在数据分析的实际场景中,冷热数据往往面临着不同的查询频次及响应速度要求。例如在电商订单场景中,用户经常访问近 6 个月的订单,时间较久远的订单访问次数非常少;在行为分析场景中,需支持近期流量数据的高频查询且时效性要求高,但为了保证历史数据随时可查,往往要求数据保存周期更为久远;在日志分析场景中,历史数据的访问频次很低,但需长时间备份以保证后续的审计和回溯的工作...往往历史数据的应用价值会随着时间推移而降低,且需要应对的查询需求也会随之锐减。而随着历史数据的不断增多,如果我们将所有数据存储在本地,将造成大量的资源浪费。
为了解决满足以上问题,冷热数据分层技术应运而生,以更好满足企业降本增效的趋势。顾名思义,冷热分层是将冷热数据分别存储在成本不同的存储介质上,例如热数据存储在成本更高的 SSD 盘上、以提高时效数据的查询速度和响应能力,而冷数据则存储在相对低成本的 HDD 盘甚至更为廉价的对象存储上,以降低存储成本。我们还可以根据实际业务需求进行灵活的配置和调整,以满足不同场景的要求。
冷热分层一般适用于以下需求场景:
数据存储周期长:面对历史数据的不断增加,存储成本也随之增加;
冷热数据访问频率及性能要求不同:热数据访问频率高且需要快速响应,而冷数据访问频率低且响应速度要求不高;
数据备份和恢复成本高:备份和恢复大量数据需要消耗大量的时间和资源。
......
更高存储效率的冷热分层技术
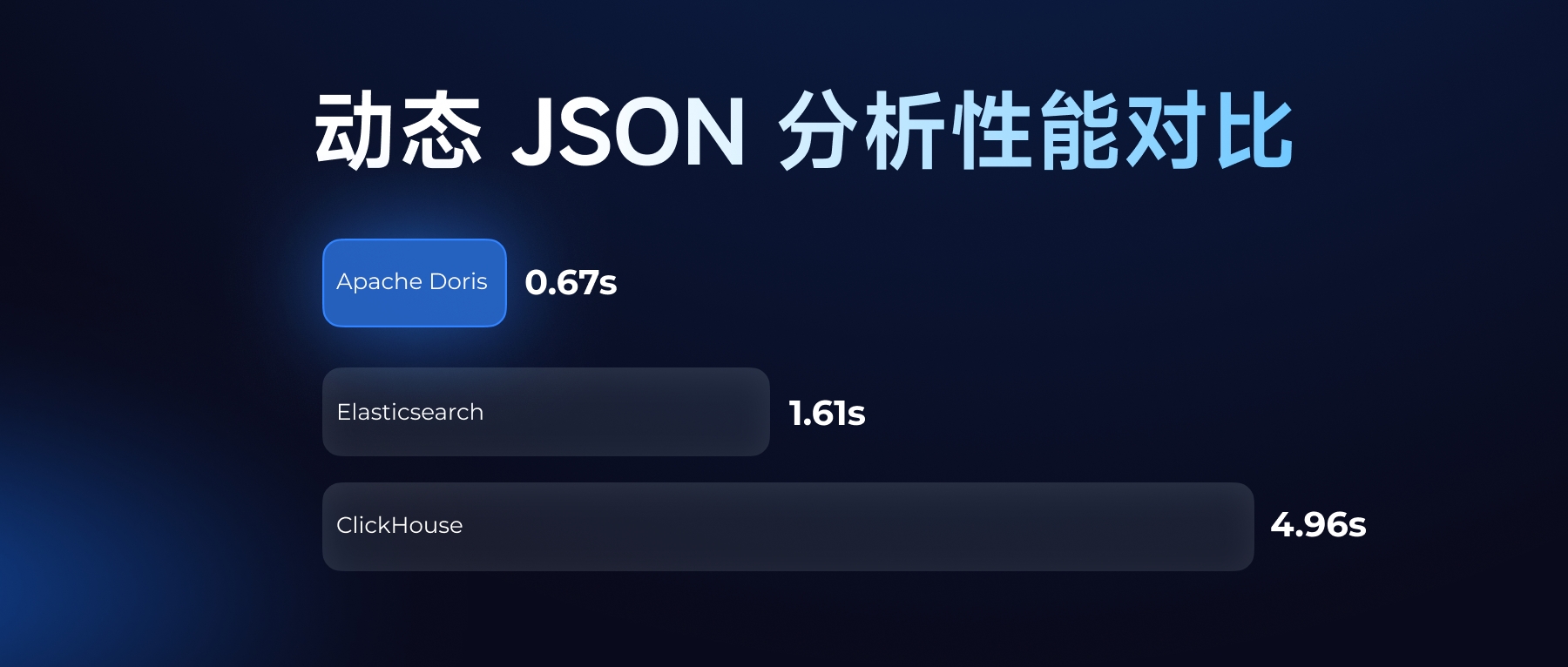
自 Apache Doris 0.12 版本引入动态分区功能,开始支持对表分区进行生命周期管理,可以设置热数据转冷时间以及存储介质标识,通过后台任务将热数据从 SSD 自动冷却到 HDD,以帮助用户较大程度地降低存储成本。用户可以在建表属性中配置参数 storage_cooldown_time 或者 dynamic_partition.hot_partition_num 来控制数据从 SSD 冷却到 HDD,当分区满足冷却条件时,Doris 会自动执行任务。而 HDD 上的数据是以多副本的方式存储的,并没有做到最大程度的成本节约,因此对于冷数据存储成本仍然有较大的优化空间。
为了帮助用户进一步降低存储成本,社区在已有功能上进行了优化,并在 Apache Doris 2.0 版本中推出了冷热数据分层的功能。冷热数据分层功能使 Apache Doris 可以将冷数据下沉到存储成本更加低廉的对象存储中,同时冷数据在对象存储上的保存方式也从多副本变为单副本,存储成本进一步降至原先的三分之一,同时也减少了因存储附加的计算资源成本和网络开销成本。
如下图所示,在 Apache Doris 2.0 版本中支持三级存储,分别是 SSD、HDD 和对象存储。用户可以配置使数据从 SSD 下沉到 HDD,并使用冷热分层功能将数据从 SSD 或者 HDD 下沉到对象存储中。
以公有云价格为例,云磁盘的价格通常是对象存储的 5-10 倍,如果可以将 80% 的冷数据保存到对象存储中,存储成本至少可降低 70%。
我们使用以下公式计算节约的成本,设冷数据比率为 rate,对象存储价格为 OSS,云磁盘价格为 CloudDisk
$1 - \frac{rate * 100 * OSS + (1 - rate) * 100 * CloudDisk}{100 * CloudDisk}$
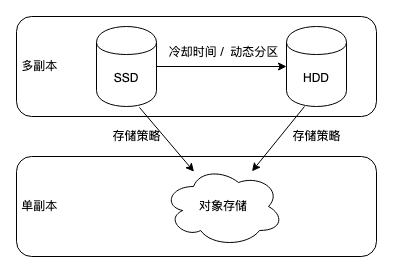
这里我们假设用户有 100TB 的数据,我们按照不同比例将冷数据迁移到对象存储,来计算一下如果使用冷热分层之后,相较于全量使用普通云盘、SSD 云盘可节约多少成本。
- 阿里云 OSS 标准存储成本是 120 元/ T /月
- 阿里云普通云盘的价格是 300 元/ T /月
- 阿里云 SSD 云盘的价格是 1000 元/ T /月
例如在 80% 冷数据占比的情况下,剩余 20% 使用普通云盘每月仅花费 80T120 + 20T * 300 = 15600元,而全量使用普通云盘则需要花费 30000 元,通过冷热数据分层节省了 48% 的存储成本。如果用户使用的是 SSD 云盘,那么花费则会从全量使用需花费的 100000 元降低到 80T120 + 20T * 1000 = 29600元,存储成本最高降低超过 70%!
