引言
随着大模型和多模态 AI 的快速发展,向量已成为文本、图像、音视频等多元数据的通用语义表示。在这种背景下,检索增强生成(RAG)技术成为连接私有知识与大模型的核心桥梁,而高效的向量检索则是其关键支柱。
与将向量检索视为独立外挂服务的方案不同,Apache Doris 4.0 选择将向量检索能力深度集成于其 MPP 分析型数据库内核。实现向量检索与 SQL 计算、实时分析和事务保障的无缝融合。
本文旨在深入剖析 Doris 向量检索的系统级设计与工程实践,展示其如何在性能、易用性与规模扩展之间取得的平衡。
1. ANN 索引核心设计
Apache Doris 的向量索引基于 ANN(近似最近邻)算法实现,并非独立的外挂组件,而是深度集成于存储、执行与 SQL 引擎中的原生能力。在 4.x 版本中,其核心 ANN 索引能力主要包括以下几方面:
- 多索引类型与距离度量支持:支持主流的 ANN 索引类型(HNSW、IVF)及常见距离度量(L2 距离、内积)。用户可根据业务在构建速度、内存占用与召回率上的要求灵活权衡。
- 原生 SQL 集成:向量检索以原生 SQL 算子形式提供,支持直接定义向量列、通过
ORDER BY distance LIMIT K进行相似度搜索,并能与过滤、聚合、JOIN 等算子自由组合,天然支持混合检索与分析。 - 构建与查询解耦:采用异步索引构建机制,数据导入后即可查询,索引在后台构建并加载,避免导入阻塞,保障查询高峰期的稳定低延迟写入。
- 向量压缩优化:在导入与构建阶段支持标量量化(SQ)、乘积量化(PQ)等压缩技术,显著降低存储与内存开销,提升高维大规模向量场景的资源效率。
- 分布式并行执行:依托于分布式架构,Doris 向量索引天然支持数据分片与索引分布式存储;查询可在各 BE 节点并行执行;Top-K 结果在上层进行合并与裁剪。随着节点数量增加,系统能够在数据规模与吞吐能力上实现近线性扩展。
2. Benchmark & Analysis
Apache Doris 的目标并非追求单一指标的极限表现,而是在真实生产负载下,实现性能的均衡性、系统稳定性与架构可扩展性。本次测试将围绕这一目标展开,所用工具为 ZillizTech 开源的向量搜索 BenchMark:https://github.com/zilliztech/VectorDBBench。
