
导读:网易云信引入 Apache Doris 统一了原有 Elasticsearch、InfluxDB 和 Hive 多技术栈系统。凭借其高性能和易扩展的特点,提供一站式的数据存储和分析服务。实现机器成本降低 70%、实时场景查询提速 11 倍、离线任务耗时缩短 80% 的显著收益。
网易云信是网易旗下 ToB 的通信与视频云服务品牌,依托网易 20 多年的技术沉淀,为企业和开发者提供稳定、安全、高效的通信与视频云服务,包含 IM 即时通讯、视频云、短信、轻舟微服务、中间件 PaaS 等。截止当前,网易云信产品已覆盖用户 10 亿+,覆盖 196 个国家,覆盖地区 567 个。
云信数据平台承载了多条业务线的数据,数据存储于 Elasticsearch、InfluxDB 和 Hive 这三类主要数据库中,最终为各类业务场景提供数据支撑与服务。但随着业务发展,数据量急剧增加,这种多系统并存的方式带来了高昂的成本和复杂的维护难题。
为解决这些问题,网易云信引入 Apache Doris 统一了原有多技术栈系统。凭借其高性能和易扩展的特点,提供一站式的数据存储和分析服务。实现机器成本降低 70%、实时场景查询提速 11 倍、离线任务耗时缩短 80% 的显著收益。
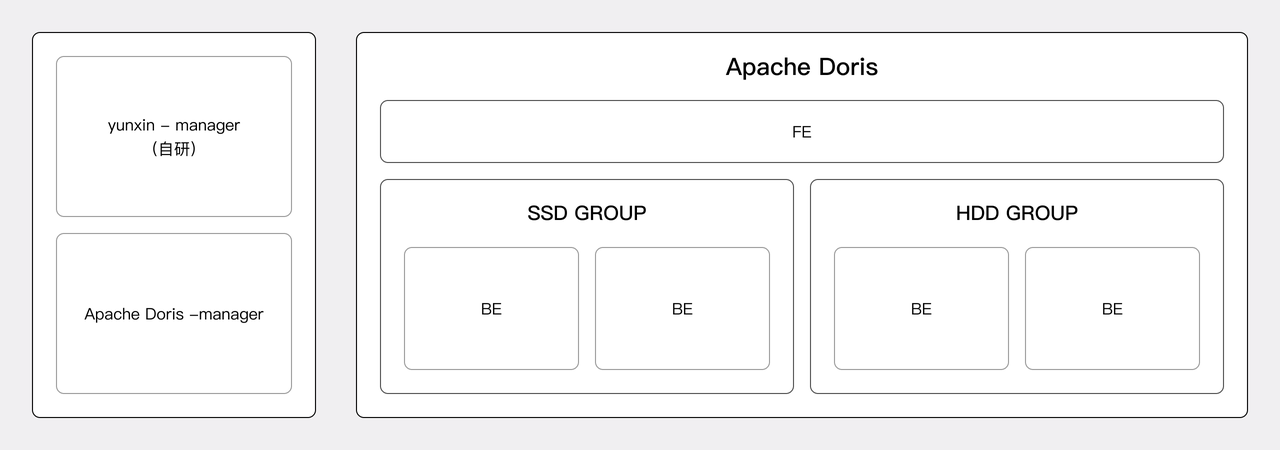
早期架构和挑战
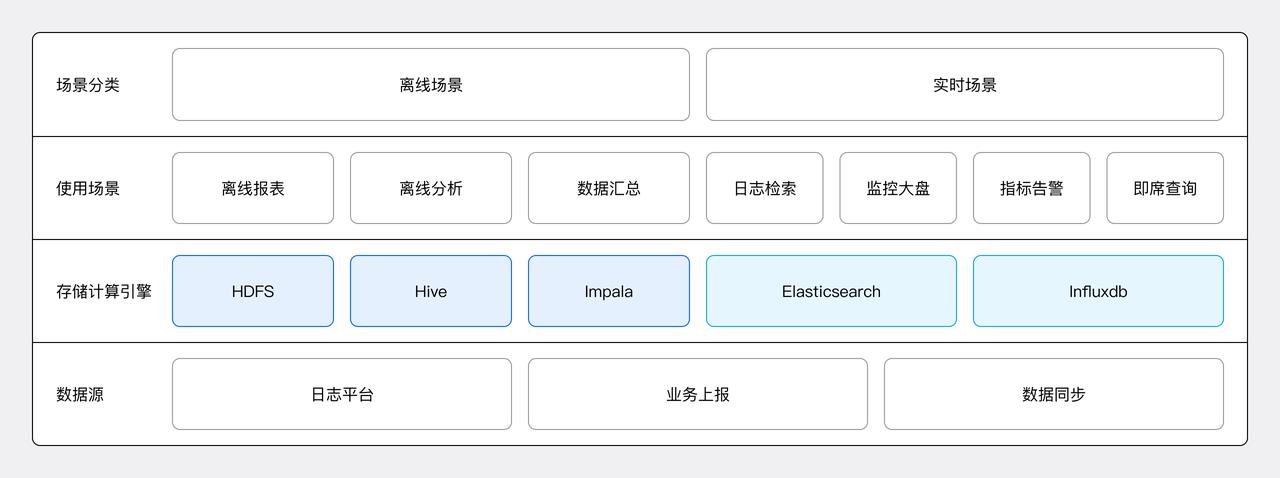
如上图云信数据平台早期架构,IM、RTC、短信、直播、点播等业务数据通过主动上报、日志采集,数据同步等方式上报至数据平台中。数据平台通过流式数据清洗或批处理对数据进行结构化或半结构化计算,并将结果存储到对应的存储计算引擎中,最终服务于多种使用场景。
离线场景下,主要采用 Hadoop 生态的 HDFS、Hive 以及 Impala 进行数据存储与分析;实时日志检索场景中,主要使用 Elasticsearch;而监控类数据则主要存储于 InfluxDB。该架构存在三大痛点:
- 存储冗余: 原有架构为了满足不同场景的数据查询分析需求,数据存储在 InfluxDB、Elasticsearch 和 Hive 多个组件中,同一数据冗余存储,造成存储资源严重浪费。