使用指南
若要使用 Doris 的冷热分层功能,首先需要准备一个对象存储的 Bucket 并获取对应的 AK/SK。当准备就绪之后,下面为具体的使用步骤:
01 创建 Resource
可以使用对象存储的 Bucket 以及 AK/SK 创建 Resource,目前支持 AWS、Azure、阿里云、华为云、腾讯云、百度云等多个云的对象存储。
CREATE RESOURCE IF NOT EXISTS "$\{resource_name}"
PROPERTIES(
"type"="s3",
"s3.endpoint" = "$\{S3Endpoint}",
"s3.region" = "$\{S3Region}",
"s3.root.path" = "path/to/root",
"s3.access_key" = "$\{S3AK}",
"s3.secret_key" = "$\{S3SK}",
"s3.connection.maximum" = "50",
"s3.connection.request.timeout" = "3000",
"s3.connection.timeout" = "1000",
"s3.bucket" = "$\{S3BucketName}"
);
02 创建 Storage Policy
可以通过 Storage Policy 控制数据冷却时间,目前支持相对和绝对两种冷却时间的设置。
CREATE STORAGE POLICY testPolicy
PROPERTIES(
"storage_resource" = "remote_s3",
"cooldown_ttl" = "1d"
);
例如上方代码中名为 testPolicy 的 storage policy 设置了新导入的数据将在一天后开始冷却,并且冷却后的冷数据会存放到 remote_s3 所表示的对象存储的 root path 下。除了设置 TTL 以外,在 Policy 中也支持设置冷却的时间点,可以直接设置为:
CREATE STORAGE POLICY testPolicyForTTlDatatime
PROPERTIES(
"storage_resource" = "remote_s3",
"cooldown_datetime" = "2023-06-07 21:00:00"
);
03 给表或者分区设置 Storage Policy
在创建出对应的 Resource 和 Storage Policy 之后,我们可以在建表的时候对整张表设置 Cooldown Policy,也可以针对某个 Partition 设置 Cooldown Policy。这里以 TPCH 测试数据集中的 lineitem 表举例。如果需要将整张表都设置冷却的策略,则可以直接在整张表的 properties 中设置:
CREATE TABLE IF NOT EXISTS lineitem1 (
L_ORDERKEY INTEGER NOT NULL,
L_PARTKEY INTEGER NOT NULL,
L_SUPPKEY INTEGER NOT NULL,
L_LINENUMBER INTEGER NOT NULL,
L_QUANTITY DECIMAL(15,2) NOT NULL,
L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL,
L_DISCOUNT DECIMAL(15,2) NOT NULL,
L_TAX DECIMAL(15,2) NOT NULL,
L_RETURNFLAG CHAR(1) NOT NULL,
L_LINESTATUS CHAR(1) NOT NULL,
L_SHIPDATE DATEV2 NOT NULL,
L_COMMITDATE DATEV2 NOT NULL,
L_RECEIPTDATE DATEV2 NOT NULL,