- 云服务商:阿里云
- CPU:Intel Xeon Platinum 8369B @ 2.70GHz (16 核)
- 内存:64GB
2.1 导入与构建性能
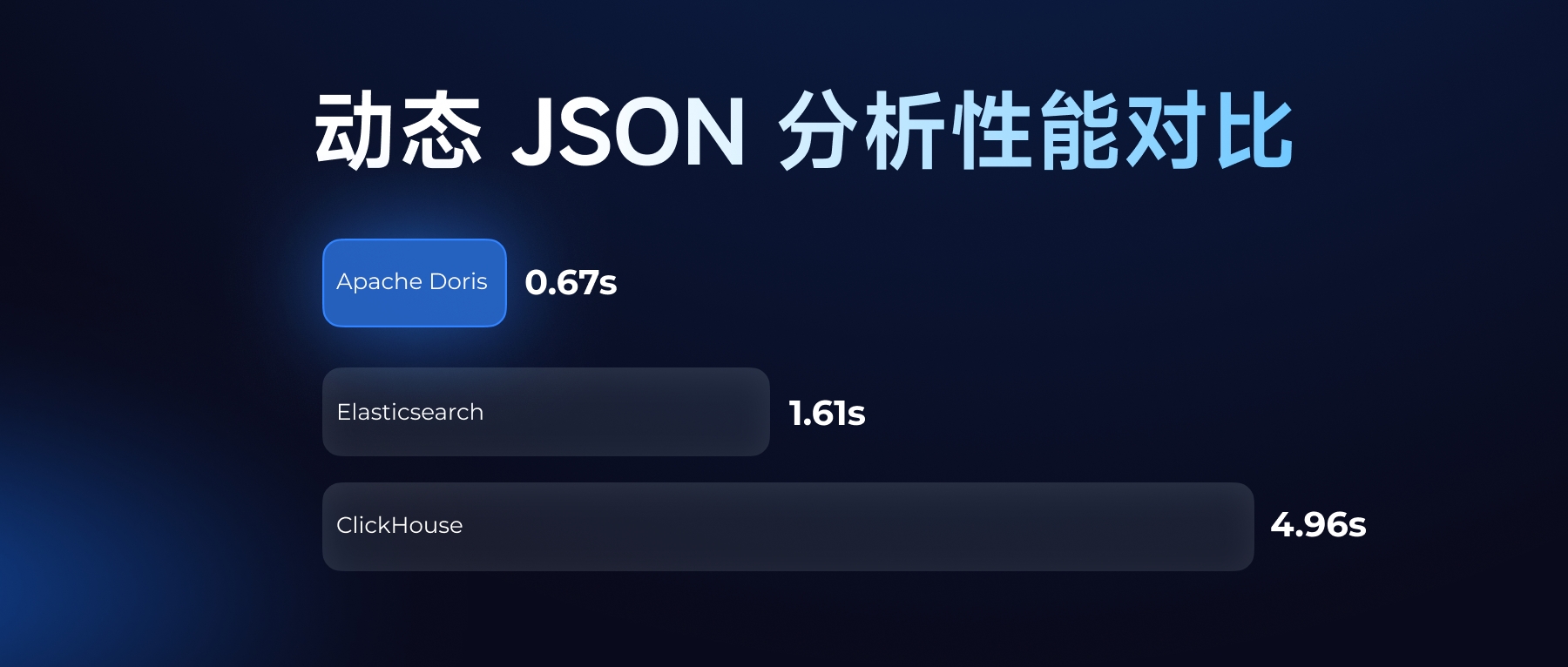
测试结果表明,在 Performance768D1M 数据集上,Apache Doris 在保证同等索引质量的前提下,导入性能显著优于对比系统。尤为重要的是,其导入速度的提升并未以牺牲图结构质量为代价。Doris 在 QPS 达到 895 的同时,仍保持了 97% 以上的召回率,在性能三角的三个维度上取得了出色的平衡。
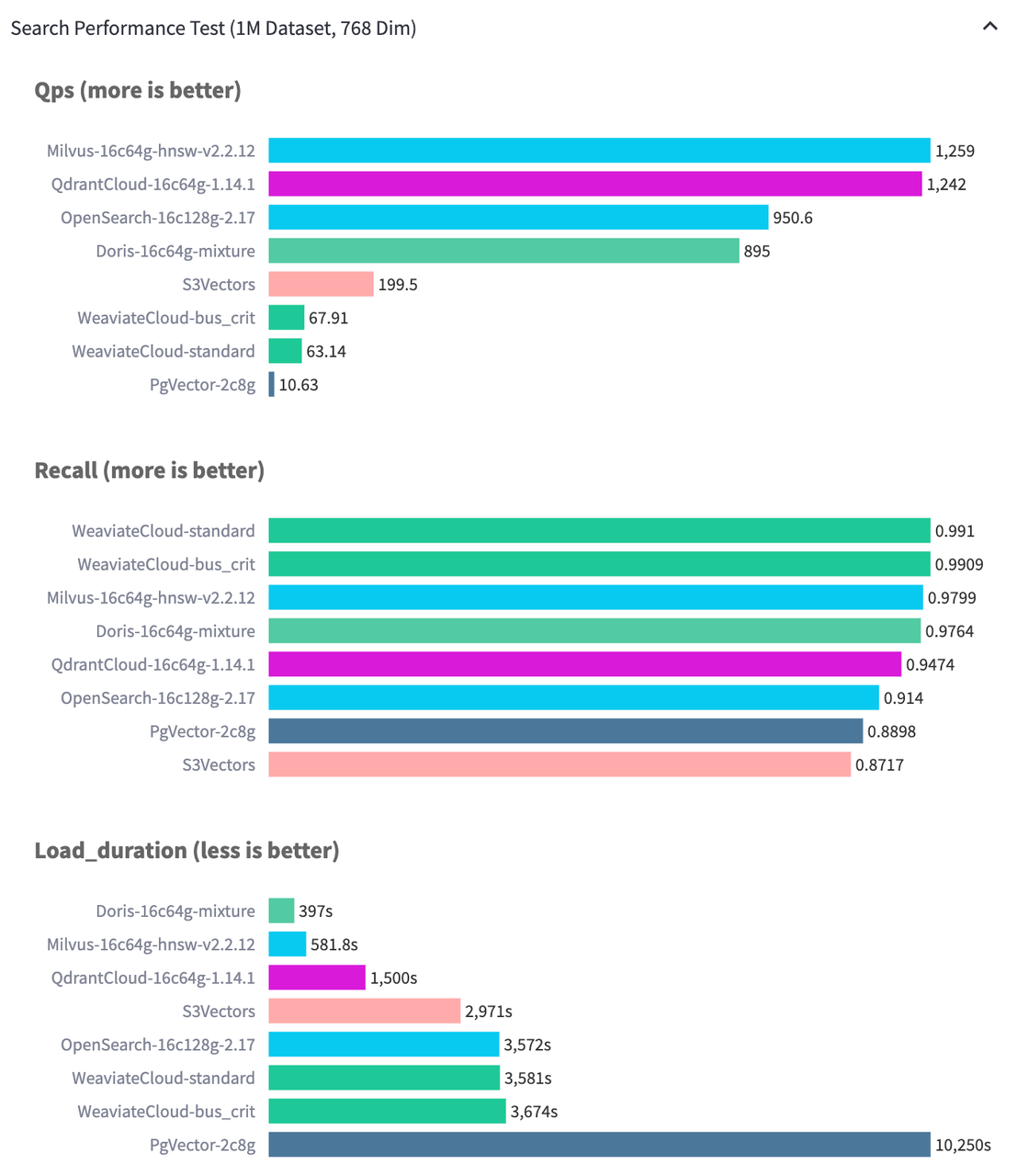
2.2 查询性能
即便单独考量查询性能,Apache Doris 同样处于业界第一梯队。
在 Performance768D10M 数据规模上,当召回率要求高于 95% 时,Apache Doris 的 QPS 表现优于 OpenSearch 与 Qdrant。此结果为默认配置下的开箱性能,未针对 Segment 文件数量等进行专项调优。
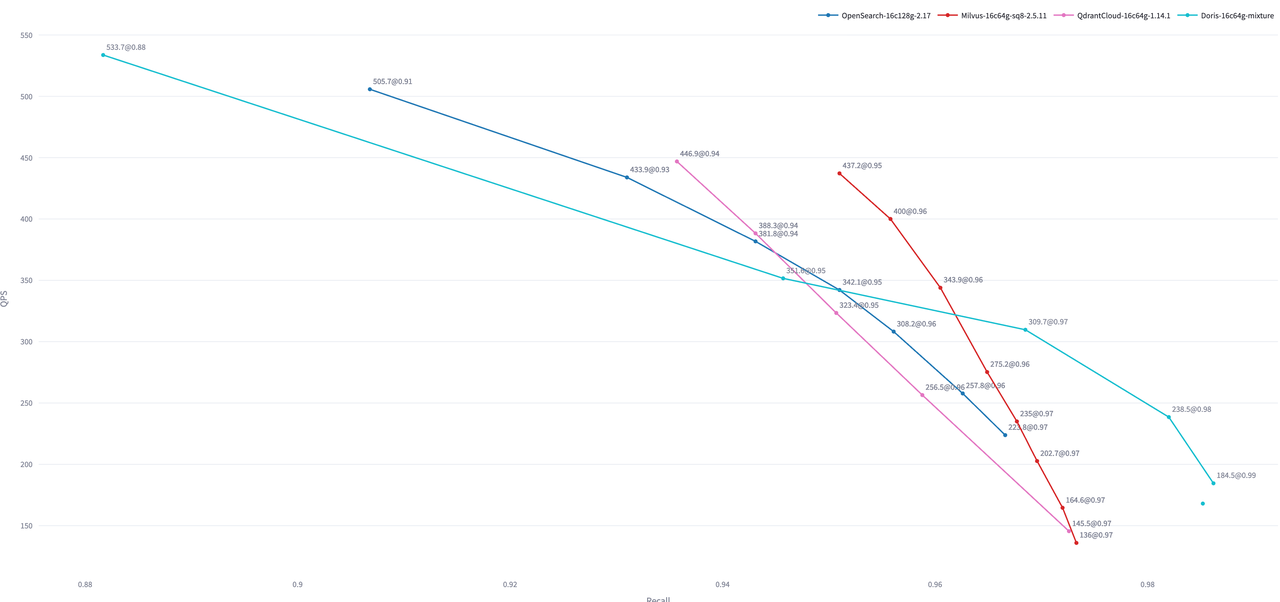
这里比较的是开箱性能测试,即不做 segment 文件数量的优化时的性能对比。
Milvus 的 flat 版本以及 Cloud 版本会有更好的性能表现,但是其出品的 VectorDBBench 只提供了 SQ8 量化后的成绩。
3. 核心设计与性能优化
Apache Doris 采用 FE(协调节点)与 BE(计算节点)构成的分布式架构。BE 作为核心执行单元,承担查询计划执行与数据导入任务,负责几乎所有高负载计算与大规模数据吞吐,是系统高性能的基石。尤其在向量场景下,数据写入、索引构建与向量距离计算都属于典型的 CPU 与内存密集型工作。为充分发挥其性能、保障系统稳定运行,我们对 ANN 索引的写入、构建与查询路径进行了系统优化。
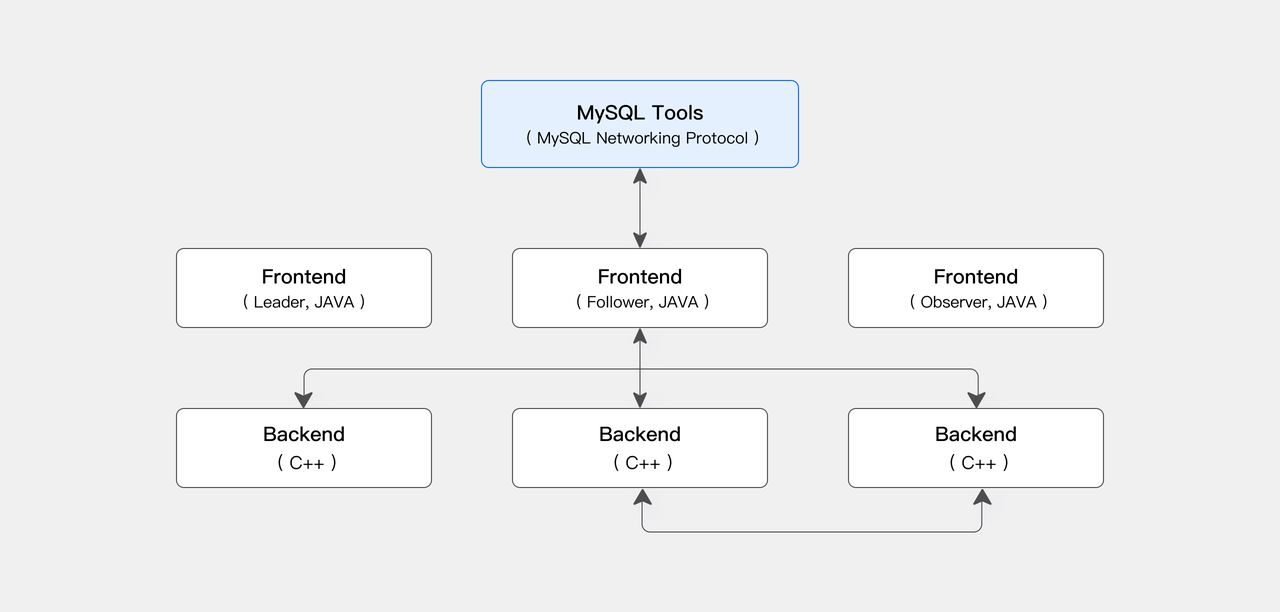
3.1 写入与构建路径优化