- 查询效率低: Elasticsearch 的非标准查询语法学习门槛高,且在处理大规模数据时响应慢。InfluxDB 在高基数数据或大量数据序列处理时消耗资源,查询体验不佳。
- 资源抢占严重: Hive 的资源队列紧张,运行效率低,常出现排队现象。InfluxDB 在高并发查询时,写入和查询资源无法隔离,导致写入延迟甚至错误。
Apache Doris 选型思考
基于上述痛点问题,网易云信开始寻找新的解决方案,并期望使用单一数据库服务多种数据服务,满足高效易用、低成本的升级及使用要求。
01 Doris 核心优势
经过探索,Apache Doris 符合我们的选型要求。其具备以下优势:
- 统一存储:Doris 具备替代 InfluxDB、Elasticsearch、Hive 等多种数据库的能力,仅需存储一份数据,实现数仓查询出口的统一,可实现数倍存储成本的降低。
- 实时 OLAP 能力:Doris 是一款基于 MPP 架构的高性能、实时的分析型数据库,强调即时数据分析,具备优秀的并发查询能力,能支持高并发点查询和高吞吐复杂分析场景。
- 冷热分层优势:借助 Doris 冷热分层功能,既能满足近期热点数据的查询性能,又能将历史数据冷备在便宜的存储介质中,实现查询性能和存储成本的平衡。
02 Doris vs ClickHouse
调研 Doris 的同时,我们也关注到了 ClickHouse,两个系统的关键点对比如下。
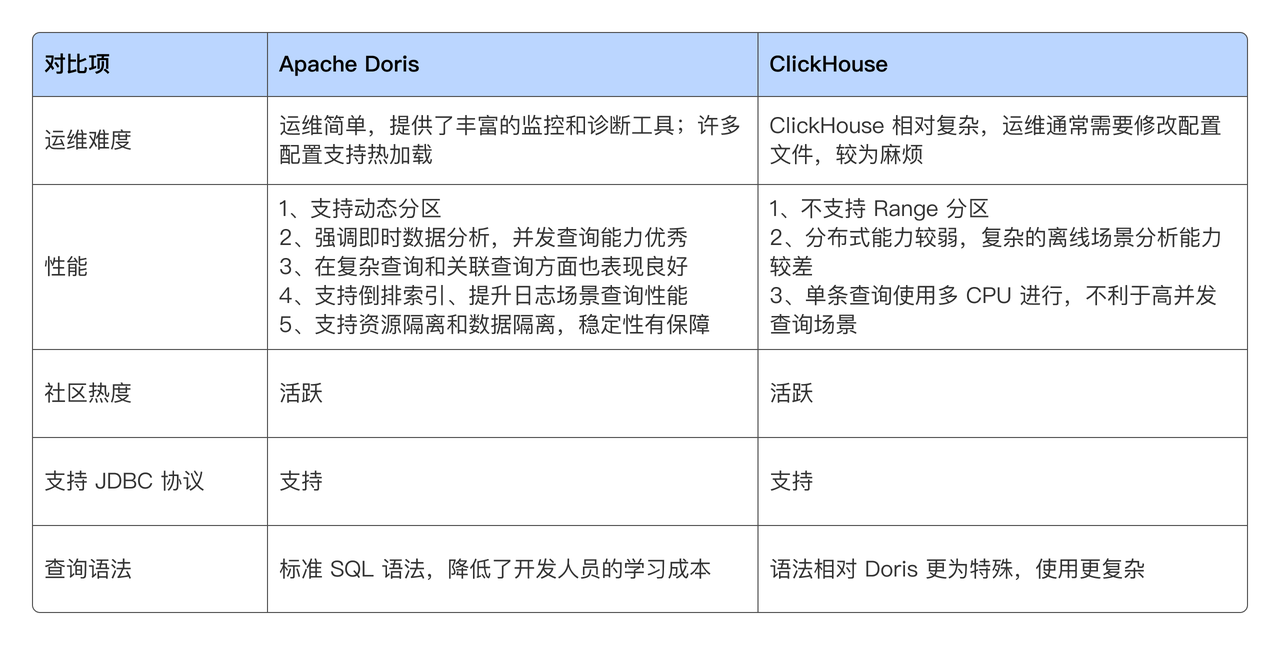
Doris 具备运维简单、丰富的监控与诊断工具,以及支持配置热加载等优势,支持倒排索引和全文检索,适用于高并发实时分析、监控数据处理和日志分析等场景。它支持动态分区,简化数据接入流程。采用标准 SQL 语法并支持 MySQL 协议,降低了开发人员的学习成本。
统一高效的新架构
综合以上优势,网易云信将 Apache Doris 作为全新架构核心引擎,对原架构的存储计算引擎进行替换和统一,包括 InfluxDB、Elasticsearch、Hive 等多种存储系统。升级后,所有处理后的统一存储在 Doris 中,由其为各使用场景提供服务,降低了数据存储和系统运维的成本。