L_SHIPINSTRUCT CHAR(25) NOT NULL,
L_SHIPMODE CHAR(10) NOT NULL,
L_COMMENT VARCHAR(44) NOT NULL
)
DUPLICATE KEY(L_ORDERKEY, L_PARTKEY, L_SUPPKEY, L_LINENUMBER)
PARTITION BY RANGE(`L_SHIPDATE`)
(
PARTITION `p202301` VALUES LESS THAN ("2017-02-01"),
PARTITION `p202302` VALUES LESS THAN ("2017-03-01")
)
DISTRIBUTED BY HASH(L_ORDERKEY) BUCKETS 3
PROPERTIES (
"replication_num" = "3",
"storage_policy" = "$\{policy_name}"
)
用户可以通过 show tablets 获得每个 Tablet 的信息,其中 CooldownReplicaId 不为 -1 并且 CooldownMetaId 不为空的 Tablet 说明使用了 Storage Policy。如下方代码,通过 show tablets 可以看到上面的 Table 的所有 Tablet 都设置了 CooldownReplicaId 和 CooldownMetaId,这说明整张表都是使用了 Storage Policy。
TabletId: 3674797
ReplicaId: 3674799
BackendId: 10162
SchemaHash: 513232100
Version: 1
LstSuccessVersion: 1
LstFailedVersion: -1
LstFailedTime: NULL
LocalDataSize: 0
RemoteDataSize: 0
RowCount: 0
State: NORMAL
LstConsistencyCheckTime: NULL
CheckVersion: -1
VersionCount: 1
QueryHits: 0
PathHash: 8030511811695924097
MetaUrl: http://172.16.0.16:6781/api/meta/header/3674797
CompactionStatus: http://172.16.0.16:6781/api/compaction/show?tablet_id=3674797
CooldownReplicaId: 3674799
CooldownMetaId: TUniqueId(hi:-8987737979209762207, lo:-2847426088899160152)
我们也可以对某个具体的 Partition 设置 Storage Policy,只需要在 Partition 的 Properties 中加上具体的 Policy Name 即可:
CREATE TABLE IF NOT EXISTS lineitem1 (
L_ORDERKEY INTEGER NOT NULL,
L_PARTKEY INTEGER NOT NULL,
L_SUPPKEY INTEGER NOT NULL,
L_LINENUMBER INTEGER NOT NULL,
L_QUANTITY DECIMAL(15,2) NOT NULL,
L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL,
L_DISCOUNT DECIMAL(15,2) NOT NULL,
L_TAX DECIMAL(15,2) NOT NULL,
L_RETURNFLAG CHAR(1) NOT NULL,
L_LINESTATUS CHAR(1) NOT NULL,
L_SHIPDATE DATEV2 NOT NULL,
L_COMMITDATE DATEV2 NOT NULL,
L_RECEIPTDATE DATEV2 NOT NULL,
L_SHIPINSTRUCT CHAR(25) NOT NULL,
L_SHIPMODE CHAR(10) NOT NULL,
L_COMMENT VARCHAR(44) NOT NULL
)
DUPLICATE KEY(L_ORDERKEY, L_PARTKEY, L_SUPPKEY, L_LINENUMBER)
PARTITION BY RANGE(`L_SHIPDATE`)
(
PARTITION `p202301` VALUES LESS THAN ("2017-02-01") ("storage_policy" = "$\{policy_name}"),
PARTITION `p202302` VALUES LESS THAN ("2017-03-01")
)
DISTRIBUTED BY HASH(L_ORDERKEY) BUCKETS 3
PROPERTIES (
"replication_num" = "3"
)
这张 Lineitem1 设置了两个分区,每个分区 3 个 Bucket,另外副本数设置为 3,可以计算出一共有 23 = 6 个 Tablet,那么副本数一共是 63 = 18 个 Replica,通过 show tablets 命令可以查看到所有的 Tablet 以及 Replica 的信息,可以看到只有部分 Tablet 的 Replica 是设置了CooldownReplicaId 和 CooldownMetaId 。用户可以通过 ADMIN SHOW REPLICA STATUS FROM TABLE PARTITION(PARTITION)`` 查看 Partition 下的 Tablet 以及Replica,通过对比可以发现其中只有属于 p202301 这个 Partition 的 Tablet 的 Replica 设置了CooldownReplicaId 和 CooldownMetaId,而属于 p202302 这个 Partition 下的数据没有设置,所以依旧会全部存放到本地磁盘。 以上表的 Tablet 3691990 为例,该 Tablet 属于 p202301,截取 show tablets 拿到的部分关键信息如下:
*****************************************************************
TabletId: 3691990
ReplicaId: 3691991
CooldownReplicaId: 3691993
CooldownMetaId: TUniqueId(hi:-7401335798601697108, lo:3253711199097733258)
*****************************************************************
TabletId: 3691990
ReplicaId: 3691992
CooldownReplicaId: 3691993
CooldownMetaId: TUniqueId(hi:-7401335798601697108, lo:3253711199097733258)
*****************************************************************
TabletId: 3691990
ReplicaId: 3691993
CooldownReplicaId: 3691993
CooldownMetaId: TUniqueId(hi:-7401335798601697108, lo:3253711199097733258)
可以观察到 3691990 的 3 个副本都选择了 3691993 副本作为 CooldownReplica,在用户指定的 Resource 上也只会保存这个副本的数据。
