
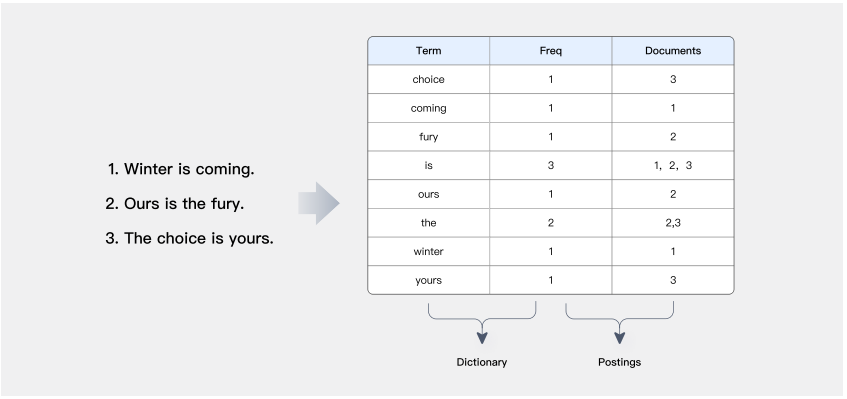
倒排索引(Inverted Index),也常被称为反向索引、置入档案或反向档案,是一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。它是文档检索系统中最常用的数据结构。通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。
倒排索引的应用场景
倒排索引作为一种高效的数据结构,在信息检索和文本搜索领域确实有着广泛的应用场景。以下是几个主要使用场景:
- 搜索引擎
搜索引擎是倒排索引最典型的应用场景之一。搜索引擎如Google、百度等,利用倒排索引快速响应用户查询,通过扫描索引中的关键词来定位包含这些关键词的文档,从而大大提高了检索效率。搜索引擎会将文档集合中的每个文档进行分词处理,并建立关键词与文档ID的映射关系。用户查询时,只需在倒排索引中查找关键词对应的文档列表,即可快速获取相关结果。
- 数据库索引
倒排索引不仅限于全文搜索引擎,还可以用于关系型或非关系型数据库的索引构建,以提高数据检索的速度和效率。相比于传统的正向索引,倒排索引能够更快地定位到包含特定关键词的记录,尤其适用于需要频繁进行全文搜索或复杂查询的数据库系统。
- 文本检索
在文档库、图书馆、档案馆等场景中,文本检索是倒排索引的重要应用之一。通过倒排索引,可以快速查找包含指定关键词的文档,满足用户的信息检索需求。倒排索引能够大大减少搜索时间,提高检索效率,同时支持复杂的查询操作,如布尔检索、模糊检索等。
- 推荐系统
在推荐系统中,倒排索引可以用于构建用户兴趣和行为数据的索引,以支持个性化推荐和相关推荐等功能。通过分析用户的历史行为数据,构建用户兴趣模型,并利用倒排索引快速召回与用户兴趣相关的内容或商品。
- 日志分析
在大数据和云计算环境中,日志分析是保障系统稳定性和性能的重要手段。倒排索引可以用于快速检索和分析日志数据中的关键信息。通过倒排索引,可以快速地定位到包含特定日志级别的记录或包含特定关键字的日志条目,从而帮助开发者和运维人员快速排查问题。
- 网络安全
在网络安全领域,倒排索引可以用于基于网络流量和日志数据的异常检测和入侵检测。通过分析网络流量和日志数据中的关键信息(如IP地址、端口号、关键字等),构建倒排索引以支持快速检索和匹配潜在的安全威胁。
- 社交媒体
在社交媒体平台上,倒排索引可以用于构建用户搜索、内容推荐和精准广告等功能的索引。通过倒排索引,可以快速地响应用户的搜索请求,并基于用户的行为和兴趣推荐相关的内容或广告,提升用户体验和平台价值。
Apache Doris 倒排索引如何做到文本检索性能提升40倍的
为了能够更直观和有力的论证这个结论,接下来一起来看下在无索引硬匹配以及利用倒排索引加速查询的具体表现吧!