同时,借助 Doris 冷热分层能力,进一步优化了存储成本。之前使用 Hive 处理半结构化数据时,由于采用 HDD 存储且缺乏索引,查询效率较低。现在切换到 Doris 之后,前一天的数据存储在 SSD 上并构建了索引,离线分析效率显著高于原先 HDFS + Hive 组合。
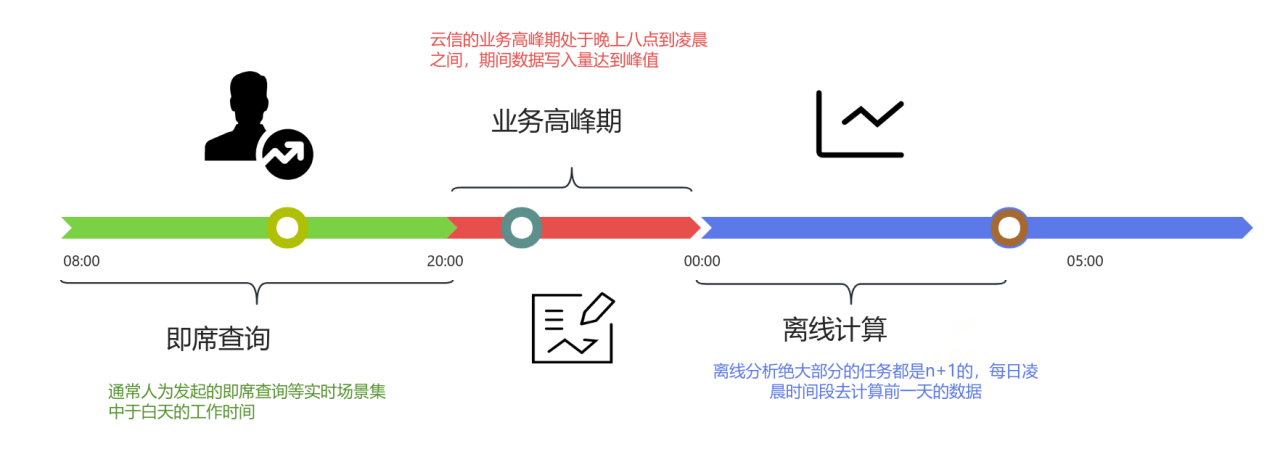
此外,通过合并离线和在线集群和分时段资源调度机制,我们实现了计算资源的高效利用。白天(开发人员活跃期)集中承载数据查询分析需求,晚高峰时段(20:00-00:00)则全力支持云信业务峰值写入。离线计算任务通常安排在凌晨(00:00 之后)进行,用于处理前一天的数据(即 T+1 模式)。这种机制确保了从日间到夜间的计算能力全覆盖,使计算资源全天候高效运转,大幅提升了资源利用率。
落地实践
在业务迁移的过程中,网易云信也遇到一些问题及挑战。借此机会,将这些宝贵的优化经验整理并分享,希望对大家的使用有所指引及帮助。
01 写入优化
云信 - 数据平台在业务高峰期时,面临着百万级别以上的写入 TPS 以及高吞吐写入流量,这对系统性能提出了极高的要求。
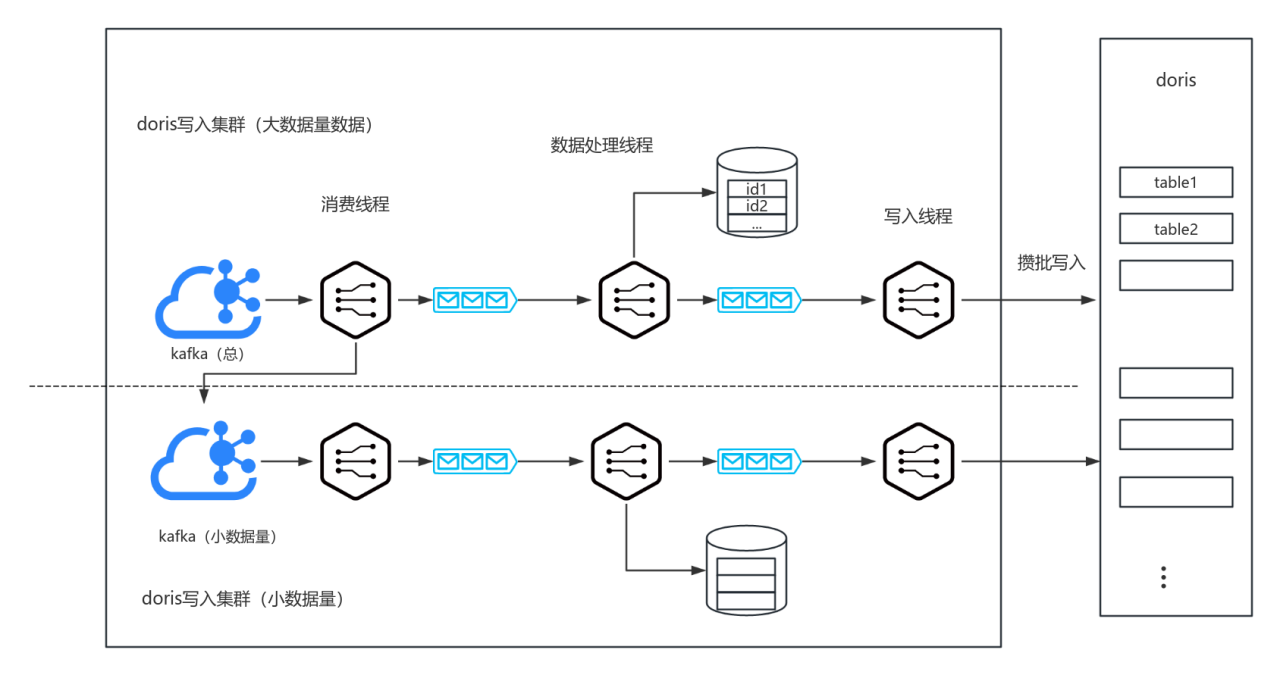
经过多年的发展,云信已积累了大量数据源,不同的数据源分别写入 Doris 中对应一张表,提升 Doris 写入吞吐的关键在于提高攒批,而 Stream Load 仅支持单表批量数据写入,大量的数据源将造成写入服务为每个数据源分别攒批,导致内存消耗大。
为解决这一问题,我们尝试使用 HashMap 作为底层集合进行数据聚合,但在多线程环境下会引发哈希冲突。于是改用数组作为底层集合进行批量聚合,成功避免了哈希冲突,并支持进程内横向扩展线程数,可有效提升数据处理的能力。但若 Doris 端出现波动或业务量激增,写入端仍可能面临压力。 虽然通过扩容可以提升整体吞吐量,但可能导致数据分散,降低批量聚合效果。例如,原本可以聚合 1000 条数据一次性发送,现在可能只能聚合 100 条,增加了 Doris 数据处理的压力。