04 查看数据信息
我们可以按照上述 3 中的 Linetem1 来演示如何查看是使用冷热数据分层策略的 Table 的数据信息,一般可以通过 show tablets from lineitem1 直接查看这张表的 Tablet 信息。Tablet 信息中区分了 LocalDataSize 和 RemoteDataSize,前者表示存储在本地的数据,后者表示已经冷却并移动到对象存储上的数据。具体信息可见下方代码:
下方为数据刚导入到 BE 时的数据信息,可以看到数据还全部存储在本地。
*************************** 1. row ***************************
TabletId: 2749703
ReplicaId: 2749704
BackendId: 10090
SchemaHash: 1159194262
Version: 3
LstSuccessVersion: 3
LstFailedVersion: -1
LstFailedTime: NULL
LocalDataSize: 73001235
RemoteDataSize: 0
RowCount: 1996567
State: NORMAL
LstConsistencyCheckTime: NULL
CheckVersion: -1
VersionCount: 3
QueryHits: 0
PathHash: -8567514893400420464
MetaUrl: http://172.16.0.8:6781/api/meta/header/2749703
CompactionStatus: http://172.16.0.8:6781/api/compaction/show?tablet_id=2749703
CooldownReplicaId: 2749704
CooldownMetaId:
当数据到达冷却时间后,再次进行 show tablets from table 可以看到对应的数据变化。
*************************** 1. row ***************************
TabletId: 2749703
ReplicaId: 2749704
BackendId: 10090
SchemaHash: 1159194262
Version: 3
LstSuccessVersion: 3
LstFailedVersion: -1
LstFailedTime: NULL
LocalDataSize: 0
RemoteDataSize: 73001235
RowCount: 1996567
State: NORMAL
LstConsistencyCheckTime: NULL
CheckVersion: -1
VersionCount: 3
QueryHits: 0
PathHash: -8567514893400420464
MetaUrl: http://172.16.0.8:6781/api/meta/header/2749703
CompactionStatus: http://172.16.0.8:6781/api/compaction/show?tablet_id=2749703
CooldownReplicaId: 2749704
CooldownMetaId: TUniqueId(hi:-8697097432131255833, lo:9213158865768502666)
除了通过上述命令查看数据信息之外,我们也可以在对象存储上查看冷数据的信息。以腾讯云为例,可以在 Policy 指定的 Bucket 的 Path 下可以查看冷却过后的数据的信息:
进入对应文件后可以看到数据和元数据文件
我们可以看到在对象存储上数据是单副本。
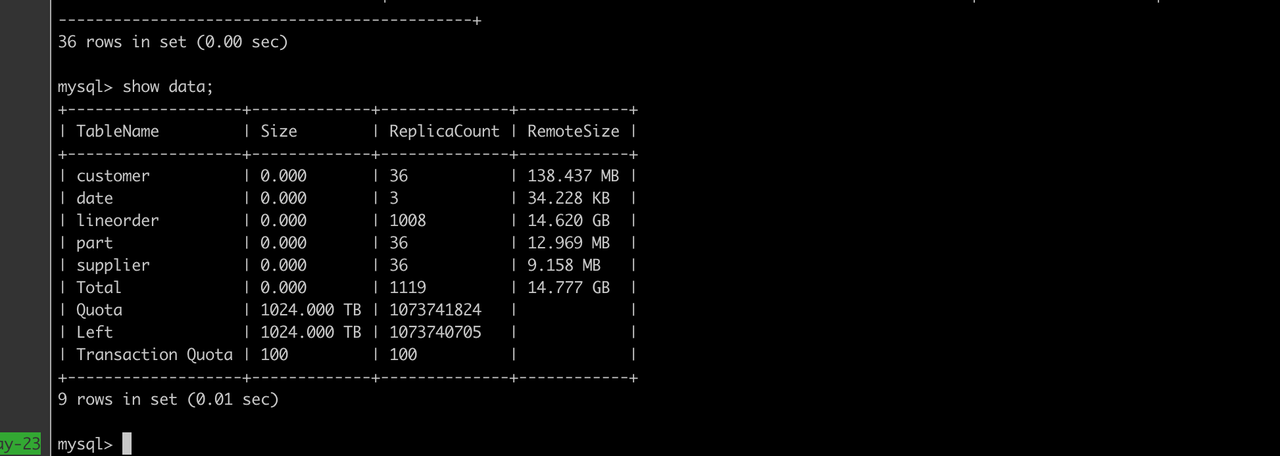
05 查询