先搭建环境,我们进行集群创建和数据导入,使用单节点点集群(1FE、1BE)并按照以下步骤进行操作:
1.搭建 Apache Doris;
2.创建数据表:按照下列建表语句进行数据表创建;

3.下载数据集,数据集为 Parquet 格式,并经过 Snappy 压缩,总大小约为37GB;下载完成后,分别执行以下命令,导入数据集;
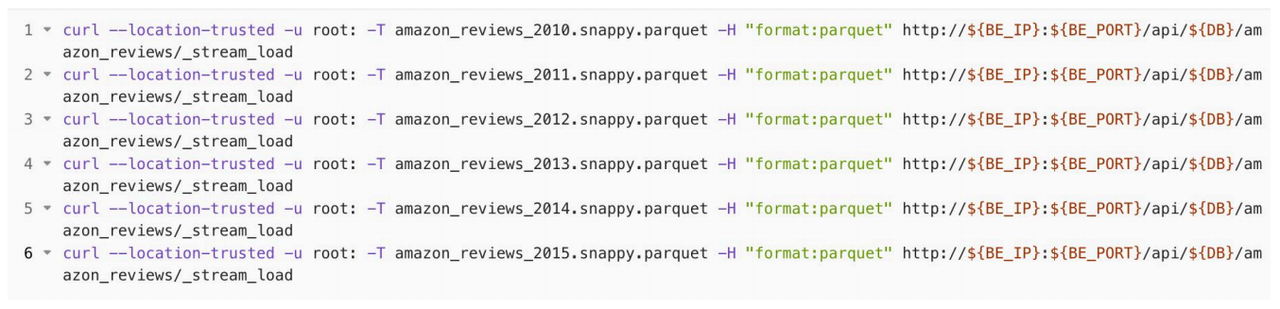
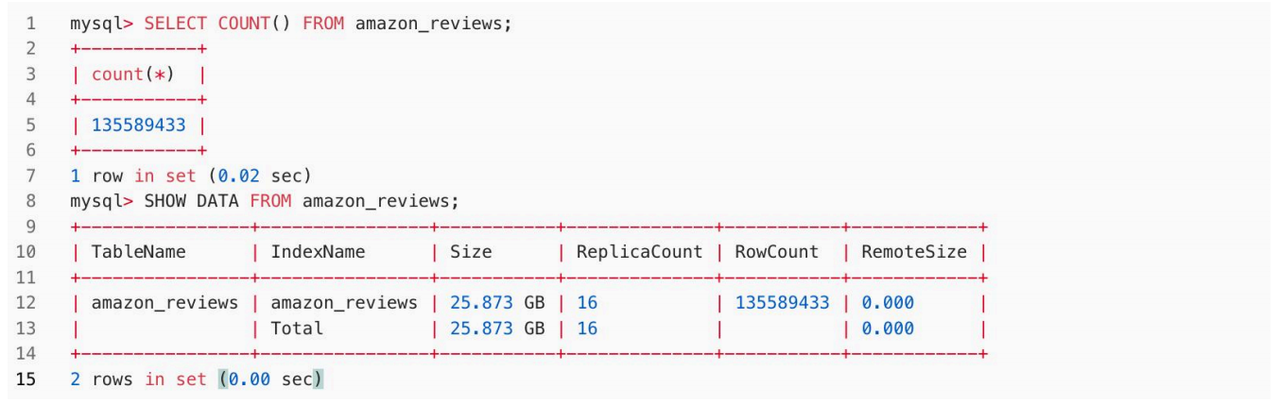
4.查看与验证:完成上述步骤后,可以在MySQL客户端执行!以下语句,来查看导入的数据行数和所占用空间。从下方代码可知:共导入135589433行数据,在Doris中占用空间25.873GB,比压缩后的 Parquet 列式存储进一步降低了30%。
无索引硬匹配
环境及数据准备就绪后,我们尝试对 review_body 列进行文本搜索查询。具体需求是在数据集中查出评论中包含" is super awesome "关键字的前5种产品,并按照评论数量降序排列,查询结果需显示每种产品的 ID、随机一个产品标题、平均星级评分以从及评论总数。review_body 列的特征是评论内容比较长,因此进行文本搜索会有一定的性能压力。
首先我们直接进行查询,以下是查询的示例语句:
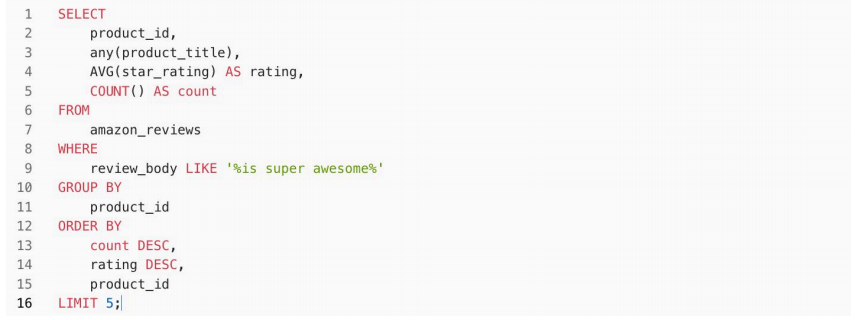
执行结果如下,查询耗时为7.6秒

利用倒排索引加速查询
选择基于倒排索引进一步加速文本搜索的效率,可以通过以下步骤来构建倒排索引:
1.新增倒排索引:对 amazon_reviews 表的 review_body 列※添加倒排索引,该索引采用英文分词,并支持 Phrase 短语查询,短语查询即进行文本搜索时,分词后的词语顺序将会影响搜索结果。
2.为历史数据创建索引:按照新增索引信息对历史数据进行索引构建,使历史数据就也可以使用倒排索引进行查询。

3.查看及验证:构建完索引之后,可以通过以下方式对索引构建情况进行查看:
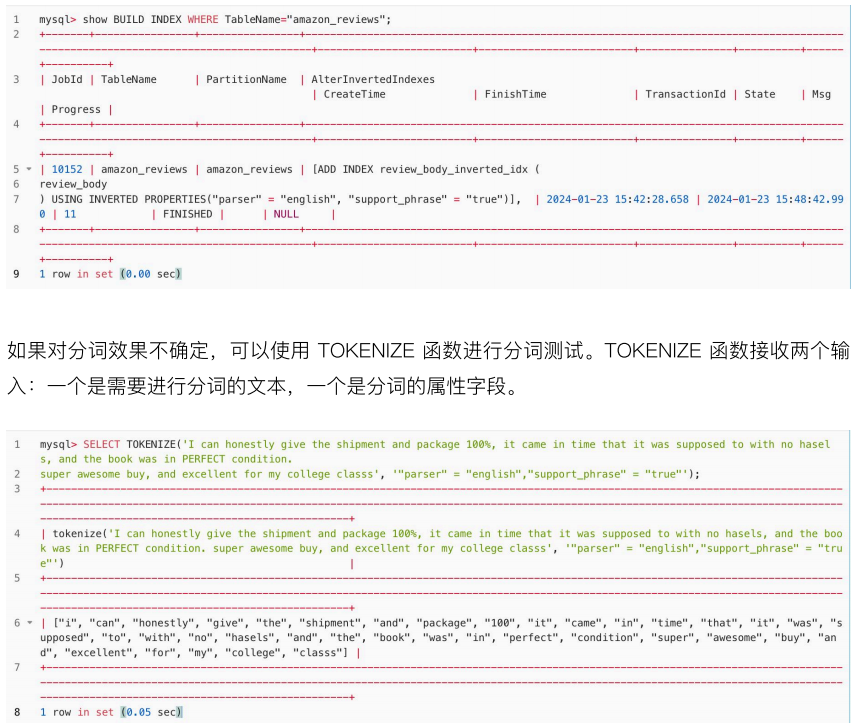
在倒排索引创建完成后,我们使用 MATCH_PHRASE 来查询包含关键词" issuperawesome "的产品评论信息(具体需求可回顾前文)。

执行结果如下所示,开启倒排索引后查询耗时仅0.19秒,性能较未开启索引时提升了近40倍,极大幅度提升了文本检索的效率。

究其加速原因可知,倒排索引是通过将文本分解为单词,并建立从单词到行号列表的映射。这些映射关系按照单词进行排序,并构建跳表索引。在查询特定单词时,可以通过跳表索引和二分查找等方法,在有序的映射中快速定位到对应的行号列表,进而获取行的内容。这种查询方式避免了逐行匹配,将算法复杂度从 O (n) 降低到 O (logn) ,在处理大规模数据时能显著提高查询性能。
Apache Doris 倒排索引五大核心优势
查询性能显著提升:倒排索引通过将文档中的每个词项映射到包含该词项的所有文档的列表,极大地加速了文本搜索和复杂查询的速度。在Apache Doris中,倒排索引特别适用于全文检索、模糊匹配以及非主键列检索等场景,能够显著降低查询SQL的运行时间和资源消耗;
支持复杂文本检索需求:支持多种语言的分词(如英文、中文等)、支持同时匹配多个关键字(MATCH_ALL)、匹配任意一个关键字(MATCH_ANY)以及匹配短语词组(MATCH_PHRASE)等。这使得Apache Doris能够满足多样化的文本检索需求,提升用户体验;
优化数据存储和访问模式:在Apache Doris中,倒排索引使用独立的文件进行存储,与segment文件有逻辑对应关系但存储相互独立。这种设计使得在创建、删除索引时无需重写tablet和segment文件,从而大幅降低了处理开销。同时,倒排索引的引入也促进了数据的有效组织和快速访问,提高了整体的数据处理效率。
性价比提升,主要从以下三方面间接体现:
- 存储成本降低:通过高效的索引技术和数据存储结构,Apache Doris能够在保证查询性能的同时降低存储成本。
- 写入速度提升:倒排索引的引入并未显著增加写入负担,反而可能通过优化数据访问模式提升写入速度(与基于ES的日志存储方案相比,Apache Doris的写入速度提升2倍以上,参考文章4)。
- 总体拥有成本(TCO)降低:由于查询性能的提升和存储成本的降低,Apache Doris在长期使用中的总体拥有成本可能会更低。
易于使用和维护:
- 灵活的索引管理:支持在建表时定义倒排索引,也支持在已有表上增加或删除倒排索引,且支持增量构建倒排索引,无需重写表中的已有数据。
- 标准的SQL查询:Apache Doris使用标准的SQL查询方式,对于创建了倒排索引的字段,查询时也遵循普通的SQL查询方式,这使得用户无需学习新的查询语言即可轻松上手。
- 丰富的分词器支持:虽然目前Apache Doris支持的分词器种类相对有限,但已经能够满足大多数常见需求,并且未来可能会继续增加新的分词器支持。
- 自动化管理:Doris提供了自动化的索引管理和优化策略,减轻了用户的维护负担。
场景
倒排索引作为一种高效的数据结构,在信息检索和文本搜索领域有着广泛的应用场景。以下是倒排索引的主要使用场景:
- 搜索引擎
核心应用:倒排索引是构建搜索引擎的核心数据结构。它允许搜索引擎快速响应用户的查询请求,通过查找关键字对应的倒排列表,快速定位包含这些关键字的文档或网页。例如,Google、百度等搜索引擎都广泛使用了倒排索引技术。
- 数据库索引
提升性能:倒排索引不仅限于搜索引擎,还可以用于构建关系型或非关系型数据库的索引。通过为数据库中的文本字段创建倒排索引,可以显著提高查询性能,尤其是在执行全文搜索时。在MySQL中,可以通过创建全文索引来实现倒排索引的功能。
- 文本检索
信息获取:在文档库或知识库中快速查找包含指定关键字的文档是倒排索引的另一个重要应用场景。无论是学术论文库、专利数据库还是企业内部的知识管理系统,倒排索引都能帮助用户快速准确地获取所需信息。
- 推荐系统
个性化推荐:倒排索引还可以用于构建推荐系统。通过对用户行为数据(如浏览记录、购买历史等)建立倒排索引,可以分析用户的兴趣和偏好,从而为用户提供个性化的推荐内容。这种技术在电商平台、视频流媒体服务和社交媒体平台中得到了广泛应用。
- 日志分析
异常检测:在处理大规模日志数据时,倒排索引可以帮助快速定位特定事件或异常行为。通过将日志中的关键字或事件类型与日志条目建立映射关系,可以迅速筛选出与查询条件匹配的日志记录,进而进行进一步的分析和处理。
- 网络安全
入侵检测:在网络安全领域,倒排索引可以用于基于网络流量和日志数据的异常检测和入侵检测。通过分析网络数据包中的关键字或特征码与已知的攻击模式进行匹配,可以及时发现并阻止潜在的网络攻击行为。
- 社交媒体
用户搜索与推荐:社交媒体平台也利用倒排索引来实现用户搜索、内容推荐和精准广告等功能。通过对用户发布的内容、关注的话题和互动行为建立倒排索引,可以为用户提供更加个性化和精准的社交体验。
综上所述,倒排索引在信息检索、数据库查询、文本分析、推荐系统、日志分析、网络安全和社交媒体等多个领域都有着广泛的应用场景。其高效、灵活和可扩展的特性使得它成为处理大规模文本数据的重要工具之一。
优势