为此,我们进一步优化,将同一数据源的数据集中在一个写入集群内处理,非本集群的数据则投递到其他 Topic,由对应集群进行消费。这种方式提升了批量聚合能力,缓解了写入过程中小文件过多的问题,从而降低了 Doris Compaction 的压力。在数据格式上,将原本的 JSON 格式改为 CSV,并结合 GZIP 压缩,显著降低了带宽和内存的消耗。
最终,经过这些优化,线上写入峰值已达 600 万 QPS,集群总写入带宽最大达到 11GB/s,稳定控制在实际可承受范围内,整体运行非常平稳。
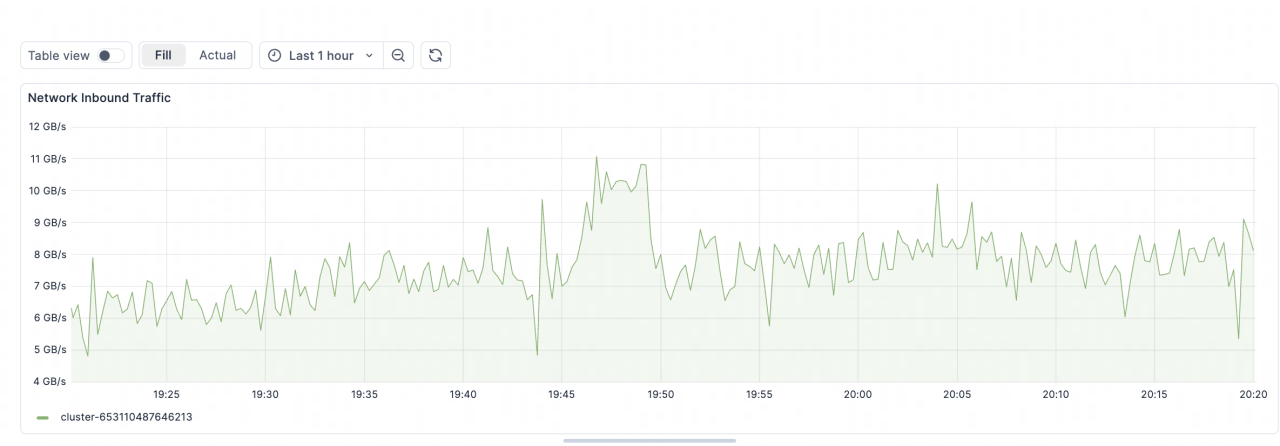
02 稳定性保障
为了确保上层业务的顺利迁移和数据库的稳定运行,我们采取了多重保障措施,包括资源隔离、集群隔离和 UDF 开发。这些措施旨在优化资源分配,减少不同业务之间的干扰,提升系统的整体性能和安全性。
- 资源隔离: 资源隔离主要应用于在线读、离线读、风险读这几类场景中,根据在线场景、离线场景以及风险账号的不同类型,设置多个资源组,确保不同资源组之间的用户互不影响,提升系统的稳定性和安全性。在线读的频次较高,但大多为简单查询;离线读的频次较低,主要为复杂查询,因此分配的内存和 CPU 资源相对较多;风险读是容易导致 Doris 抖动的高风险查询,实际应用中分配的资源较少。详细使用可参考:https://doris.apache.org/zh-CN/docs/admin-manual/workload-management/workload-group
- 数据隔离: 当前线上环境包含两类业务,数据源和业务类型各不相同。目前线上环境采用的是同一集群内的 BE Group 进行隔离,实现两个业务的数据隔离,且两个业务的写入服务和 Doris BE 节点是互相隔离的。这样既保证了资源的高效利用,也实现了多业务的并行承载。可参考:https://doris.apache.org/zh-CN/docs/admin-manual/workload-management/resource-group
- UDF 开发和应用: 用户从文件中读取数据并维护一个静态 HashMap 字典后,可以通过传入 Key 作为参数来返回 Value 作为查询结果。由于 Doris 中 的 JAR 包是按需加载的,只有在真正执行时才会加载到 JVM 中,执行完毕后则会卸载。当字典数据庞大且并发较高时,每个实例独立加载一份会显著增加内存占用。为此,我们选择提前将读取文件维护字典进行拆分,并打包字典生成 JAR,将其放入
custom_lib中,使其能够在 BE 启动时由 JVM 加载。这样,可以在全局只维护一个实例,避免频繁的加载和释放,有效节约内存资源。
03 自动化运维体系
自动化运维是我们管理服务的核心能力之一,特别体现在动态分区和自动降冷功能上。借助配置中心和定时任务,能够动态调整 Doris 表的配置,例如分区分桶数的设置、历史数据迁移至冷备集群的时间以及未来分区大小的设置等。这些自动化运维能力极大地简化了 Doris 数据存储的管理,提高了系统的灵活性和效率。
动态分区管理:
Doris 支持范围分区,但仅支持日期列的 Range 分区,不支持按照业务量动态调整分区大小。在查询时,必须指定日期才能正确定位到分区,这对查询效率造成了一定影响。此外,业务上有一些数据表数据量非常大,尽管尝试使用自动指定桶数量的配置,但仍存在一定问题。
当前做法:将 Bucket 的数据控制在 1G ~ 5G 之间,执行 SQL 每天自动删除过期分区,并创建未来分区。根据业务量自动创建和调整分区大小;可以通过配置中心在表级维度控制存储时长;使用时间戳字段进行分区,查询时方便指定分区,提高查询效率。
自动降冷策略:
Doris 提供了自动降冷的功能,但由于我们的备件库中混用 2.5 和 3.5 的插槽机器数量较少,且大部分 HDD 为 3.5 英寸,因此未使用其提供的方案。
我们利用现有的大量 3.5 英寸备用 HDD 硬盘,新搭建了一批专用的 BE 节点,并将这些节点的 TAG 标签设置为 "cooldown"。随后,我们每天会将历史分区的 TAG 设置为 "cooldown",这样 Doris 就会自动将这些分区的数据调度迁移到成本较低的冷备节点 BE 中,实现了冷数据的高效存储和管理,还可对冷备资源进行归一化管理,方便弹性扩缩容。
示例: yunxin-manager 每天定时查询配置信息,根据配置信息,设置需要降冷分区的replication_allocation 属性到 HDD Group:
ALTER TABLE lps_bucket.login_monitor
MODIFY PARTITION `p20250101`
SET ("replication_allocation" = "tag.location.cooldown:2");
04 InfluxDB 迁移
建表 SQL 参考:
CREATE TABLE `new_mediaServer_transport` (
`partitionTime` date NULL,
`appid` bigint NULL,
`cid` varchar(65533) NULL,
`osType` varchar(65533) NULL,
`sampleTime` bigint NULL,
`sdkVersion` varchar(65533) NULL,
`serverIp` varchar(65533) NULL,
`transportId` varchar(65533) NULL,
`recvBitrate` bigint NULL,
INDEX idx_time (`lps_event_time`) USING INVERTED,
INDEX idx_appid (`appid`) USING INVERTED,
INDEX idx_cid (`cid`) USING INVERTED,
INDEX idx_uid (`uid`) USING INVERTED,
INDEX idx_partitionTime (`partitionTime`) USING INVERTED,
INDEX idx_transportId (`transportId`) USING INVERTED,
INDEX idx_serverIp (`serverIp`) USING INVERTED
) ENGINE=OLAP
DUPLICATE KEY(`partitionTime`)
PARTITION BY RANGE(`partitionTime`)
(
PARTITION p20250614 VALUES [('2025-06-14'), ('2025-06-15')),
PARTITION p20250615 VALUES [('2025-06-15'), ('2025-06-16')),
PARTITION p20250616 VALUES [('2025-06-16'), ('2025-06-17')))
DISTRIBUTED BY RANDOM BUCKETS AUTO
PROPERTIES (
"replication_allocation" = "tag.location.default: 2",
"min_load_replica_num" = "1",
"compression" = "ZSTD",
"compaction_policy" = "time_series"
);
InfluxDB 查询 SQL 参考:
SELECT
mean("recvBitrate")
FROM
"new_mediaServer_transport"
WHERE
("cid" = '$cid'
AND "uid" =~ /^$uid$/
AND producing = 'true')
AND $timeFilter)
GROUP BY
time($__interval),
"uid",
"type",
"tag_localHostName"
fill(none)
Apache Doris 查询 SQL 参考:
SELECT
avg(recvBitrate) as 'PubTransportRecvBitrate',
(CEIL(`lps_event_time`) DIV (1 * 1000)) * 1 as time,
uid,
type,
localHostName as tag_localHostName
FROM
lps_doris_bucket.new_mediaServer_transport
WHERE
( cid = '$cid'
AND uid rlike $uid
AND producing = 'true')
AND lps_event_time > $__unixEpochFrom() * 1000
AND lps_event_time < $__unixEpochTo() * 1000
GROUP BY time, uid, type, tag_localHostName
ORDER BY
time
应用收益
原集群配置与引入 Doris 后的集群配置对比如下:
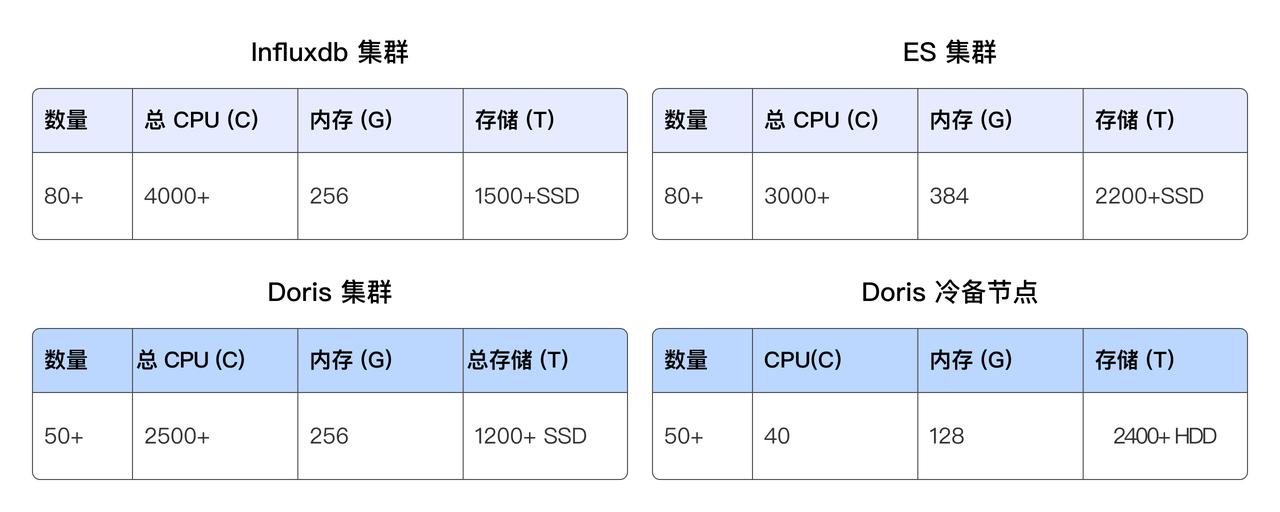
成本优化:存储资源降低 70%
- 引入 Doris 后, 通过统一存储提高了 SSD 存储的利用率,避免了多套存储系统带来的资源浪费。当前 Doris 使用的物理机存储成本降低约 70%(以前的冷备存在 HDFS 中,此处未列出,因此仅计算 Doris SSD 存储部分)。
成本优化:计算资源降低 40% ~ 70%
- 在离线场景,按照 CPU/核 * s 计算,节省了 40% 的计算资源(当前还在持续改造中)。
- 在实时场景,使用 Doris 替换 InfluxDB 与 Elasticsearch 集群,总体 CPU 核数降低了约 70%。
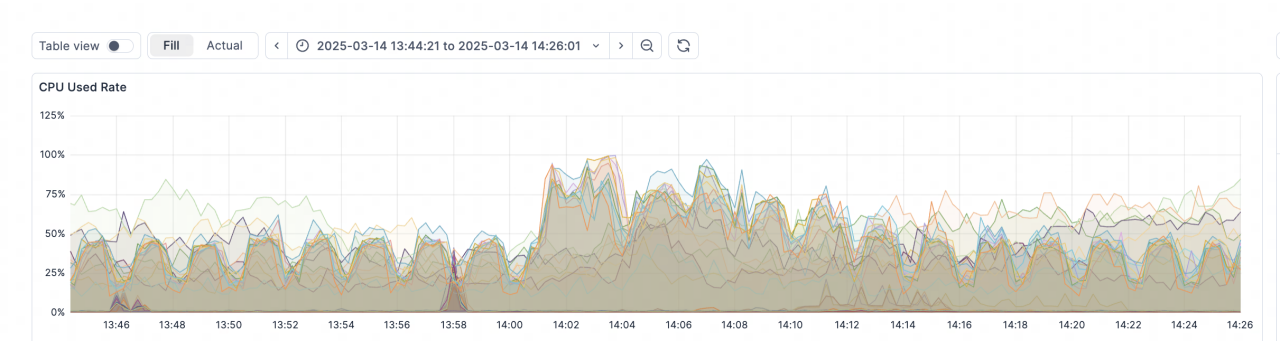
效率提升:查询响应
离线任务耗时:
离线任务相对于 Hive,运行时间平均降低 80% 以上,消灭了所有小时级别的任务。
实时场景耗时:
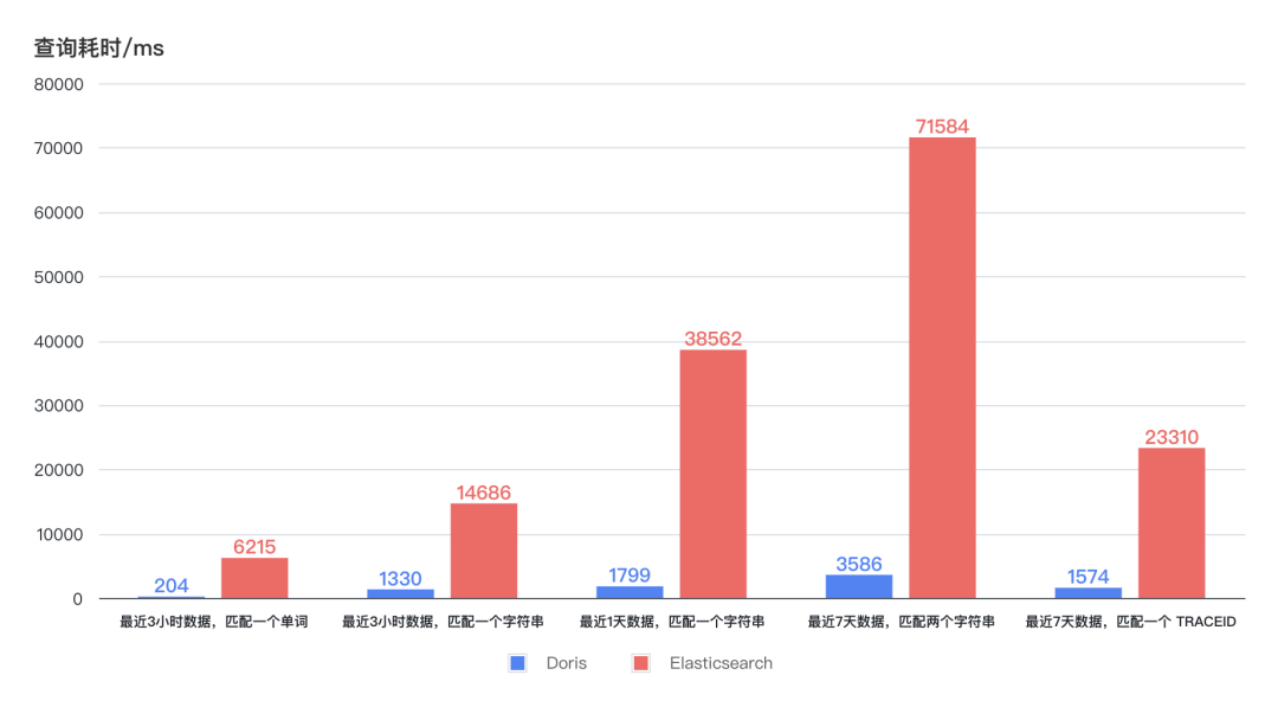
在日志检索场景中,最近 3 小时、1 天 、7 天的日志检索,Doris 查询耗时保持稳定且均低于 4s,最快可在 1s 内响应。而 Elasticsearch 查询耗时呈现出较大的波动,最长耗时高达 75s,即使最短耗时也需要 6-7s。在更低的资源占用下,Doris 的查询效率至少是 Elasticsearch 的 11 倍。
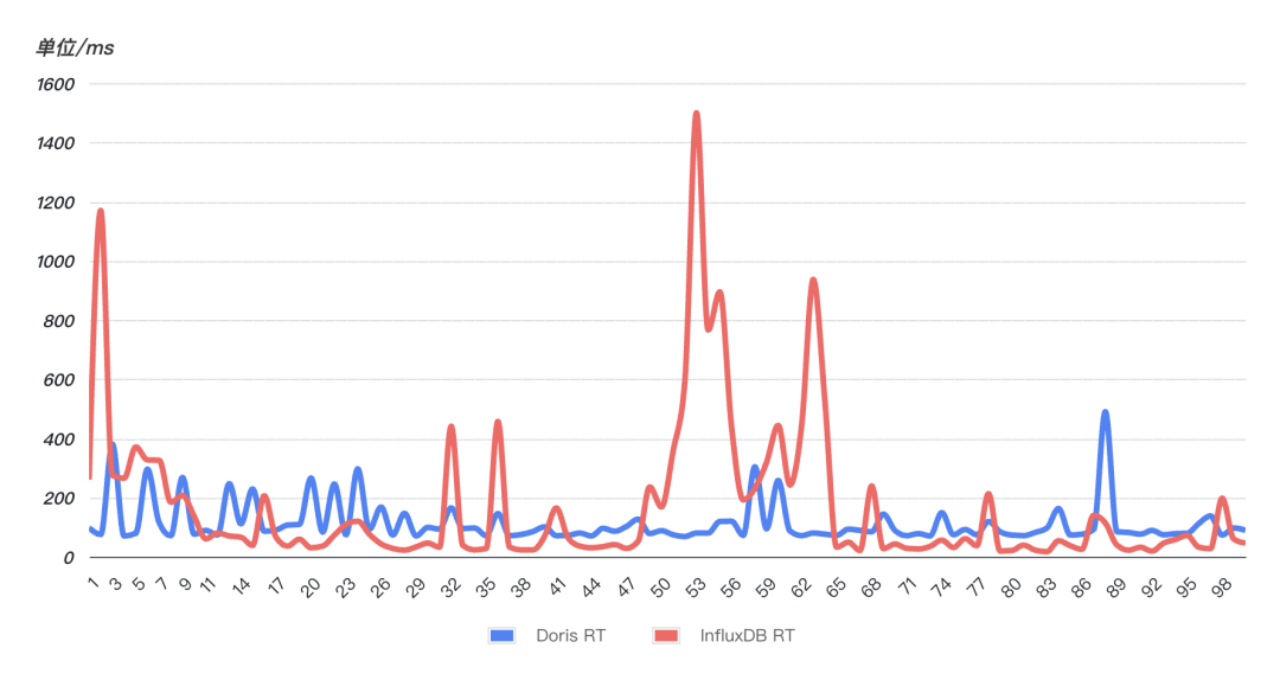
在高频次实时查询场景中, InfluxDB 出现多次异常波动,查询耗时直线上升,查询稳定性受到严重影响,Doris 的查询性能比 InfluxDB 更稳定,99 次查询均比较平稳、没有明显波动。
未来规划
未来,我们将深入挖掘 Doris 的价值,探索其在其他场景中的应用:
- 湖仓一体的应用:进一步拓展联邦查询功能,整合多个数据源,打破数据孤岛。以联邦查询为基础,创建一个统一的分析入口,用户无需在多个数据源间切换,即可实时分析各类数据。
- 借助大模型搭建能效工具:借助 Doris 和大模型,实现交互式的可视化分析和智能可视化报表生成,搭建内部专业知识库。
- 深入了解 Doris:紧跟 Doris 社区动态,结合云信业务的使用反哺社区,为 Doris 的健康发展提供助力。