假设 Table Lineitem1 中的所有数据都已经冷却并且上传到对象存储中,如果用户在 Lineitem1 上进行对应的查询,Doris 会根据对应 Partition 使用的 Policy 信息找到对应的 Bucket 的 Root Path,并根据不同 Tablet 下的 Rowset 信息下载查询所需的数据到本地进行运算。
Doris 2.0 在查询上进行了优化,冷数据第一次查询会进行完整的 S3 网络 IO,并将 Remote Rowset 的数据下载到本地后,存放到对应的 Cache 之中,后续的查询将自动命中 Cache,以此来保证查询效率。(性能对比可见后文评测部分)。
06 冷却后继续导入数据
在某些场景下,用户需要对历史数据进行数据的修正或补充数据,而新数据会按照分区列信息导入到对应的 Partition中。在 Doris 中,每次数据导入都会产生一个新的 Rowset,以保证冷数据的 Rowset 在不会影响新导入数据的 Rowset 的前提下,满足冷热数据同时存储的需求。Doris 2.0 的冷热分层粒度是基于 Rowset 的,当到达冷却时间时会将当前满足条件的 Rowset 全部上传到 S3 上并删除本地数据,之后新导入的数据生成的新 Rowset 会在到达冷却时间后也上传到 S3。
查询性能测试
为了测试使用冷热分层功能之后,查询对象存储中的数据是否占用会较大网络 I/O,从而影响查询性能,因此我们以 SSB SF100 标准集为例,对冷热分层表和非冷热分层表进行了查询耗时的对比测试。
配置:均在 3 台 16C 64G 的机器上部署 1FE、3BE 的集群
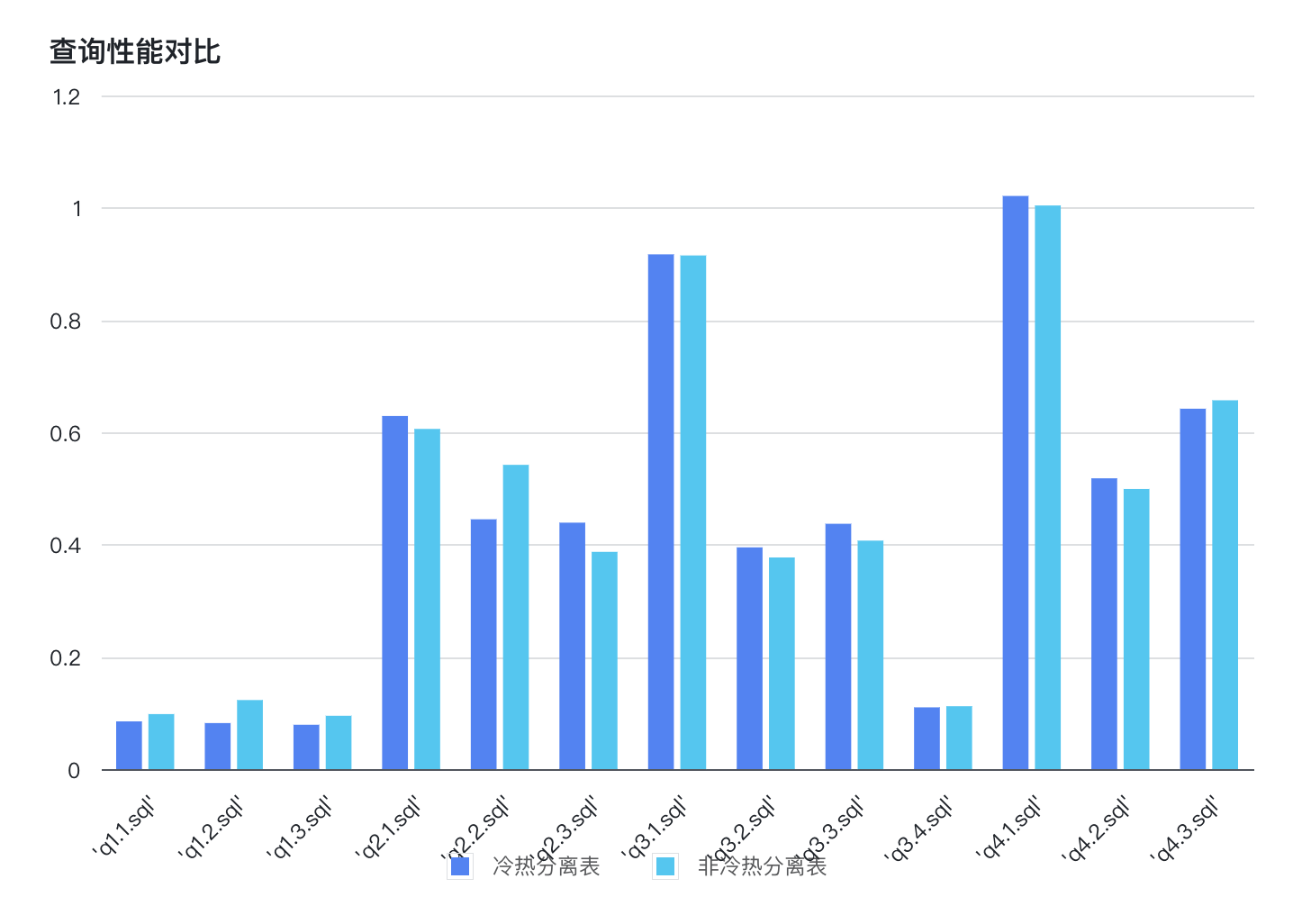
如上图所示,在充分预热之后(数据已经缓存在 Cache 中),冷热分层表共耗时 5.799s,非冷热分层表共耗时 5.822s,由此可知,使用冷热分层查询表和非冷热分层表的查询性能几乎相同。这表明,使用 Doris 2.0 提供的冷热分层功能,不会对查询性能造成的影响。
冷热分层技术的具体实现
01 存储方式的优化
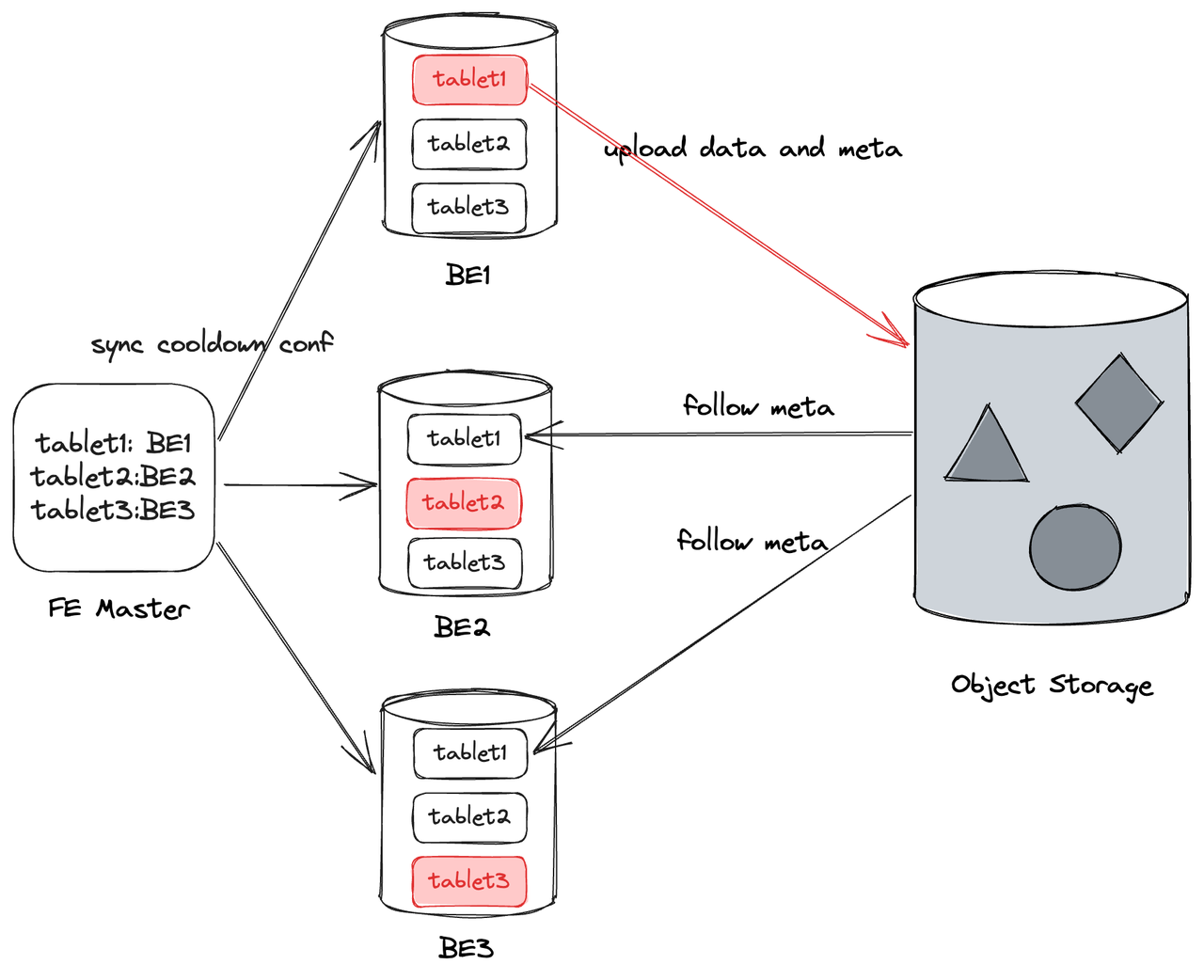
在 Doris 之前的版本中,数据从 SSD 冷却到 HDD 后,为了保证数据的高可用和可靠性,通常会将一个 Tablet 存储多份副本在不同 BE 上,为了进一步降低成本,我们在 Apache Doris 2.0 版本引入了对象存储,推出了冷热分层功能。由于对象存储本身具有高可靠高可用性,冷数据在对象存储上只需要一份即可,元数据以及热数据仍然保存在 BE,我们称之为本地副本,本地副本同步冷数据的元数据,这样就可以实现多个本地副本共用一份冷却数据的目的,有效避免冷数据占用过多的存储空间,从而降低数据存储成本。
具体而言,Doris 的 FE 会从 Tablet 的所有可用本地副本中选择一个本地副本作为上传数据的 Leader,并通过 Doris 的周期汇报机制同步 Leader 的信息给其它本地副本。在 Leader 上传冷却数据时,也会将冷却数据的元数据上传到对象存储,以便其他副本同步元数据。因此,任何本地副本都可以提供查询所需的数据,同时也保证了数据的高可用性和可靠性。
02 冷数据 Compaction
在一些场景下会有大量修补数据的需求,在大量补数据的场景下往往需要删除历史数据,删除可以通过 delete where实现,Doris 在 Compaction 时会对符合删除条件的数据做物理删除。基于这些场景,冷热分层也必须实现对冷数据进行 Compaction,因此在 Doris 2.0 版本中我们支持了对冷却到对象存储的冷数据进行 Compaction(ColdDataCompaction)的能力,用户可以通过冷数据 Compaction,将分散的冷数据重新组织并压缩成更紧凑的格式,从而减少存储空间的占用,提高存储效率。