Doris(Apache Doris)的倒排索引在多个方面展现出了显著的优势,这些优势主要体现在提升查询性能、支持复杂文本检索需求以及优化数据存储和访问模式上。以下是对Doris倒排索引优势的详细归纳:
- 查询性能显著提升
- 快速文本检索:倒排索引将文本内容拆分成独立的词或短语,并建立词或短语到文档(或数据行)的映射关系。这种结构使得在查询特定关键词时,可以直接定位到包含这些关键词的文档或数据行,从而显著提高查询速度。
- 降低资源消耗:通过减少不必要的底层数据读取,倒排索引能够降低查询过程中的CPU、内存和IO开销,进而提升整体系统的性能和效率。
- 支持复杂文本检索需求
- 全文检索:Doris的倒排索引支持全文检索功能,允许用户查询包含任意关键词的文档或数据行。这对于处理大量文本数据的场景(如日志分析、文档管理等)尤为重要。
- 模糊匹配:通过合理的分词和索引策略,Doris的倒排索引还可以在一定程度上支持模糊匹配查询,提高查询的灵活性和准确性。
- 多条件组合查询:用户可以根据需要组合多个关键词进行查询,Doris的倒排索引能够高效地处理这类复杂查询请求。
- 优化数据存储和访问模式
- 高效索引构建:Doris提供了丰富的索引类型和灵活的索引构建策略,用户可以根据实际需求选择合适的索引类型和属性来优化查询性能。
- 列式存储支持:Doris采用列式存储格式,与倒排索引相结合可以进一步提升查询效率。列式存储使得相同类型的数据被物理上连续存储,有利于减少IO操作和提高缓存命中率。
- 向量化计算引擎:Doris的向量化计算引擎能够充分利用现代CPU的SIMD指令集来加速查询处理过程,与倒排索引相结合可以进一步提升查询性能。
- 性价比提升
- 存储成本降低:相较于传统的基于ES的日志存储方案,Doris通过倒排索引等优化手段降低了存储成本,提高了性价比。
- 写入速度提升:Doris的倒排索引支持高效的数据写入操作,使得在相同硬件配置下能够实现更快的数据更新速度。
- 易于使用和维护
- 标准SQL支持:Doris支持标准SQL查询语言,用户无需学习复杂的查询语法即可轻松上手使用倒排索引等高级功能。
- 自动化管理:Doris提供了自动化的索引管理和优化策略,减轻了用户的维护负担。
综上所述,Doris的倒排索引在查询性能、文本检索需求支持、数据存储和访问模式优化以及性价比提升等方面均展现出显著的优势。这些优势使得Doris成为处理大规模文本数据场景下的理想选择之一。