优化主要分为两类:功能优化与性能优化。
- 在功能层面,依托 Doris 成熟的分布式集群管理与存储管理能力,引入 LightSchemaChange 实现轻量级的索引管理机制,这是目前专用向量数据库普遍不具备的能力。
- 在性能层面,重点聚焦于索引构建流程的优化,以显著提升索引构建速度和整体吞吐能力。
3.1.1 异步索引构建机制
Apache Doris 针对 ANN 索引构建开销大的问题,提供了异步构建机制。用户可在数据导入后,选择业务低峰期触发索引构建;在查询高峰时,仅需将已建好的索引加载至内存即可快速检索,从而将密集的 CPU 消耗转移至成本更低的时段。
在 FE 侧,CREATE INDEX 与 BUILD INDEX 通过 SchemaChangeHandler 编排:
- 为每个分区创建影子索引与影子 Tablet(
IndexState.SHADOW),并建立 origin→shadow 的 Tablet 映射与影子副本(副本初始态为ALTER)。 - 生成新的 schema version/hash,保障新旧版本隔离。
- 通过 FE→BE 的 AgentTask(Thrift)分发构建任务到各 BE,BE 在 Tablet 层面完成索引数据构建。
- 构建成功后,FE 原子性地将影子索引切换为正式索引,更新元数据并清理旧工件。
该流程在保证线上业务可读写的同时,实现了索引构建的在线隔离与数据一致性。
3.1.2 导入性能优化
为在保障索引质量的前提下提升写入吞吐与稳定性,Doris 采用了 多层级分片、双层并行、SIMD 向量化计算 的组合方式进行优化。
A. 多层级分片
Apache Doris 将逻辑表在内核层拆分为多个 Tablet。每次数据导入会生成一个 Rowset,每个 Rowset 又包含若干 Segment,而 ANN 索引正是在 Segment 粒度上构建与使用的。这一设计将“全表数据量”与“索引超参数”解耦,用户只需根据单批次导入的数据规模来设定参数,无需因数据总量增加而反复重建索引。
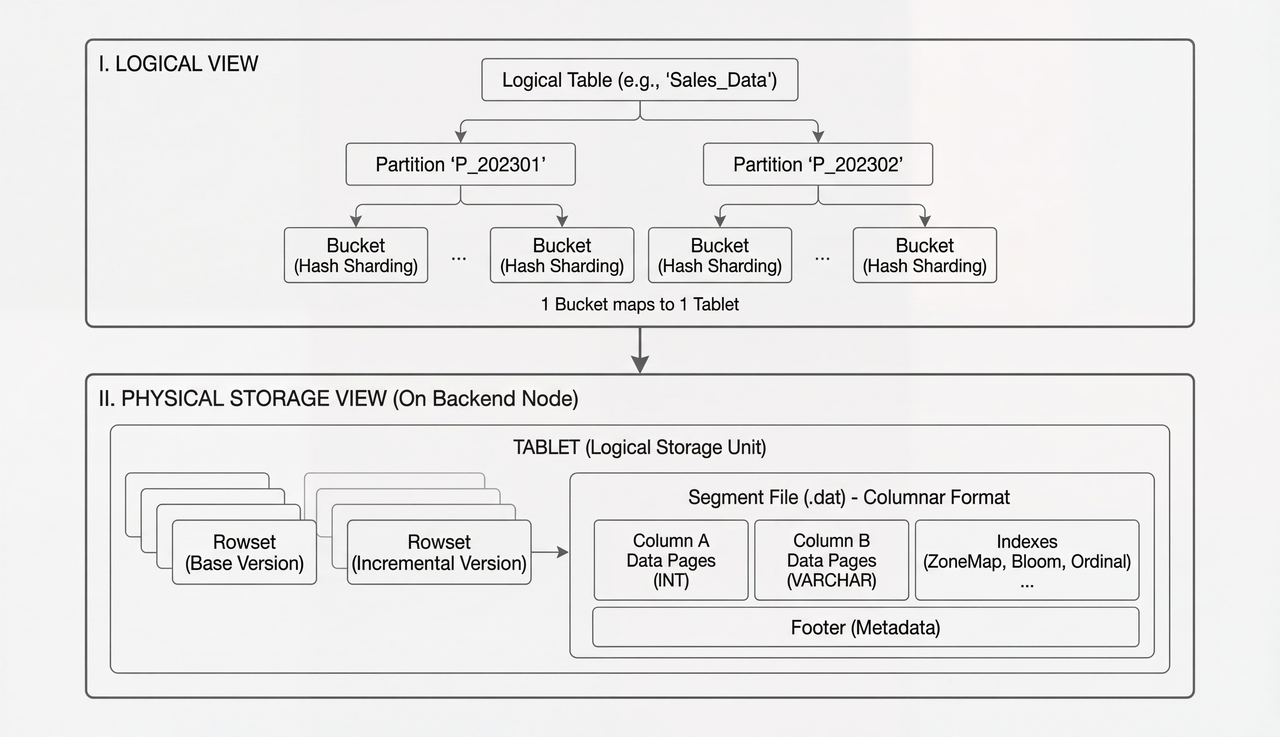
以单 BE 单分桶的典型场景为例,我们从实际经验中总结出如下参数可供参考:
得益于 Apache Doris 的分片架构下,索引参数可稳定在合理的规模区间,不受全表数据总量增长的影响。换言之,索引超参数的设置只需基于单个 Tablet 单次导入的数据行数。即便集群规模扩大,也仅需根据机器与分桶数量相应调整批次大小(batch size)即可。
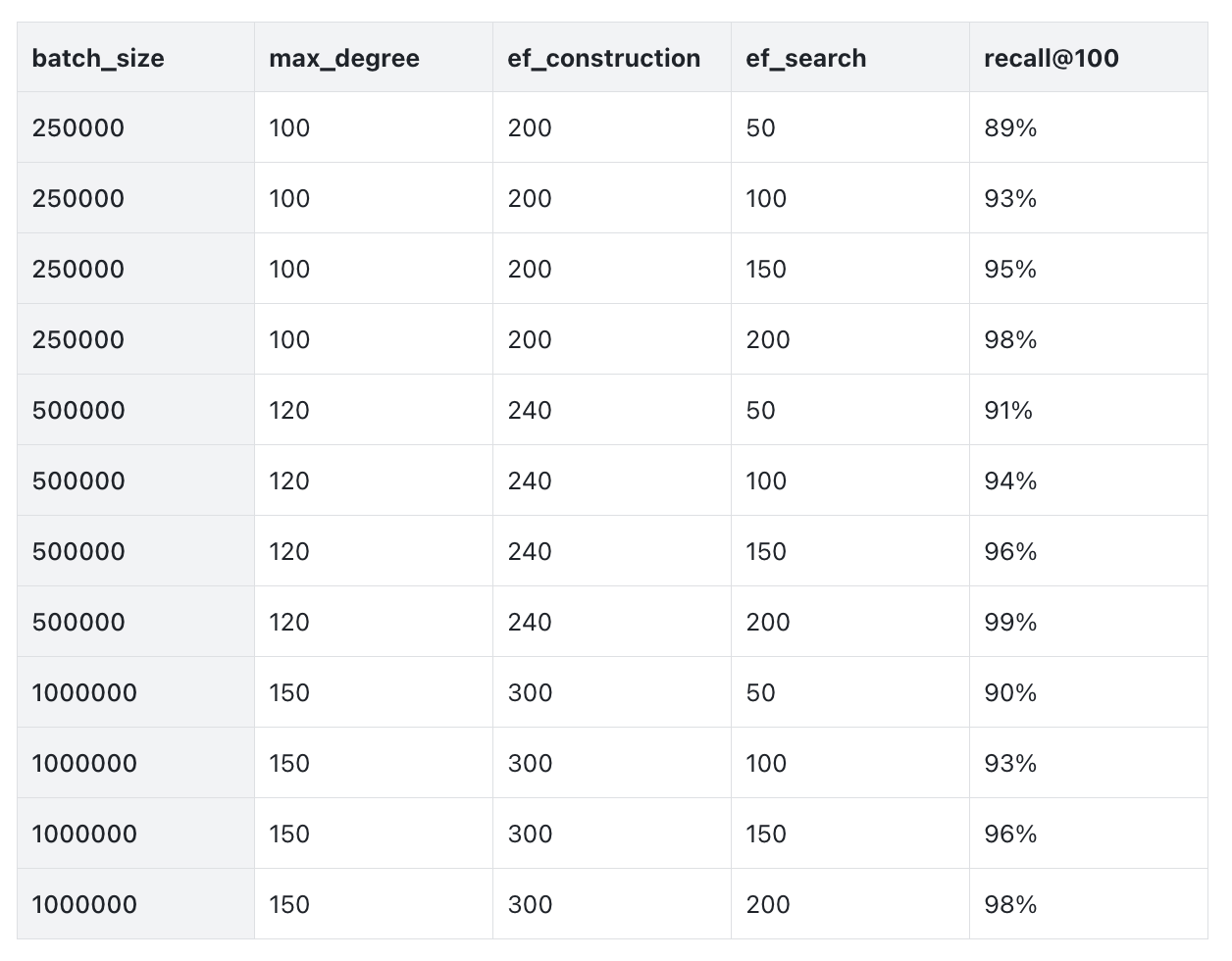
以 HNSW 索引为例,在单 BE 集群中,针对每批导入 25 万、50 万、100 万行的典型规模,分别选择 max_degree≈100/120/150、ef_construction≈200/240/300、hnsw_ef_search≈50~200,即可在延迟可控的同时平衡召回与构建成本。
经验上,召回率随 hnsw_ef_search 提高而改善,但查询延迟也会线性增加。max_degree 与 ef_construction 过小会导致图结构稀疏、查询不稳定;过大则会显著增加构建时间与内存占用。因此,建议结合业务对召回和延迟的要求,通过离线压测确定最佳参数组合。
B. 双层并行构建
集群层由多台 BE 并行处理导入批次;单机内再对同一批数据进行多线程距离计算和图结构更新。配合“内存攒批”(在内存中适度合并小批次),可避免过细分批导致的图结构稀疏与召回下滑,在固定超参数下获得更稳定的索引质量与构建速度。
以 768 维、1,000 万条向量为例:分 10 批构建的召回率约可达 99%,若切成 100 批则可能降至约 95%。适度的内存攒批既不显著抬高内存峰值,又能提升图连通性和近邻覆盖,从而减少查询阶段的回表与重复计算。
C. SIMD 加速
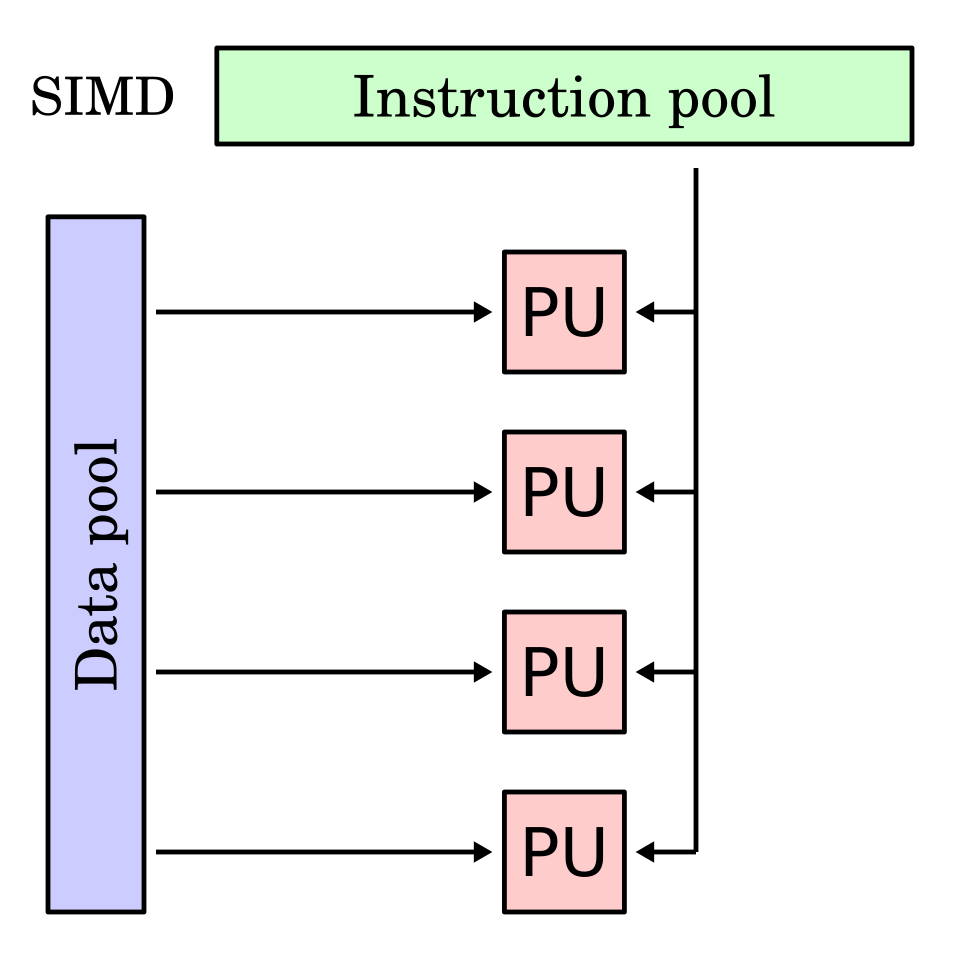
向量距离计算是典型的 CPU 密集型计算。Doris 在 BE 侧采用 C++ 实现距离计算,引入 SIMD(单指令多数据)并行计算。可以更少的指令、更少的访存,更快完成把同样的距离,从而显著提升向量索引构建和重排阶段的吞吐能力。具体来讲:
- 并行计算多个维度:利用 SSE / AVX / AVX-512 等指令集,同时加载和计算 8~16 个浮点数,而非逐维循环。
- 减少内存访问:在计算前对向量数据进行批处理和转置,使数据在内存中连续排列,优化 CPU Cache 访问模式。
