function 作为数据库技术与人工智能深度融合的创新实践,标志着数据分析领域向智能化方向演进的重要里程碑。通过将大语言模型能力原生集成到 SQL 执行引擎中,有效解决了传统数据分析架构中 AI 能力集成的技术挑战。
- 从技术架构层面来看,LLM Function 采用资源池化管理和 SQL 原生集成的设计理念,实现了 AI 处理能力与数据查询的无缝融合。十大核心函数覆盖了文本分析、内容生成、数据处理等主要应用场景,为企业级智能化数据分析提供了完整的技术工具集。
- 在实践应用方面,通过智能客服、内容运营、金融风控等典型场景的深度分析,验证了 LLM Function 在提升业务效率、优化决策质量、降低运营成本方面的显著价值。同时,通过系统化的性能优化和成本控制策略,为该技术在生产环境中的大规模部署提供了可靠保障。
本文系统阐述了 Apache Doris LLM Function 的技术价值和应用前景,期望为相关技术从业者在智能化数据分析领域的探索和实践提供有益参考。展望未来,随着 AI 原生数据库、多模态智能分析、边缘计算等技术的持续发展,Apache Doris LLM Function 所代表的技术路径将在企业数字化转型中发挥更加重要的作用。


