
导读:面对海量多模态数据管理困境,思必驰通过构建以 Apache Doris 为核心的数据集平台,实现了数据从“散、乱、滞”到“统、明、畅”的转变。在关键场景中,存储占用下降 80%、查询 QPS 提升至 3w,不仅实现可量化的效率提升和成本优化,更系统化地提升了 AI 研发效率与模型质量。
本文整理自 思必驰数据中台架构师魏凯君在 Doris Summit 2025 中的演讲内容,并以演讲者第一视角进行叙述。
思必驰作为专注于对话式人工智能的平台型企业,围绕“云+芯”战略布局,致力于提供软硬件结合的全链路 AI 产品与服务。在长期服务智能车载、家居等终端场景中,我们积累了海量的多模态训练语料(包含音频、文本及人工标注)。
早期的数据管理方式逐渐成为 AI 研发的瓶颈。各业务团队的标注数据分散在不同的存储系统中,依赖人工进行维护和同步。随着数据规模快速增长至 PB 级别,传统方式在三个方面面临严峻挑战:
- 数据一致性问题:同一份数据在不同团队中存在多个副本,且更新不同步,影响模型训练的一致性。
- 协同效率低下:算法工程师难以快速查找、复用跨团队的数据资产,重复标注与数据准备浪费了大量时间。
- 版本追溯困难:模型迭代时,无法精准关联训练所使用的数据版本,导致问题复现与效果归因困难。
这些问题使得数据资产化与高效协同成为制约 AI 研发规模化的关键。为此,我们决定构建一个统一的数据集管理平台,目标是将原始数据标准化、资产化,打造一个支持高效调用、可靠追溯、安全共享的“AI 数据基座”。
为何是 Apache Doris?
思必驰与 Apache Doris 的合作始于早期技术实践。在 Doris 0.12 版本时期,我们率先将其应用于内部实时数仓场景,并随业务发展,逐步建立起面向外部服务的 Doris 集群,支撑了包括实时看板、用户画像与自助分析在内的多项数据能力。
此外,Doris 在海量业务日志场景(容器日志)中也发挥了关键作用,替代了原有的 Elasticsearch,并基于 Doris 自建日志查询平台,服务智能座舱语音业务。在同等硬件资源下,日志写入性能从原来的 100w/s 提升至 300w/s,存储成本也降低了 50% 以上。
基于 Doris 在性能、成本、稳定性方面的综合优势,在构建数据集平台时,它自然成为数据底座的首选。我们的新场景对数据库提出了更高要求:
- 海量数据去重与高效查询:需处理 10 亿级样本的快速去重与复杂筛选。
- 完善的版本管理:需支持数据集的版本化存储、快速切换与对比。
- 支持向量检索能力:为后续的相似样本检索、特征比对提供支持。
- 高性价比存储:需利用高效压缩与冷热分离,降低 PB 级数据的存储成本。
综合评估,Apache Doris 在满足上述核心需求的同时,其简洁的架构、易用的运维以及活跃的社区,使其成为最优方案。
面向 AI 大规模训练的数据基座
我们采用类 MLOps 理念,设计了贯穿数据-模型-应用的标准化流水线。
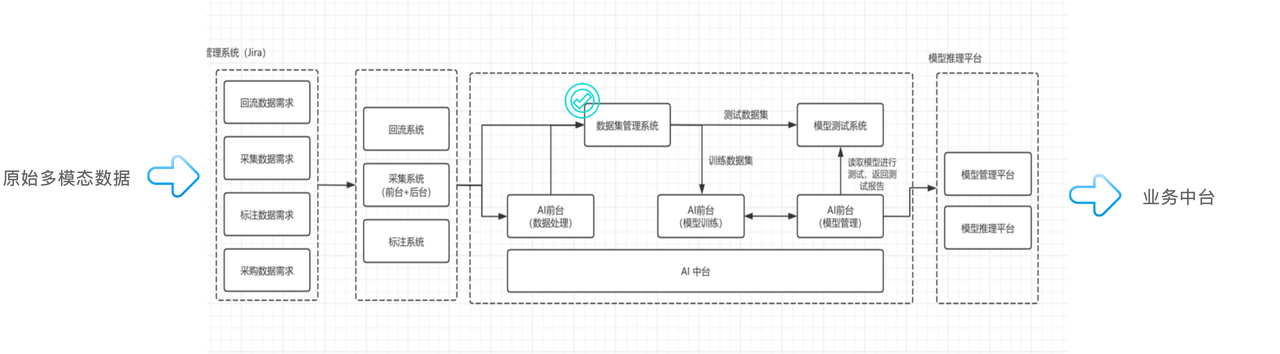
- 数据预处理:原始的多模态数据(语音、文本等)通过采集、回流进入系统,经由专业的标注平台进行加工,再进入 AI 数据前台进行清洗与特征提取。
- **数据集管理系统:**经过预处理的数据,汇入 基于 Apache Doris 构建的数据集管理系统(即本文核心) 。该系统是整个 AI 中台的关键,负责数据的版本化存储、管理与发布,为模型训练与测试提供数据支撑。
- 模型训练及管理:测试数据集进入模型训练系统进行训练,生成的模型经模型管理平台统一管理,最终部署上线,服务于业务应用。
由上图可知,数据集管理系统被囊括在 AI 中台这一架构中。纵观整个 AI 中台,主要包括三个部分:
- 数据管理系统:基于 Apache Doris 和 Elasticsearch 构建,提供页面、客户端和相应的 SDK;
- AI 平台:基于推理与训练框架,以及资源管理与任务调度框架构建;同样提供页面、客户端和 SDK。
- 底层基础设施:涵盖计算层、分布式存储体系及优化后的网络层。
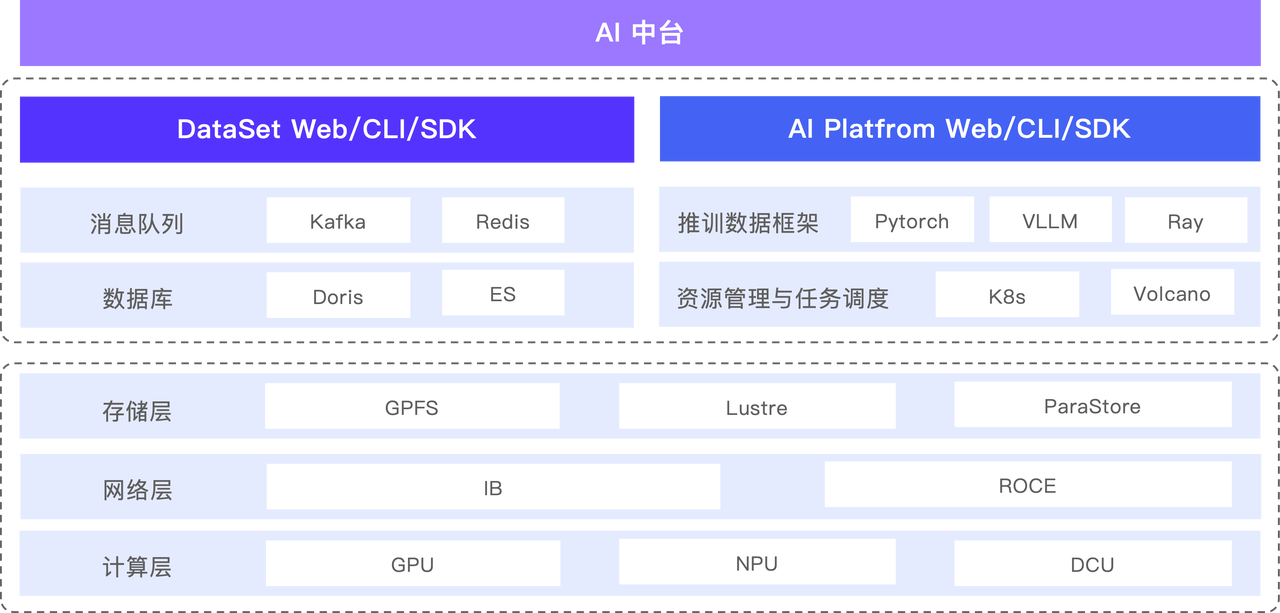
为满足不同业务场景需求,数据集管理 系统设计了单中心和多中心两种部署架构:
- 单中心:面向核心研发场景,数据访问统一指向本中心的 Apache Doris、Elasticsearch、Kafka 及相关文件系统,保证最强的一致性与性能。
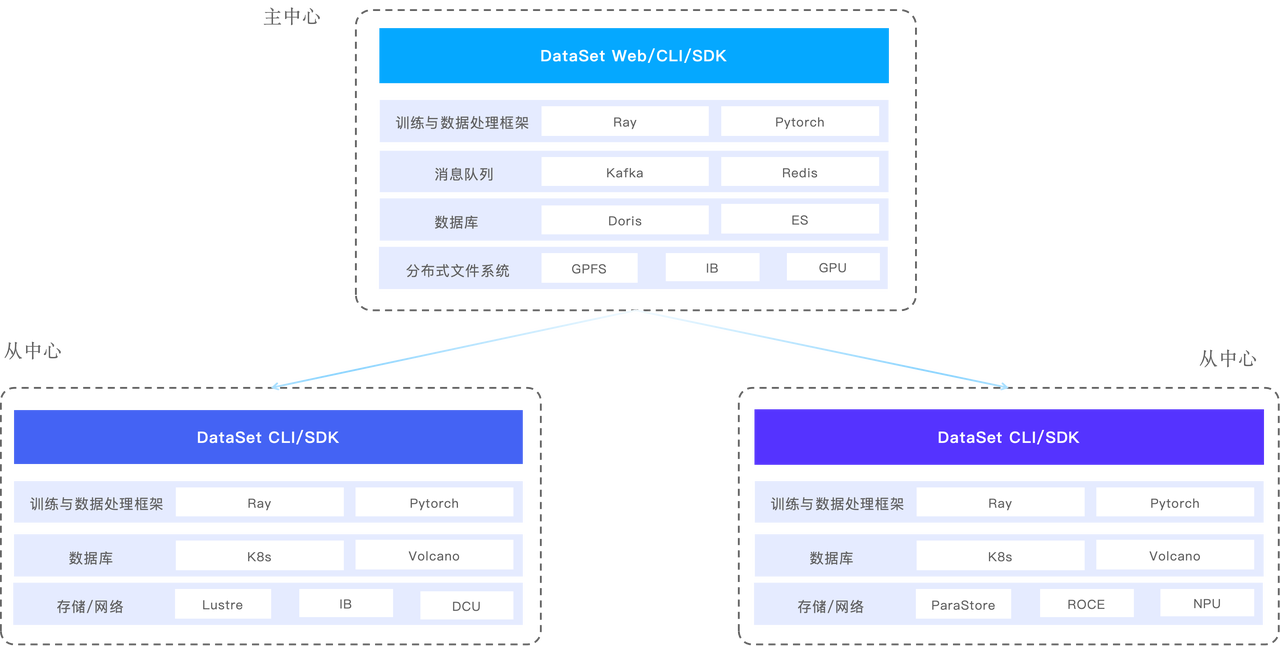
- 多中心:面向跨地域或异构计算资源场景, 采用分布式设计。主中心的数据层使用 Apache Doris,各分中心采用独立的分布式文件系统,这些存储之间可以实现数据的相互同步。针对各个中心的训练任务,系统能够读取这些分布式文件存储中的数据进行训练。
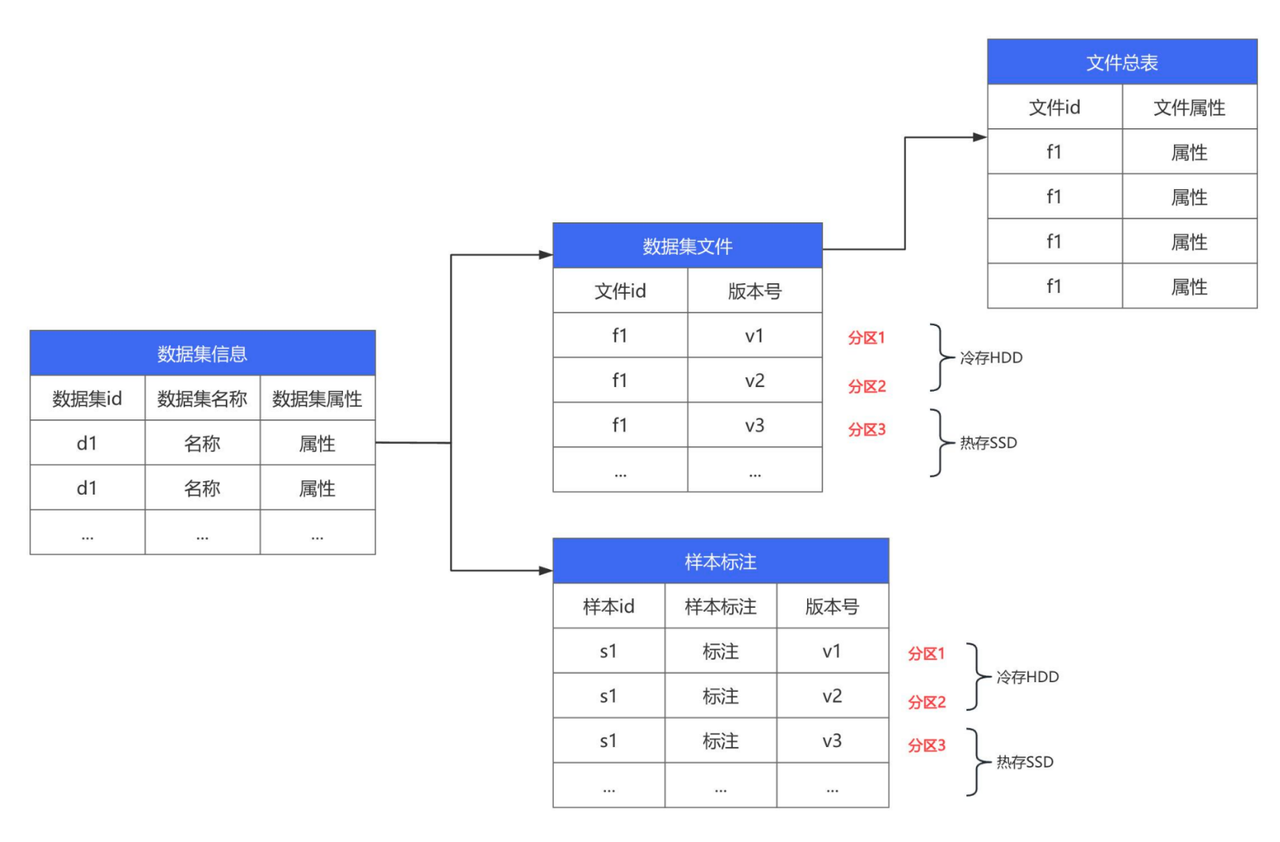
数据版本毫秒级切换,存储占用下降 80%
过去,我们依靠人工在文件系统中维护数据集目录,随着版本激增,混乱与错误难以避免。新平台需要实现类似代码库的版本管理能力(对比、切换、回滚)。
为此,我们利用 Doris 的特性进行改进:
- 列式存储:将标注信息等结构化数据从文本文件迁移至 Doris 表,利用列式存储的高压缩特性,存储空间占用降低 80%以上。
- 分区表实现版本化:以数据集版本作为分区键。最新活跃版本存放在 SSD(热存储),历史版本自动迁移至 HDD(冷存储),SSD 使用率降低 30%以上。
- 表结构设计:核心围绕
数据集表,关联文件表与标注表。通过分区机制,实现了毫秒级的历史版本数据检索与切换。
精准溯源检索,查询 QPS 提升至 3W
为解决模型训练后与原始数据脱节这一核心痛点,数据集平台内置了样本溯源能力。传统的流程在完成特征提取后,往往丢失了原始数据的属性与标注信息,导致两大问题:模型无法关联其“数据血缘”,以及不同模型版本间难以进行有效的对比调优。为此,我们确立了样本 ID 全局唯一的核心要求,以此支撑精准的溯源与检索。
在样本检索实现初期,团队采用 Apache Doris 的 IN 查询方式支撑相关能力,而面对瞬时并发的规模点查请求时,会有明显资源与性能开销,部分节点峰值可达 80%。
为此,团队基于 Apache Doris 的相关能力进行优化,主要采用两类改进:
- 首先,根据“高频点查”这一核心特征,切换至行式存储并优化 I/O 路径,使单次查询更快。
