数据湖(Data Lake)是一种大型数据存储和处理系统,它以其独特的方式存储和管理数据,为企业提供了高效、灵活的数据处理能力。以下是对数据湖的简单介绍:
数据湖概念
数据湖是一个以原始格式存储数据的存储库或系统,它能够容纳各种类型和格式的数据,包括结构化数据(如关系数据库中的表)、半结构化数据(如CSV、日志、XML、JSON)和非结构化数据(如电子邮件、文档、PDF)以及二进制数据(如图形、音频、视频)。这种存储方式使得企业能够集中管理和利用大量的数据资源。
数据湖查询分析场景挑战
企业大量业务数据分散于多种大数据组件与数据库系统,数量庞大且格式多样,数据处理链路冗长,为业务人员快速洞察数据价值带来挑战,数据孤岛的存在还进一步加大了数据治理的难度,当前环境下通常有以下四大挑战:
1、数据时效性差
数据架构复杂、数据处理链路冗长、湖上数据迁移带来额外的时间成本,用户无法及时获取最新数据进行分析;
2、多数据源管理困难
不同数据源之间缺乏统一的视图管理和权限控制、管理口径不一致,带来居高不下的维护成本和数据安全隐患;
3、查询性能与并发瓶颈
现有查询引擎无法满足用户对湖上数据的低延迟和高并发查询需求,阻碍数据广泛应用和价值充分释放;
4、数据开放性不足
传统解决方案采用专有格式进行数据存储,使数据在上下游之间的共享变得困难重重,降低了数据资产在企业内部的流通性。
SelectDB 的数据湖查询分析解决方案
针对于以上四大挑战 SelectDB 给出了自己的解决方案(下图为架构图):
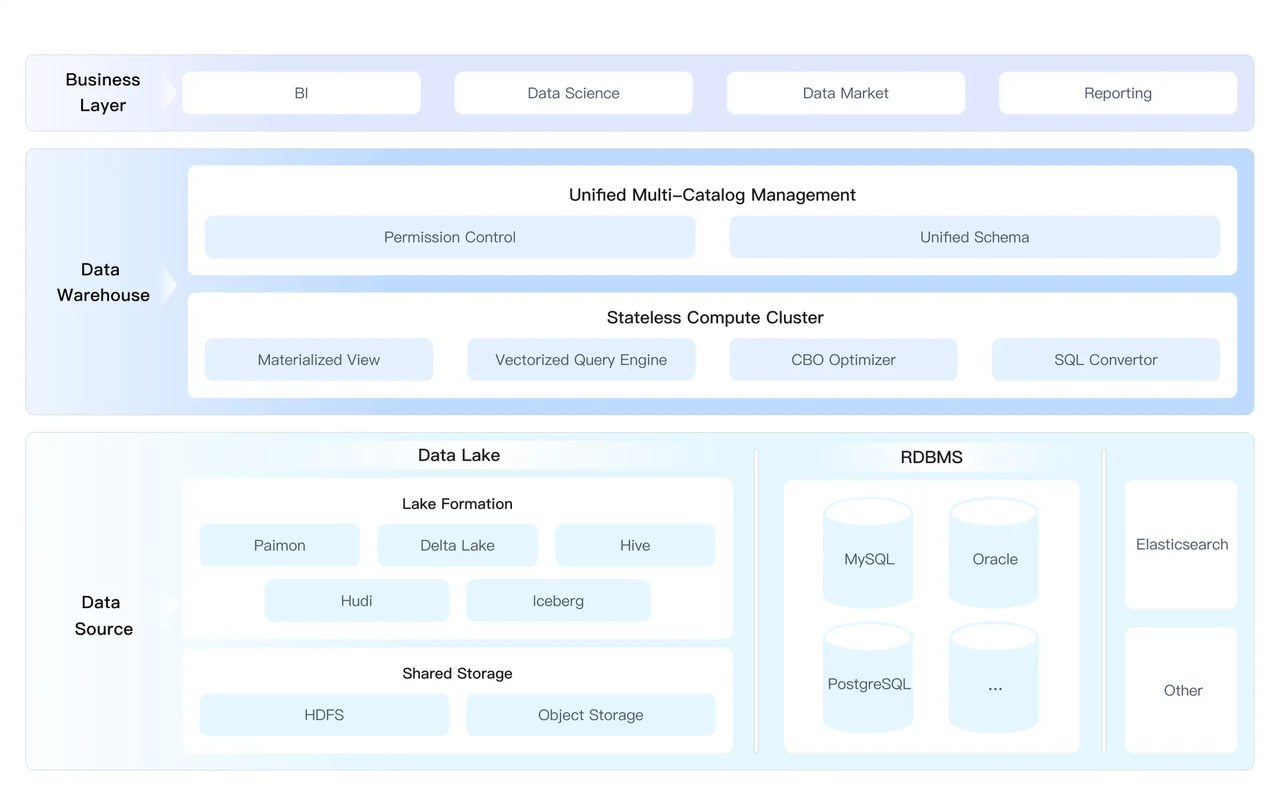
1、湖仓查询加速:无需数据迁移,可直接对湖上数据进行查询分析。借助物化视图、向量化查询引擎以及基于代价的现代化查询优化器,提供比同类产品快 3-5 倍的查询加速效果;
2、统一数据管理:支持灵活接入各种数据源,提供统一的数据权限管理和 Schema 管理,并支持通过标准的 SQL 语言进行数据分析,让多数据源管理变得简单而高效;
