日志分析作为获取系统运行信息、排查故障、优化性能的重要手段,已广泛应用于各个领域。为了满足运维可观测、网络安全监控以及业务分析的多重需求,企业通常需要构建日志存储与分析平台,将分散在各个系统及设备的日志收集起来,进行集中存储并提供检索和分析服务。而日志数据所具备的几大特性,无疑为日志存储与分析平台带来巨大的挑战。
一、日志分析的常见问题
数据量大,存储成本高:日志数据规模通常非常庞大,且其生产周期星现不间断的也特点,特别是在中大型企业中,每天产生的日志数据在10~100TB 级别。为了满足业务需求或符合监管要求,日志数据往往需要存储半年甚至更长时间,存储总量经常达到 PB 级别,产生高昂的存储成本。而随着时间的推移,日志数据的价值也在逐渐下降,因此对于日志系统来说,存储成本也变的更加敏感;
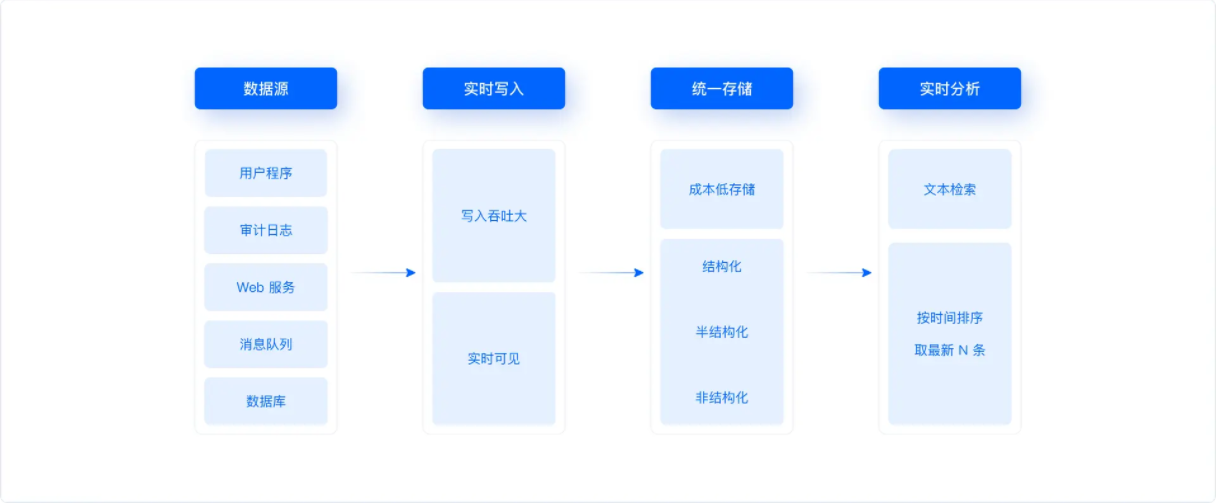
高吞吐实时写入:面对每天10~100TB 新增数据,要求平台具备GB/s、百万条/s的高吞吐写入能力,以应对持续迅猛增长的数据;同时,考虑到日志数据常用于故障排查、安全追踪等时效要求很高的场景,还要求平台保证秒级写入延迟,确保呆数据的实时性和可用性;
实时文本检索:日志数据中有大量的文本,如何在其中快速检索关键词和短语是该场景的核心需求。由于日志数据规模庞大,传统的全量扫描和字符串匹配方式在性能上往往无法达达到实时响应的要求,特别是在上述高吞吐低延迟实时写入的前提下,实时文本检索更加困难。因此,构建针对文本的索引成为实现秒级查询响应的关键;
Flexible Schema:日志数据最初始的表现形态为非结构化原始日志,以 FreeText 的形式存在;随着技术的发展,进一步产生了以JSON 为主的半结构化日志,日志生成者可以自主增减JSON字段,其数据的 Schema 非常灵活。然而,传统严格的数据库和数据仓库在处理这种灵活模式的数据时显得力不从心,而数据湖系统虽然在存储方面提供了较大的灵活性,但在处理性能和实时性方面却难以满足分析需求;
安全性问题:日志中往往包含大量的敏感信息,如用户密码、交易数据等。如何确保日志数据的安全性,防止数据泄露和滥用,是日志分析过程中必须考虑的问题。
二、基于SelectDB的日志存储与分析解决方案
SelectDB 是基于 Apache Doris 构建的现代化数据仓库,采用 MPP 分布式架构,结合向量化执行引擎、CBO 优化器、丰富的索引以及物化视图等先进技术,支持大规模实时数据上的极速查询分析,为用户提供极速的查询分析体验。经过持续的技术创新和迭代, SelectDB 已经在单表 ClickBench、多表TPC-H、TPC-DS 等多个权威分析型数据库性能评测中获得全球领先甚至第一的成绩。
SelectDB 不拘泥于传统数仓的限制,针对日志场景的特点,增加了倒排索引以及极速全文检索能力,实现了写入性能和存储空间极致优化,使用户可基于 SelectDB 构建开放、高性能、低成本、统一的日志存储分析平台。
写入性能方面: Elasticsearch 写入的性能瓶颈在于解析数据和村沟建倒排索引的CPU消耗。相比之下, Doris 进行了两方面的写入优化:一方面利用 SIMD 等 CPU 向量化指令提升了 JSON 数据解析速度和索引构建性能;另一方面针对日志场景简化倒了排索引结构,去掉日志场景不需要的正排等数据结构,有效降低了索引构建的复杂度。同样的源,SelectDB 的写入性能是 Elasticsearch 的3~5倍。
存储性能方面:Elasticsearch 存储瓶颈在于正排、倒排、Docvalue 列存多份存储和通用压缩算法压缩率较低。相比之下,Doris 在存储上去掉正排,缩减了30%的索引数据量;采用列式存储和 ZSTD 压缩算法,压缩比可达到5-10倍,远高于 Elasticsearch 的1.5倍;此外,针对日志数据中访问频率很低的冷数据,SelectDB 冷热分层功能可以将超过定义时间段的日志自动存储到更低的对象存储中,冷数据的存储成本可降低70%以上。同样规模的原始数据,SelectDB 的存储成本仅为 Elasticsearch 的20%。
查询性能方面:SelectDB 简化了全文检索流程,跳过相关性打分等日志场景不相关的算法,从而实现基础检索性能的加速。同时,针对日志场景常见的的查询,比如查询包含某个关键字的最新100条日志,SelectDB 在查询规划和执行上进行了专门的 TopN 动态剪枝等优化,确保查询效率达到最佳状态。
Flexible Schema 方面:
下面是一个典型的 JSON 格式半结构化日志样例。顶层字段没为固定的字段,如日志时间戳 timestamp ,日志来源source ,日志所在机器node,打日志的模块 component ,日志级别 level ,客户端请求标识 clientRequestld ,日志内容message ,日志扩展属性 properties 这些属性基本每条日志均会有。而扩展属性 properties 的内部嵌套字段properties .size properties .format 等是比较动态的,每条日志的字段可能不一样。
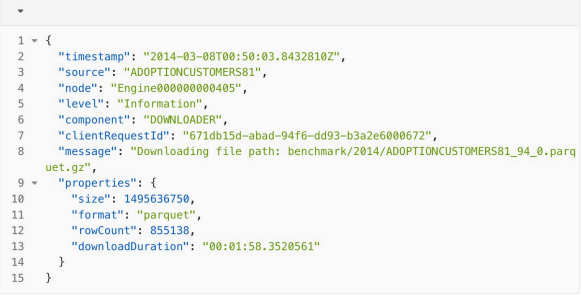
SelectDB 对灵活 Schema 的日志数据提供了几个方面的支持:
对于顶层字段的少量变化,可以通过 Light Schema Change 发起ADD / DROP COLUMN 增加/删除列、ADD/DROP INDEX 增加/删除索引,完成秒级 Schema 变更。用户在日志平台规划时只需考虑当前需要为哪些字段创建索引。
对于类似 properties 的扩展字段,SelectDB提供了原生半结构化数据类型 VARIANT ,支持写入任意 JSON 数据,可自动识别 JSON 中的字段名和类型,并自动拆分频繁出现的字段进行列式存储,以便于后续的分析,还可以对 VARIANT 创建倒排索引,加快内部字段的查询和检索。
相对于 Elasticsearch Dynamic Mapping ,SelectDB 的 Flexible Schema 有下面一些优势:
允许一个字段有多种类型, VARIANT 自动对字段类型做冲突处理和类型提升,更好的适应日志数据的迭代变化;
避免字段、元数据、列过多导致性能问题,VARIANT 自动将不频预繁出现的字段合并成一个列存储;
不仅可以动态加列,还可以动态删列、动态增加索引、动态删索引、无需像 Elasticsearch 在一开始对所有字段建索引,减少不必要的成本。
三、SelectDB 日志存储与分析方案优势
通过下面的图,我们从几个日志场景的关键点来对比几个典典型的方案:

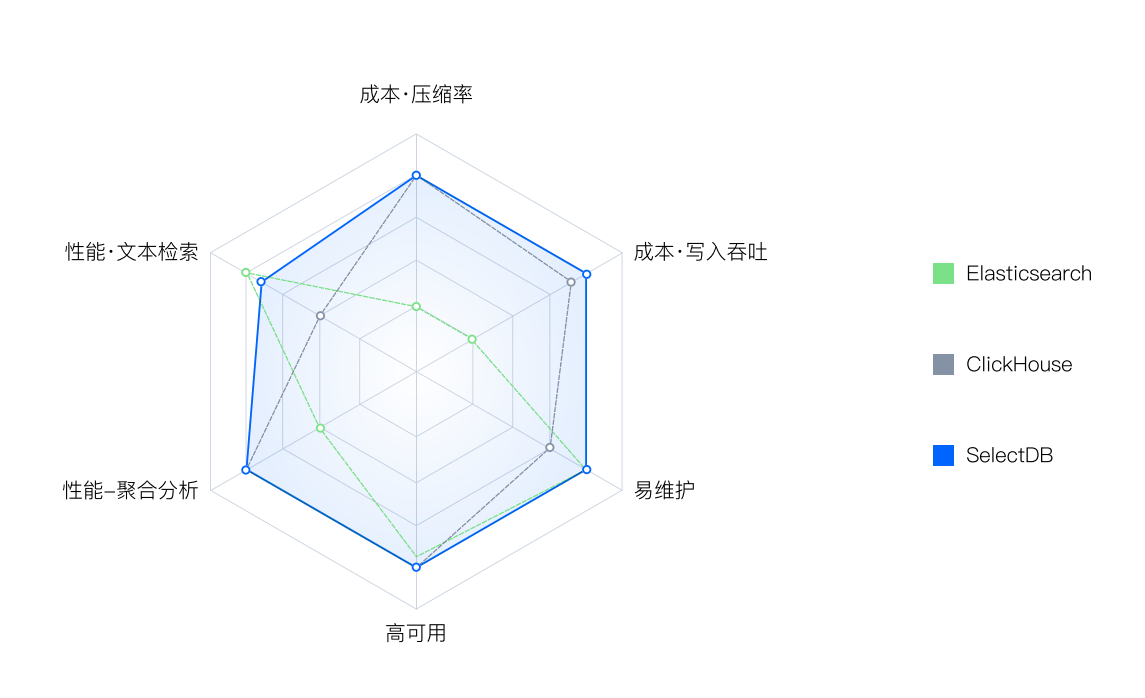
日志分析在大数据时代具有重要的作用和价值。通过引入分布式处理框架、使用日志解析工具、采用实时分析技术和加强安全控制等措施,我们可以有效地解决日志分析中的常见问题并提高其效率和准确性。同时,通过选择合适的日志存储、备份与恢复、索引与查询以及可视化与分析工具等方案来优化日志的处理和分析流程将为我们带来更多的价值和便利。