- 合并计算步骤:使用 FMA(乘加融合)指令,把“乘法 + 加法”合并为一步,并通过水平求和快速聚合向量数据。
- 高效处理边界情况:对维度不对齐的尾部数据,使用掩码指令统一处理,避免额外分支和判断。
3.1.3 向量压缩技术
以 HNSW 为代表的高性能索引数据结构通常将向量与图结构常驻内存。在 RAG 场景中,文本/图片/音频等模态向量维度约为 1,000,若每维使用 FLOAT32 存储,一百万行占用 4 GB,千万行则约 40 GB。考虑到索引结构的额外占用(约 1.3 倍),一千万行整体接近 52 GB。以 16C64GB 机器为例,单机索引上限约为千万级,需预留空间以避免 OOM,并保障查询和构建的并行开销。
为了显著降低内存占用、扩展单机承载能力,向量压缩技术成为关键。Apache Doris 在此提供了两种主流的实现方案:标量量化与乘积量化。
A. 标量量化(Scalar Quantization,SQ)
标量量化通过用低精度类型替换高精度类型来压缩存储空间,Doris 支持 INT8 和 INT4 的标量量化,并在导入和构建阶段完成编码。
如若将 FLOAT32(4 字节)替换为 INT8(1 字节)可节省约 75% 存储,进一步压缩为 INT4 则节省约 87.5%。如果压缩后数据的分布形态保持一致,召回率在可控延迟内接近未压缩效果。
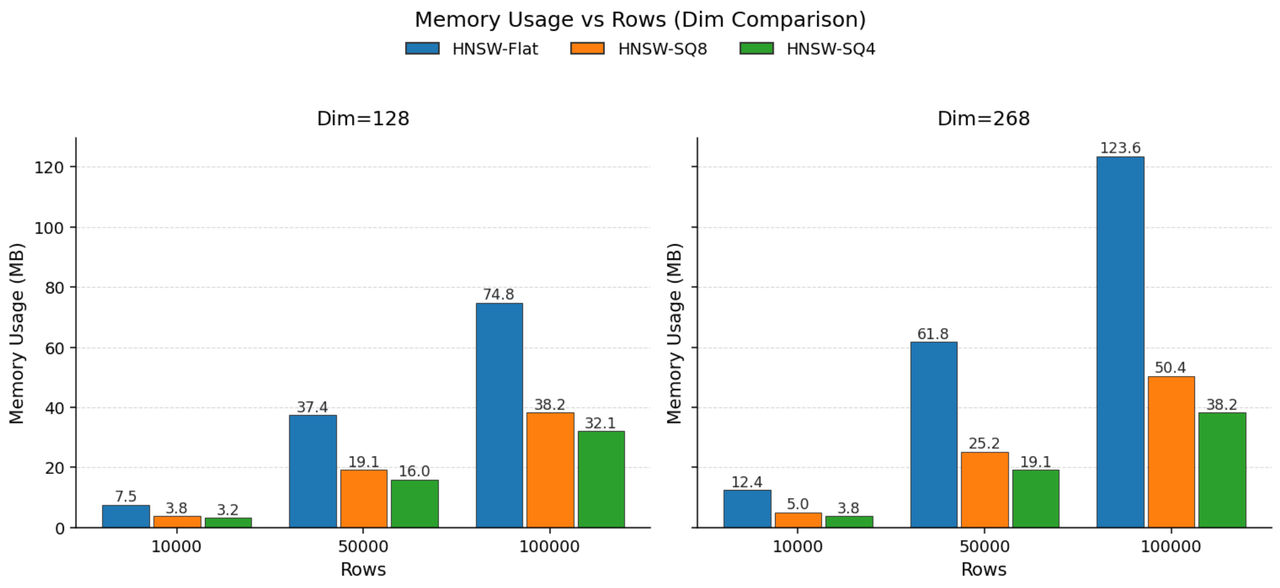
上图展示了在 128 维和 268 维向量上的测试结果。相比 FLAT(不编码,用完整 Float32 表示每个浮点数),SQ8 可实现接近 2.5 倍的压缩,而 SQ4 可实现接近 3.3 倍的压缩。
值得说明的是,引入 SQ 不可避免的会带来额外的压缩计算开销(索引构建阶段),且标量量化更适用于各维度近似均匀分布的数据。如遇分布呈高斯或更复杂形态时,标量量化误差增大,则可采用乘积量化方式。
B. 乘积量化(Product Quantization, PQ)
RAG 等场景中,由 Transformer 编码器生成的向量,存在明显的语义结构、分布不均匀。乘积量化通过子空间划分 + 子空间学习型量化,能够更好地适配。
