数据仓库技术作为数据管理的核心工具,帮助企业更高效地存储、处理和分析海量数据。从技术发展和应用角度来看,数仓可以分为实时数仓和离线数仓。那么,这两种数仓有何区别,各自的优势又是什么呢?在这之前先需要了解一下它的工作流程!
数仓的工作流程
- 数据采集:从各种业务系统中收集数据,包括结构化、半结构化和非结构化数据。
- 数据清洗:对采集到的数据进行预处理,如去重、填充缺失值、纠正错误等,确保数据质量。
- 数据整合:将清洗后的数据按照一定规则整合到数据仓库中,形成统一的数据集。
- 数据存储:选择适当的存储方式(如分布式存储)来存储数据,同时确保数据的备份和恢复机制。
- 数据加工:根据业务需求对数据进行进一步的处理和分析,如数据聚合、转换、去噪等。
- 数据展示:利用报表、图表等工具将数据以直观的方式展示给决策者,支持其进行业务分析和决策。
- 持续维护:数据仓库需要定期更新和维护,以确保数据的时效性和准确性。
什么是实时数仓?
实时数仓是一种能够支持快速数据写入和读取的数仓系统。实时数仓的关键特点是数据能够在最短的时间内,从数据源头到达用户端,从而支持实时数据分析和决策。这种数仓系统通常具有高吞吐量和低延迟的特性,以确保数据流动的实时性。
实时数仓的特点
- 低延迟:实时数仓能够在数据产生后迅速将其捕捉和处理,通常以秒或亚秒级的速度。
- 数据流处理:实时数仓通常使用流式处理技术来处理数据,这允许数据在进入仓库时立即进行转换和计算。
- 实时分析:数据可以用于实时监控、仪表板、预测和决策支持。
- 高吞吐量:实时数仓需要处理大量的数据流,因此需要具备高吞吐量的性能。
- 复杂性:由于需要处理实时数据流,实时数仓的架构和技术通常比较复杂。
什么是离线数仓?
与实时数仓相对,离线数仓是一种在一定时间间隔上进行数据处理和存储的数仓系统。它通常用于周期性的批量数据处理,对实时性要求较低,但更注重数据的完整性和分析的全面性。
离线数仓的特点
- 批处理:离线数仓通过批处理作业处理数据,这意味着数据在一定时间周期内收集、存储,然后一次性处理。
- 高容量:离线数仓通常设计用于存储大量历史数据。
- 延迟较高:由于数据处理是批处理的,因此离线数仓不适合需要实时或近实时数据的应用。
实时数仓与离线数仓的核心区别
一、架构选择与技术实现
1.1 架构选择
- 离线数仓:通常采用传统的大数据架构模式搭建,如Hadoop生态系统中的HDFS、Hive等组件。这种架构以批处理为核心,适合处理大规模数据的存储与计算。
- 实时数仓:则倾向于采用Kappa架构方式搭建,该架构融合了批处理和流处理的优势,能够同时支持实时和离线的数据处理需求。实时数仓常用的技术包括Doris、Kafka、Apache Flink、Apache Storm等,这些技术能够支持高吞吐量的数据流处理和实时分析。
1.2 技术实现
- 离线数仓:依赖于ETL(Extract, Transform, Load)工具在固定时间窗口内对数据进行批处理。数据通常按天或周进行更新,存在一定的处理延迟。
- 实时数仓:则强调数据的实时或近实时更新与写入,支持低延迟的数据处理和查询。通过流处理技术,实时数仓能够实现对数据流的持续处理和实时分析,极大地提升了数据的时效性。
二、数据处理与实时性
2.1 数据处理
- 离线数仓:由于采用批处理方式,数据处理具有一定的延迟性。通常,数据处理结果需要在数据收集后的下一个时间段(如T+1)才能得到,这在一定程度上限制了其在需要即时响应场景中的应用。
- 实时数仓:则通过流处理技术实现了数据的实时或近实时处理。数据处理结果可以在分钟级、秒级甚至毫秒级内得到,极大地满足了企业对数据时效性的需求。