Doris 对于本地副本是各自进行 Compaction,在后续版本中会优化为单副本进行 Compaction。由于冷数据只有一份,因此天然的单副本做 Compaction 是最优秀方案,同时也会简化处理数据冲突的操作。BE 后台线程会定期从冷却的 Tablet 按照一定规则选出 N 个 Tablet 发起 ColdDataCompaction。与数据冷却流程类似,只有 CooldownReplica 能执行该 Tablet 的 ColdDataCompaction。Compaction下刷数据时每积累一定大小(默认5MB)的数据,就会上传一个 Part 到对象,而不会占用大量本地存储空间。Compaction 完成后,CooldownReplica 将冷却数据的元数据更新到对象存储,其他 Replica 只需从对象存储同步元数据,从而大量减少对象存储的 IO 和节点自身的 CPU 开销。
03 冷数据 Cache
冷数据 Cache 在数据查询中具有重要的作用。冷数据通常是数据量较大、使用频率较低的数据,如果每次查询都需要从对象中读取,会导致查询效率低下。通过冷数据 Cache 技术,可以将冷数据缓存在本地磁盘中,提高数据读取速度,从而提高查询效率。而 Cache 的粒度大小直接影响 Cache 的效率,比较大的粒度会导致 Cache 空间以及带宽的浪费,过小粒度的 Cache 会导致对象存储 IO 效率低下,Apache Doris 采用了以 Block 为粒度的 Cache 实现。
如前文所述,Apache Doris 的冷热分层会将冷数据上传到对象存储上,上传成功后本地的数据将会被删除。因此,后续涉及到冷数据的查询均需要对对象存储发起 IO 。为了优化性能,Apache Doris 实现了基于了 Block 粒度的 Cache 功能,当远程数据被访问时会先将数据按照 Block 的粒度下载到本地的 Block Cache 中存储,且 Block Cache 中的数据访问性能和非冷热分层表的数据性能一致(可见后文查询性能测试)。
具体来讲,前文提到 Doris 的冷热分层是在 Rowset 级别进行的,当某个 Rowset 在冷却后其所有的数据都会上传到对象存储上。而 Doris 在进行查询的时候会读取涉及到的 Tablet 的 Rowset 进行数据聚合和运算,当读取到冷却的 Rowset 时,会把查询需要的冷数据下载到本地 Block Cache 之中。基于性能考量,Doris 的 Cache 按照 Block 对数据进行划分。Block Cache 本身采用的是简单的 LRU 策略,可以保证越是使用程度较高数据越能在 Block Cache 中存放的久。
结束语
Apache Doris 2.0 版本实现了基于对象存储的冷热数据分层,该功能可以帮助我们有效降低存储成本、提高存储效率,并提高数据查询和处理效率。未来,Apache Doris 将会基于冷热数据分层以及弹性计算节点,为用户提供更好的资源弹性、更低的使用成本以及更灵活的负载隔离服务。
在前段时间推出的 Apache Doris 2.0 Alpha 版本中,已经实现了单节点数万 QPS 的高并发点查询能力、高性能的倒排索引、高效稳定的内存管理、基于代价模型的全新查询优化器以及 Pipeline 执行引擎等,欢迎大家下载体验。与此同时, Apache Doris 2.0 Beta 版本也将于近两周上线。除了已知功能外,还会进一步支持 Unique 模型上的部分列更新,并将 Pipeline 执行引擎、查询优化器、主键模型 Merge-on-Write 等最新特性作为稳定功能默认开启,并包含了社区近期对性能方面的诸多优化,详细性能测试结果敬请期待后续社区动态。
为了让用户可以体验社区开发的最新特性,同时保证最新功能可以收获到更广范围的使用反馈,我们建立了 2.0 版本的专项支持群,请大家填写申请,欢迎广大社区用户在使用最新版本过程中多多反馈使用意见,帮助 Apache Doris 持续改进。