PQ 将高维向量分割为多个子向量,并为每个子空间独立训练一个码本(例如通过 k-means 聚类学习质心)。这使得数据密集区域能用更精细的码本保持细节,从而在整体上用更短的码长维持原始的距离关系。查询时通过查表与累加来估算距离,大幅减少了计算与内存访问开销。
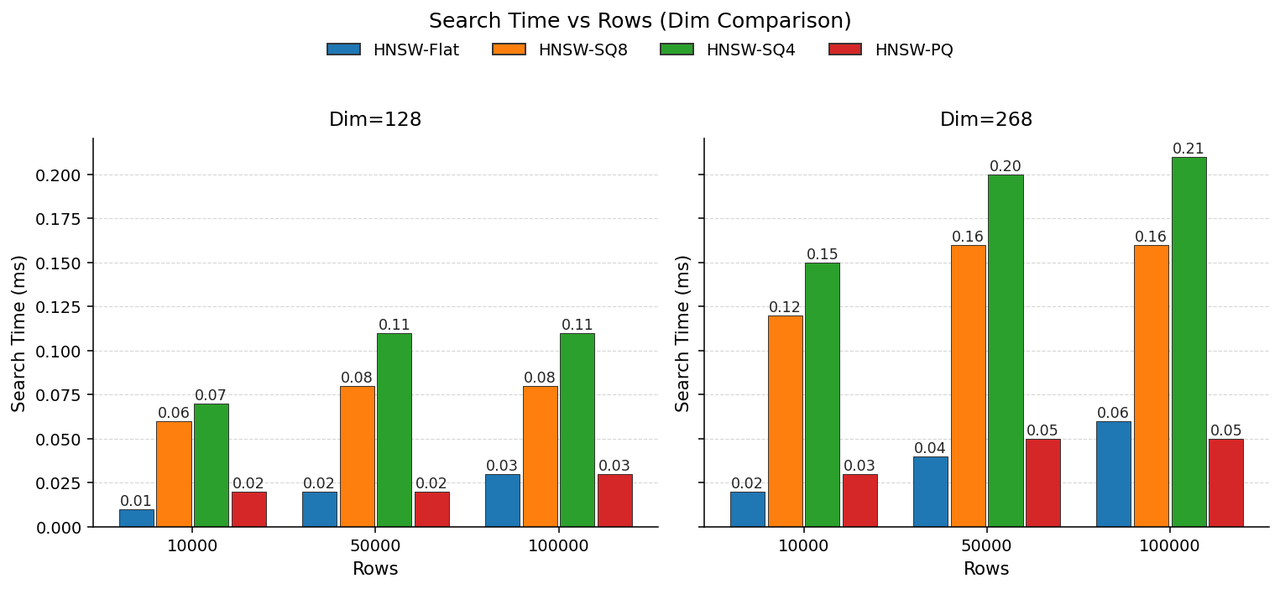
我们在 128 维与 268 维上对比 SQ 与 PQ,参数统一设定为 pq_m = dim/2、pq_nbits = 8。
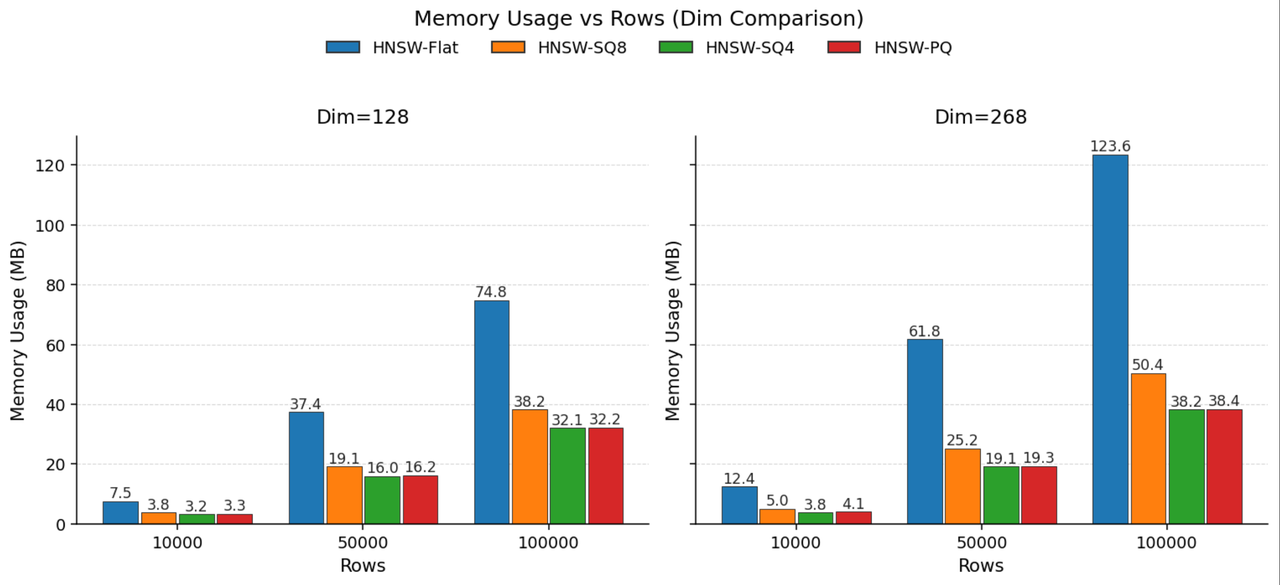
从空间占用看,PQ(m=68/128, nbits=8)的内存占比与 SQ4 大致相当,可实现约 3× 压缩。
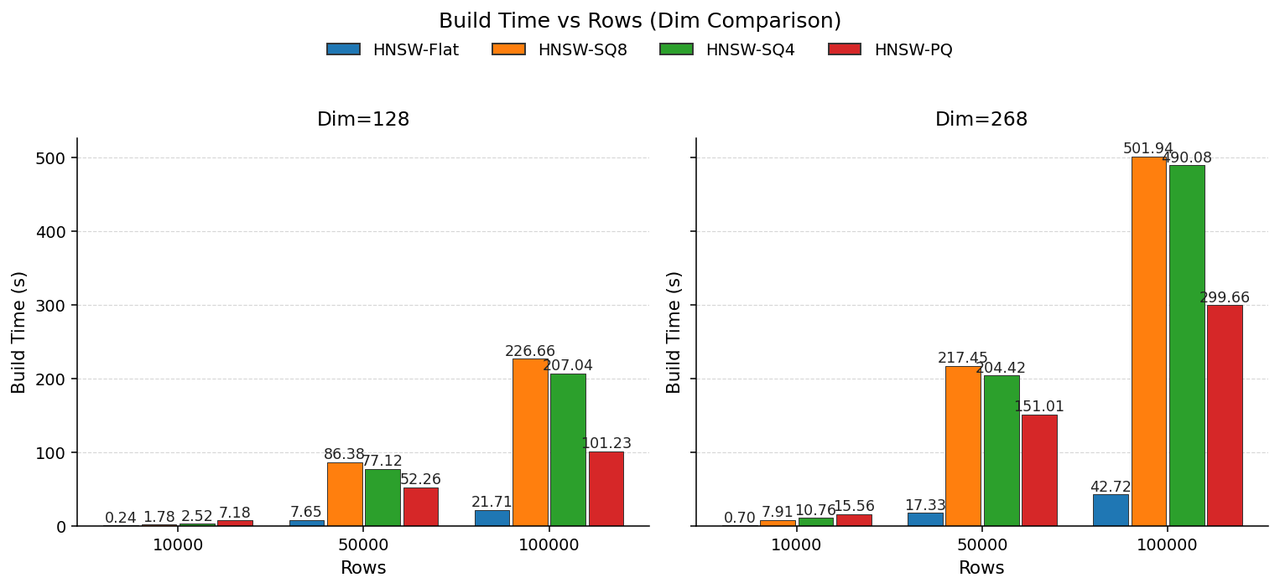
除构建更快外,PQ 还可依赖查表加速解码,体现在更优的查询速度上。
关于 PQ 的超参数,实际使用时建议结合数据分布进行针对性适配与调优。根据经验,将 pq_m 设为原始维度的一半,pq_nbits 设为 8,在多数场景下即可取得良好的效果,可作为初始调优的参考起点。
综合来看,对于用户来说, SQ 和 PQ 该如何选择呢?
- 从使用上来说,SQ 的优点是使用方式简单,只需要指定数据类型即可,而 PQ 的使用门槛更高,需要对其原理有较为深刻的理解才能在生产环境中发挥其优势。
- 从性能及开销上来说,SQ 在解码阶段存在额外计算开销,且随维度增加开销更高;PQ 则能在压缩的同时保持接近原始向量的查询性能。
- 从场景上来说,SQ 更适用于各维度近似均匀分布的数据。如遇分布呈高斯或更复杂形态时,标量量化误差增大,则可采用乘积量化方式。
3.2 查询执行路径优化
搜索场景对延迟极为敏感。在千万级数据量与高并发查询的场景下,通常需要将 P99 延迟控制在 200 ms 以内。这对 Doris 的优化器、执行引擎以及索引实现都提出了更高要求。Apache Doris 为此做了大量优化,这一章节对其中涉及到的部分能力做介绍。
3.2.1 虚拟列机制
Apache Doris 的向量索引采用外挂方式。外挂索引便于管理与异步构建,但也带来性能挑战:如何避免重复计算与多余 IO?