- 其次,通过全面启用预处理语句,将查询计划固定下来,避免了大量的重复计算开销。
优化后,在现有配置下,查询 QPS 提升至 3 万/秒;同时在高频点查询期间,CPU 占用由原先约 80% 降至约 10%,并持续稳定。
平台收益:可量化的效率提升与成本优化
在平台落地后,形成了可量化的建设成效:数据集规模超过 1 万个,数据总量超过 500TB,样本数量超过 10 亿,平台使用人数超过 200 人。通过新旧架构对比,新平台在三个维度带来了显著收益:
- 成本大幅优化:通过消除数据冗余拷贝,存储成本降低 20% 以上,网络成本节约超 3 倍。
- 效率全面提升:数据查询效率提升超 3 倍,数据同步效率提升超 2 倍。
- 研发显著提效:模型研发流程效率提升 20% 以上,且数据集使用得以全面规范。
更重要的是形成了不可替代的隐性价值:
- 统一了数据质量标准:公司内研发、测试、业务团队使用同一套数据和规范,从根本上保障了模型输入的一致性。
- 增强了问题复现能力:任何模型结果均可精准追溯至对应的训练数据集与版本,使得问题调试、效果归因有据可依。
- 实现了流程自动化闭环:结合自动标注系统,实现了从数据回流、清洗、标注到训练的数据闭环,极大提升了 Badcase 的定位与修复效率。
未来规划
基于当前的成功实践,未来我们将继续深化 Apache Doris 的应用,推动数据架构向更先进的方向演进:
- 日志分析场景全面替换:已在 TPS 15 万量级场景完成验证,将加速推进用 Doris 替代 Elasticsearch,预计进一步降低日志处理总成本。
- 拥抱 Doris 4.0 新特性:重点关注并计划升级至 Doris 4.0 版本,利用其向量检索能力,支持更复杂的相似性查询与 AI 原生应用。
- 探索湖仓一体架构:打破数据孤岛,实现数据在数据湖(低成本存储)与数据仓库(高性能分析)间的自由流动与统一管理,支撑 SQL 查询、机器学习等多样化负载。
- 推进存算分离落地:实现计算资源的按需弹性伸缩与负载隔离,并将冷数据沉降至对象存储,在提升资源利用率的同时,追求极致的存储成本效益。