3、跨数据源联邦分析:提供高性能的跨数据源联邦分析能力,可以快速对业务数据库、数据湖以及各种异构存储系统进行实时数据分析。
4、开放数据生态:利用开放数据格式、高速数据写入和读取通道,打破数据壁垒,使数据能够在不同上下游系统中自由流转和共享。
SelectDB 的数据湖查询分析解决方案案例分享:
天眼查基于 Apache Doris 构建统一实时数仓,秒级数据写入,毫秒查询响应
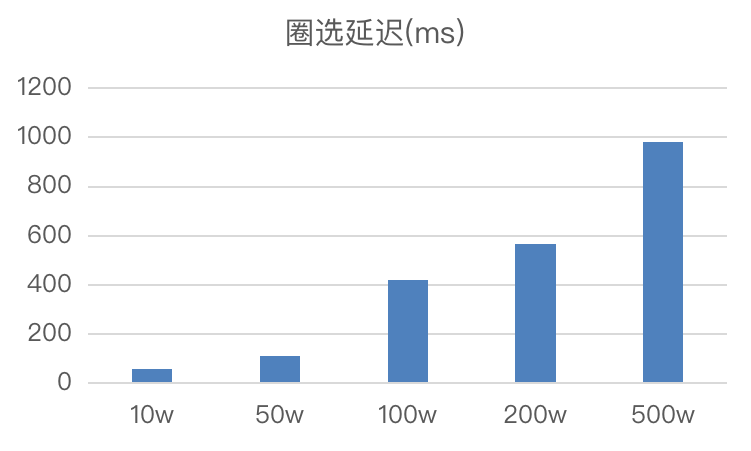
导读: 随着天眼查近年来对产品的持续深耕和迭代,用户数量也在不断攀升,业务的突破更加依赖于数据赋能,精细化的用户/客户运营也成为提升体验、促进消费的重要动力。在这样的背景下正式引入 Apache Doris 对数仓架构进行升级改造,实现了数据门户的统一,大大缩短了数据处理链路,数据导入速率提升 75 %,500 万及以下人群圈选可以实现毫秒级响应,收获了公司内部数据部门、业务方的一致好评。
原有架构痛点:
- 开发流程冗长:体现在数据处理链路上,比如当面对一个简单的开发需求,需要先拉取数据,再经过 Hive 计算,然后通过 T+1更新导入数据等,数据处理链路较长且复杂,非常影响开发效率。
- 不支持即席查询:体现在报表服务和人群圈选场景中,所用的指标无法根据条件直接查询,必须提前进行定义和开发。
- T+1 更新延迟高:T+1 数据时效性已经无法提供精确的线索,主要体现在报表和人群圈选场景上。
- 运维难度高:原有架构具有多条数据处理链路、多组件耦合的特点,运维和管理难度都很高。
业务需求:
天眼查的数据仓库主要服务于三个业务场景,每个场景都有其特点和需求,具体如下:
- 亿级用户人群圈选: 人群圈选场景中目前有 100+ 人群包,我们需要根据 SQL 条件圈选人群包,来支持人群包的交并差、人群包实时圈选和人群包更新通知下游等需求。例如:圈选出下单未支付超过 5 分钟的用户,我们通过用户标签可以直观掌握用户支付状态,为运营 & 营销团队提供更精细化的人群管理服务,从而提高转化率。
- 多元活动支撑的精准营销: 该场景目前支持了 1000 多个指标,可支持即席查询,根据活动效果及时调整运营策略。例如在“开工季”活动中,需要为数据分析 & 运营团队提供数据支持,从而生成可视化的活动驾驶舱。
- 高并发的 C 端分析数据: 该场景承载了 3 亿+实体(多种维度)的数据体量,同时要求实时更新,以供用户进行数据分析。
Doris 解决方案
采用 Doris 对原有架构进行升级优化,并在架构层级进行了重构。新的架构图如下所示:
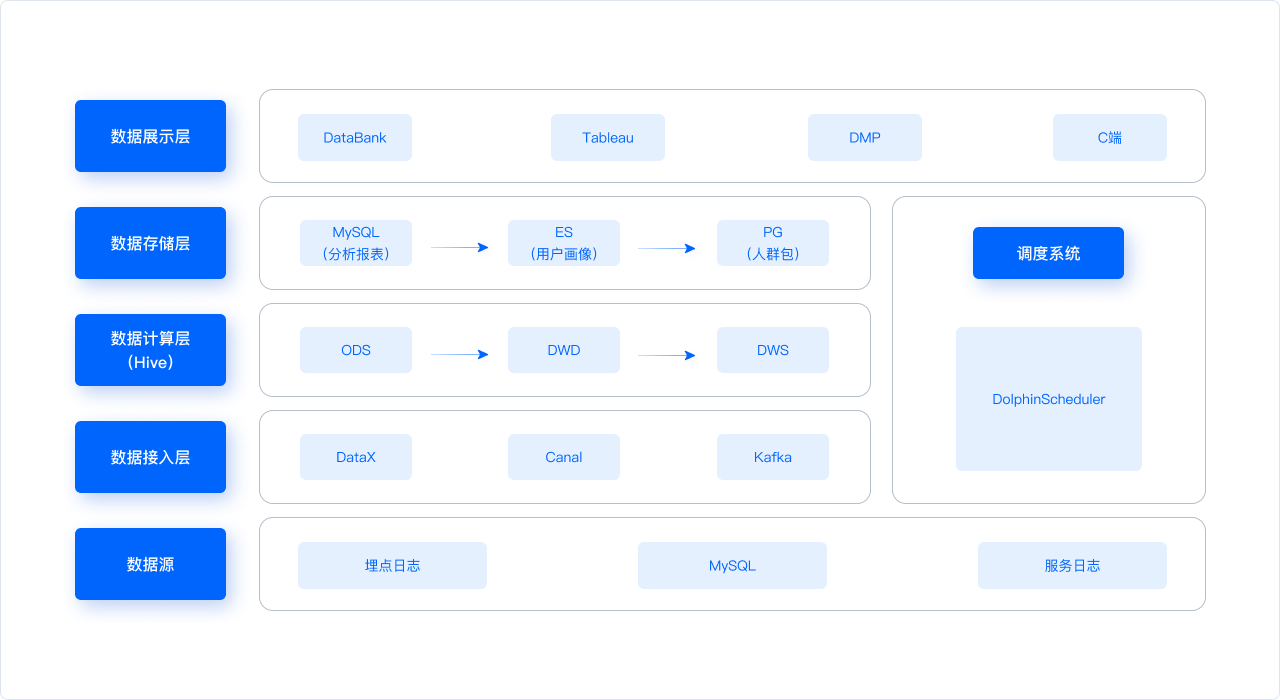
在新架构中,数据源层和数据接入层与原有架构保持一致,主要变化是将 Doris 作为新架构的数据服务层,统一了原有架构中的数据计算层和存储层,这样实现了数据门户的统一,大大缩短了数据处理链路,解决了开发流程冗长的问题。 同时,基于 Doris 的高性能,实现了即席查询能力,提高了数据查询效率。另外,Flink 与 Doris 的结合实现了实时数据快速写入,解决了 T+1 数据更新延迟较高的问题。除此之外,借助于 Doris 精简的架构,大幅降低了架构维护的难度。
收益总结:
Doris 的引入满足了业务上的新需求,解决了原有架构的痛点问题,具体表现为以下几点:
- 降本增效: Doris 统一了数据的门户,实现了存储和计算的统一,提高了数据/表的复用率,降低了资源消耗。同时,新架构优化了数据到 MySQL、ES 的流程,开发效率得到有效提升。
- 导入速率提升: 原有数据流程中,数据处理流程过长,数据的导入速度随着业务体量的增长和数据量的不断上升而急剧下降。引入 Doris 后,我们依赖 Broker Load 优秀的写入能力,使得导入速率提升了 75%以上。
- 响应速度:Doris 的使用提高了各业务场景中的查询响应速度。例如,在人群圈选场景中,对于 500 万及以下的人群包进行圈选时,能够做到毫秒级响应。