ANN 索引在返回行号时,会同步计算出向量距离。执行引擎在 Scan 算子阶段可直接利用该结果进行筛选和排序,无需在读取数据后重新计算。这一过程通过 “虚拟列” 机制自动实现,最终以 Ann Index Only Scan 的形式运行,完全消除了因距离计算而产生的数据读取 I/O。
未应用 Index Only Scan:
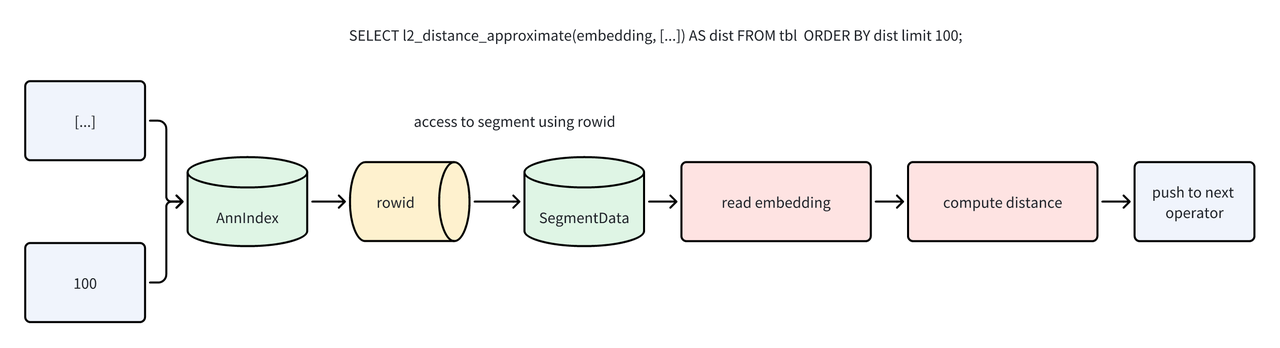
应用 Index Only Scan 后:
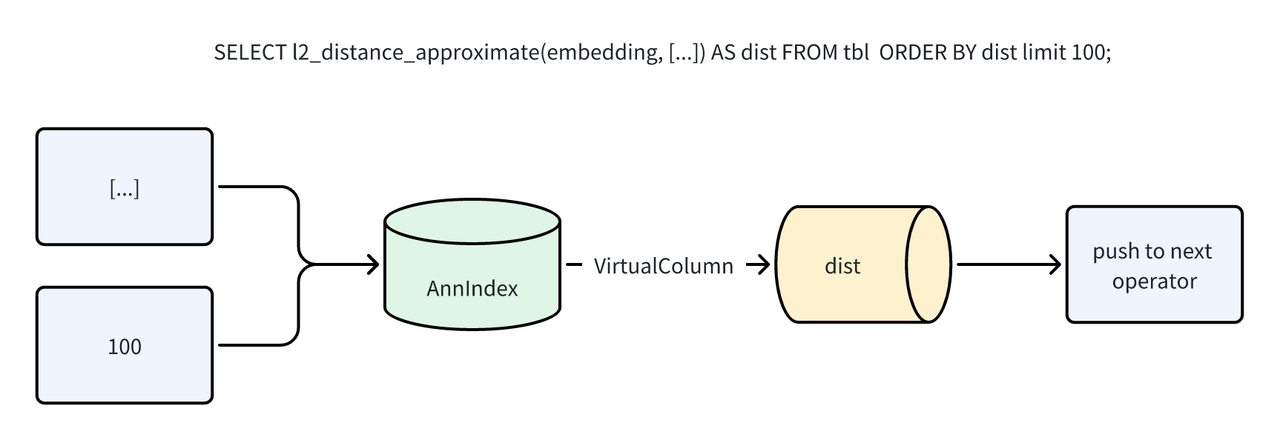
例如 SELECT l2_distance_approximate(embedding, [...]) AS dist FROM tbl ORDER BY dist LIMIT 100;,执行过程将不再触发数据文件 IO。
该优化不仅适用于 TopK 检索,也支持 Range Search、复合检索(Range + TopK)以及与倒排索引结合的混合检索场景,实现了全路径的 Index Only Search。
虚拟列机制并不局限于向量距离计算。对于正则抽取、复杂标量函数等 CPU 密集型表达式,若在同一查询中被多次引用,该机制也能复用中间结果,避免重复计算。以 ClickBench 数据集为例,以下查询统计从 Google 获得最多点击的 20 个网站:
set experimental_enable_virtual_slot_for_cse=true;
SELECT counterid,
COUNT(*) AS hit_count,
COUNT(DISTINCT userid) AS unique_users
FROM hits
WHERE ( UPPER(regexp_extract(referer, '^https?://([^/]+)', 1)) = 'GOOGLE.COM'
OR UPPER(regexp_extract(referer, '^https?://([^/]+)', 1)) = 'GOOGLE.RU'
OR UPPER(regexp_extract(referer, '^https?://([^/]+)', 1)) LIKE '%GOOGLE%' )
AND ( LENGTH(regexp_extract(referer, '^https?://([^/]+)', 1)) > 3
OR regexp_extract(referer, '^https?://([^/]+)', 1) != ''
OR regexp_extract(referer, '^https?://([^/]+)', 1) IS NOT NULL )
AND eventdate = '2013-07-15'
GROUP BY counterid
HAVING hit_count > 100
ORDER BY hit_count DESC
LIMIT 20;
核心表达式 regexp_extract(referer, '^https?://([^/]+)', 1) 为 CPU 密集型且被多处复用。启用虚拟列优化(set experimental_enable_virtual_slot_for_cse=true;)后,端到端性能提升约 3 倍。
3.2.2 前过滤与谓词下推
在 ANN TopN 检索中,过滤谓词的应用时机是关键的设计权衡:
- 前过滤:在 TopN 之前应用谓词,能阻止无效行进入候选;但需在候选集维护过程中实时剔除不符合条件的行。
- 后过滤:先按相似度取出 TopN,再执行过滤,可能导致最终结果不足 N 条。虽然可通过扩大 N 来补偿,但会额外增加扫描与计算开销。
Apache Doris 在 Scan 算子内通过 row bitmap 实现自然的前过滤语义。每个谓词执行后即时更新 row bitmap。当 TopN 下推到 Scan 时,向索引传递一个基于 row bitmap 的 IDSelector,仅保留满足条件的行作为候选,从源头上避免无效候选进入 TopN。
为进一步提升效率,Doris 还会在扫描前借助分区、分桶、ZoneMap 等轻量元数据进行快速预过滤,并结合倒排索引进行精确的行号定位,多层次缩小候选集,能够显著提升查询性能与资源效率。
3.2.3 全局执行优化
在传统执行路径中,Doris 会对每条 SQL 执行完整优化流程(语法解析、语义分析、RBO、CBO)。这在通用 OLAP 场景必不可少,但在搜索等简单且高度重复的查询模式中会产生明显的额外开销。为此,Doris 进行了全局执行优化,充分发挥索引、过滤等性能。
A. Prepare Statement:
Doris 4.0 扩展了 Prepare Statement,使其不仅支持点查,也适用于包含向量检索在内的所有 SQL 类型。Prepare Statement 的原理是将 SQL 编译与执行分离,模板化检索复用计划缓存,Execute 阶段跳过优化器。查询计划按“标准化 SQL + schema 版本”构建指纹进行缓存,执行阶段校验 schema version,变化则自动失效并重建。对频繁且结构相同仅参数不同的检索,Prepare 能显著降低 FE 侧 CPU 占用与排队等待。
B. Scan 并行度优化:
为提升 ANN TopN 检索性能,Doris 重构了 Scan 并行策略。原策略基于行数划分任务,在高维向量场景下,单个 Segment 的实际行数常远低于划分阈值,导致多个 Segment 被分配至同一任务中串行扫描,制约性能。
为此,Doris 改为严格按 Segment 创建 Scan Task,显著提升了索引检索阶段的并行度。由于 ANN TopN 搜索本身过滤率极高(仅返回 TopN 行),后续回表阶段即使串行执行,对整体吞吐与延迟的影响也微乎其微。
以 SIFT 1M 数据集为例,开启 optimize_index_scan_parallelism=true 后,TopN 查询耗时从 230ms 降至 50ms,效果显著。
此外,4.0 引入动态并行度调整:每轮调度前根据 Scan 线程池压力动态决定可提交的任务数;压力大则减并行、资源空闲则增并行,以在串行与高并发场景间兼顾资源利用率与调度开销。
C. TopN 全局延迟物化:
典型的 ANN TopN 查询可分为两个关键阶段:局部检索与全局归并。在局部检索阶段,Scan 算子通过索引获取每个数据分片(Segment)中的局部 TopN 近似距离;随后在全局归并阶段,由专门的排序节点对所有分片的局部结果进行合并,筛选出最终的全局 TopN。
传统执行流程存在一个显著效率问题:若查询需要返回多列或包含大字段(如长文本),在第一阶段就会读取这些列的全部数据。这不仅会引发大量磁盘 I/O,而且绝大多数被读取的行会在第二阶段的排序竞争中被淘汰,造成计算与 I/O 资源的浪费。
为此,Doris 引入了 “全局 TopN 延迟物化” 优化。该机制将非排序所需列的读取推迟到最终结果确定之后,大幅减少了不必要的 I/O。
优化执行流程示例:
以 SELECT id, l2_distance_approximate(embedding, [...]) AS dist FROM tbl ORDER BY dist LIMIT 100; 为例:
- 局部轻量扫描:每个 Segment 利用 Ann Index Only Scan 结合虚拟列技术,仅计算出局部 Top 100 的距离值(
dist)及其对应的行标识(rowid),不读取其他列。 - 全局排序筛选:系统汇总所有 M 个 Segment 的中间结果(共 100 × M 条候选),对其进行全局排序,从而确定最终的 100 个目标
rowid。 - 按需延迟物化:最终的
Materialize算子根据上一步得到的rowid,精准地到对应的存储位置读取所需列(例如id)的数据。
通过将完整数据的“物化”步骤推迟到最后,该优化确保了查询前期仅处理轻量的距离与行标识信息,彻底避免了在排序前读取非必要列所带来的 I/O 开销,从而显著提升了整体查询效率。
4. 实战:使用 Apache Doris 搭建企业知识库
企业级知识库是 RAG 的典型落地场景。因此,我们基于 LangChain + Apache Doris 搭建了一个以 Doris 官网文档为语料的最小可用知识库,用于验证 Doris 向量检索的端到端能力。完整示例代码见 GitHub。
(1)环境准备
- LLM:用于对话与答案生成,这里使用 DeepSeek。先在官网注册并创建 API Key,妥善保存,后续用于调用 DeepSeek API。
- 嵌入模型:用于生成检索向量,这里使用 Ollama +
bge-m3:latest。bge-m3 是开源的通用检索向量模型,兼顾中英文检索效果,默认输出 1024 维向量,适合知识库检索场景。
(2)建库与建表(方式一:SQL)
CREATE DATABASE doris_rag_test_db;
USE doris_rag_test_db;
CREATE TABLE doris_rag_demo (
id int NULL,
content text NULL,
embedding array<float> NOT NULL,
INDEX idx_embedding (embedding) USING ANN PROPERTIES("dim" = "1024", "ef_construction" = "40", "index_type" = "hnsw", "max_degree" = "32", "metric_type" = "inner_product")
) ENGINE=OLAP
DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1",
"storage_medium" = "hdd",
"storage_format" = "V2",
"inverted_index_storage_format" = "V3",
"light_schema_change" = "true"
);
说明:若计划使用 SDK 一键建表与导入(见 ⑤),本节可省略。
(3)演示语料
示例使用 Apache Doris 官网文档作为语料来源:https://github.com/apache/doris-website
(4)离线文档处理
- 切块(chunking):采用重叠分割,将长文档切分为段落片段。
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=400, chunk_overlap=100, length_function=len
)
chunks = text_splitter.split_text(text)
- 生成向量(embedding):对每个片段生成嵌入向量。
from typing import List, Dict
from langchain_community.embeddings import OllamaEmbeddings
embeddings = OllamaEmbeddings(model='bge-m3:latest', base_url='http://localhost:11434')
docs: List[Dict] = []
cur_id = 1
for chunk in chunks:
docs.append({"id": cur_id, "content": chunk})
cur_id += 1
contents = [d["content"] for d in docs]
vectors = embeddings.embed_documents(contents)
(5)导入 Doris(方式二:SDK 一键建表与导入)
import pandas as pd
df = pd.DataFrame(
[
{
"id": d["id"],
"content": d["content"],
"embedding": vec,
}
for d, vec in zip(docs, vectors)
])
from doris_vector_search import DorisVectorClient, AuthOptions, IndexOptions
auth = AuthOptions(
host='localhost',
query_port=9030,
http_port=8030,
user='root',
password='',
)
client = DorisVectorClient('doris_rag_test_db', auth_options=auth)
index_options = IndexOptions(index_type="hnsw", metric_type="inner_product")
table = client.create_table(
'doris_rag_demo',
df,
index_options=index_options,
)
说明:若已通过 ② 使用 SQL 创建好表并定义索引,可仅使用 SDK 的导入接口(如 insert/load 等,视 SDK 能力而定)将数据写入既有表。
(6)在线查询过程
向量检索
query = 'Doris 支持哪些存储模型?'
query_vec = embeddings.embed_query(query)
df = (
table.search(query_vec)
.limit(5)
.select(["id", "content"])
.to_pandas()
)
答案生成
ctx = "\n".join(f"{r['content']}" for _, r in df.iterrows())
prompt = "以下是检索到的 Doris 文档片段:\n\n{}\n\n请根据上述内容回答:{}".format(ctx, query)
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
model='deepseek-v3-1-terminus',
api_key='xxxx',
base_url='https://xxx',
temperature=float(1.0))
resp = llm.invoke(prompt)
返回的内容是:
'根据提供的文档内容,Apache Doris 支持以下三种存储模型:\n\n1. 明细模型(Duplicate Key Model):适用于存储事实表的明细数据。\n2. 主键模型(Unique Key Model):保证主键的唯一性,相同主键的数据会被覆盖,从而实现行级别的数据更新。\n3. 聚合模型(Aggregate Key Model):相同键(Key)的数值列(Value)会被自动合并,通过提前聚合来大幅提升查询性能。\n\n此外,文档在“灵活建模”部分还提到,Apache Doris 支持如宽表模型、预聚合模型、星型/雪花模型等建模方式,这些可以看作是建立在上述三种核心存储模型之上的数据组织方法。'
5. 总结
本文从 AI 时代的数据形态演进出发,系统性地介绍了 Apache Doris 在 4.x 版本中引入的向量检索能力,并对其底层实现进行了深入剖析。从 ANN 索引的能力边界,到 FE / BE 架构下的写入、构建与查询路径,再到 SIMD、压缩编码与执行引擎层面的工程优化,Doris 的向量搜索并非简单接入一个索引库,而是围绕 性能三角(召回率 / 查询延迟 / 构建吞吐) 精心设计的系统级方案。未来,我们还会进一步强化,使其成为 AI 时代数据系统智能检索的基石。