2.2 实时性
- 离线数仓:由于数据处理的延迟性,其统计结果往往是T+1的,即今天只能得到昨天及之前的数据。这种时效性不强的特点限制了其在需要即时决策和监控场景中的应用。
- 实时数仓:则能够实时或近实时地反映数据的变化,支持企业在复杂多变的市场环境中迅速做出反应。例如,在金融交易监控、网络安全检测等领域,实时数仓能够为企业提供毫秒级别的响应能力,有效保障业务的安全和稳定。
三、性能与稳定性
3.1 性能
- 离线数仓:由于数据处理的非实时性,其性能需求相对较低。批处理任务可以在夜间或系统负载较低的时间段执行,从而避免了高峰期对系统资源的占用。
- 实时数仓:则需要较高的性能和低延迟以支持实时数据的高效处理和快速响应。实时数仓通常采用分布式架构和并行处理技术来提升系统性能,确保数据的实时性和准确性。
3.2 稳定性
- 离线数仓:由于数据处理过程相对固定且可预测,其稳定性较好。一旦数据处理流程确定,就可以通过定期的重算来确保数据的准确性和一致性。
- 实时数仓:对数据波动较为敏感,数据重新计算时相对麻烦。实时数仓需要持续处理不断涌入的数据流,对数据处理的稳定性和可靠性提出了更高的要求。同时,由于数据处理的实时性,一旦系统出现故障或数据异常,可能会直接影响业务决策和运营。
四、数据存储与查询
4.1 数据存储
- 离线数仓:通常将数据存储在HDFS、Hive等分布式存储系统中。这些系统具有高度的可扩展性和容错性,能够支持大规模数据的存储和查询。
- 实时数仓:则更倾向于使用Kafka、HBase、Redis、ClickHouse等系统来存储数据。这些系统能够支持高吞吐量的数据写入和实时查询,满足实时数仓对数据时效性和一致性的要求。
4.2 数据查询
- 离线数仓:由于数据存储在HDFS等分布式存储系统中,其查询性能可能受到网络带宽和存储系统性能的限制。同时,由于数据处理的延迟性,离线数仓的查询结果往往不是最新的。
- 实时数仓:则能够实时或近实时地提供数据查询服务。通过优化查询算法和索引技术,实时数仓能够显著提升查询性能,满足企业对数据实时性的需求。
实时数仓和离线数仓的优势对比
实时数仓的优势:
- 高时效性:实时或近实时地反映数据变化,为企业提供最新的业务指标和洞察,支持快速决策。
- 业务敏捷性:在快速变化的市场环境中,实时数仓使企业能够迅速响应市场变化,调整业务策略。
- 增强用户体验:在客户服务、个性化推荐等场景中,实时数仓能够实时分析用户行为,提升用户体验和满意度。
- 风险预警:在金融、安全等领域,实时数仓能够实时监测异常数据,提前预警潜在风险,保障业务安全。
- 用户体验提升:借助实时数仓,可以在用户操作的瞬间提供分析结果,从而提升用户体验。
离线数仓的优势:
- 数据全面性与深度:离线数仓能够处理历史数据,提供全面的数据视图和深度分析,有助于发现长期趋势和潜在规律。
- 资源利用率高:由于数据处理在非高峰时段进行,可以有效利用系统资源,减少对业务运行的干扰。
实时数仓和离线数仓的结合
尽管实时数仓和离线数仓各具优势,但在实际应用中,单一的数仓类型往往不能满足企业的所有需求。越来越多的企业选择将两者结合,形成混合型数据架构的数仓系统。
混合型数仓通过实时数仓和离线数仓的协调合作,实现数据的分层处理和存储。通常的做法是将对实时性要求高的数据处理任务交给实时数仓,而对历史数据的批处理任务则交给离线数仓。例如:Apache Doris 属于一种能够支持实时数仓和离线数仓特性的混合型数仓。
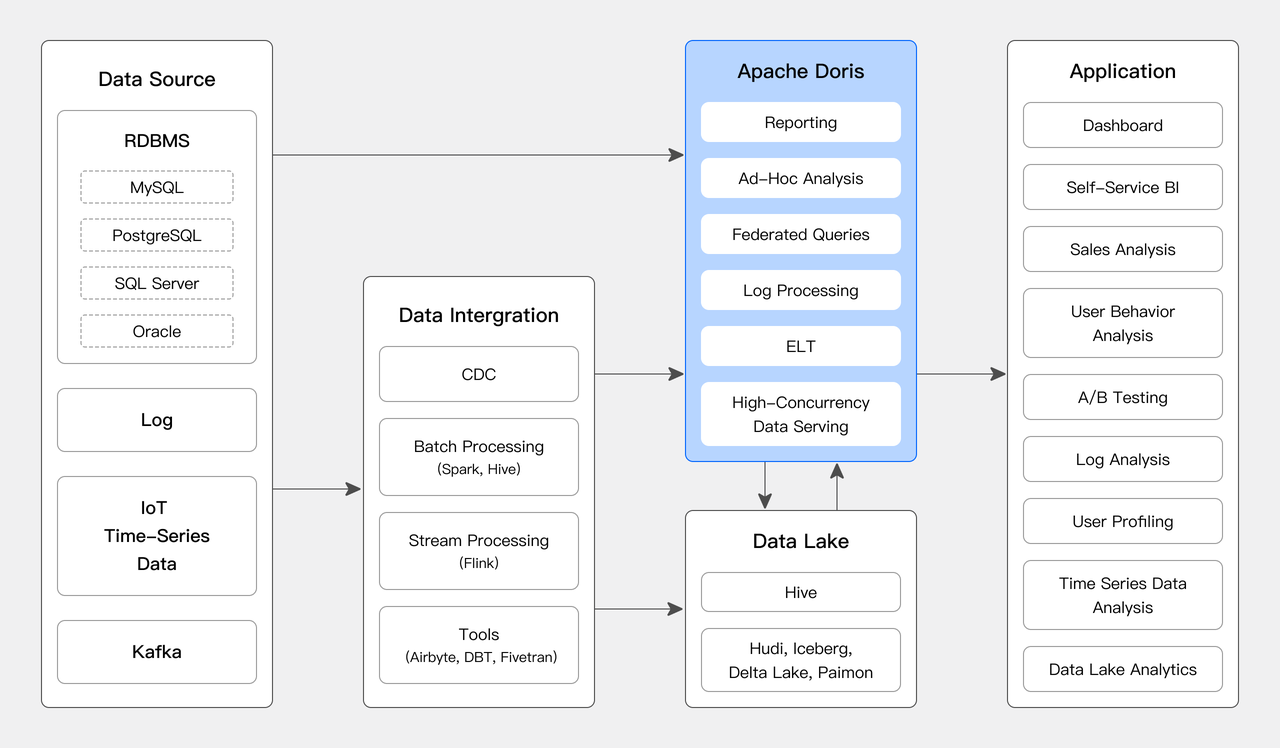
Apache Doris 混合型数仓的优势:

