
在实时数据仓库的业务场景中,能够友好支持数据的实时更新是一个非常重要的能力。例如在数据库同步(CDC)、电商交易订单、广告效果投放、营销业务报表等业务场景中,面对上游数据的变化,通常需要快速获取到变更记录并针对单行或多行数据进行及时变更,保证业务分析师及相关分析平台能快速捕捉到最新进展,提升业务决策的及时性。
而对于一贯不擅长数据更新的 OLAP 数据库而言,如何更好实现实时更新的能力,在数据时效性要求愈发强烈以及实时数仓业务应用范围愈加广阔的今天,成为了赢得激烈竞争的关键。
在过去 Apache Doris 主要通过 Unique Key 数据模型来实现数据实时 Upsert,因底层采取了类似 LSM Tree 结构,对于大数据量的高频写入具有足够强劲的支撑,但由于采取了 Merge on Read 的更新模式,因此读取效率成了制约 Apache Doris 发挥实时更新能力的瓶颈,在应对实时数据的并行读写时可能引发查询抖动问题。
基于此,在 Apache Doris 1.2.0 版本中,我们在 Unique Key 模型上引入了全新的数据更新方式 Merge-On-Write,力求在实时更新和高效查询间得到统一。本文将详细介绍全新主键模型的设计实现以及效果。
原 Unique Key 模型的实现
了解 Apache Doris 历史的用户可能知道,Doris 最初的设计是受 Google Mesa 启发,最初只有 Duplicate Key 模型和 Aggregate Key 模型,而 Unique Key 模型是在 Doris 发展过程中根据用户的需求而增加的。但那时实时更新的需求并没有这么强,Unique Key 的实现也相对比较简单——只是将 Aggregate Key 模型做了一层包装,并没有针对实时更新的需求进行深度优化。
具体而言,Unique Key 模型的实现仅是 Aggregate Key 模型的一个特例,如果使用 Aggregate Key 模型,并将所有非 Key 列的聚合类型都设置为 REPLACE,则可以实现完全相同的效果。如下图所示,对一个 Unique Key 模型的表example_tbl进行 desc,最后一列的聚合类型显示它等价于所有列都是 REPLACE 聚合类型的 Aggregate Key 表。
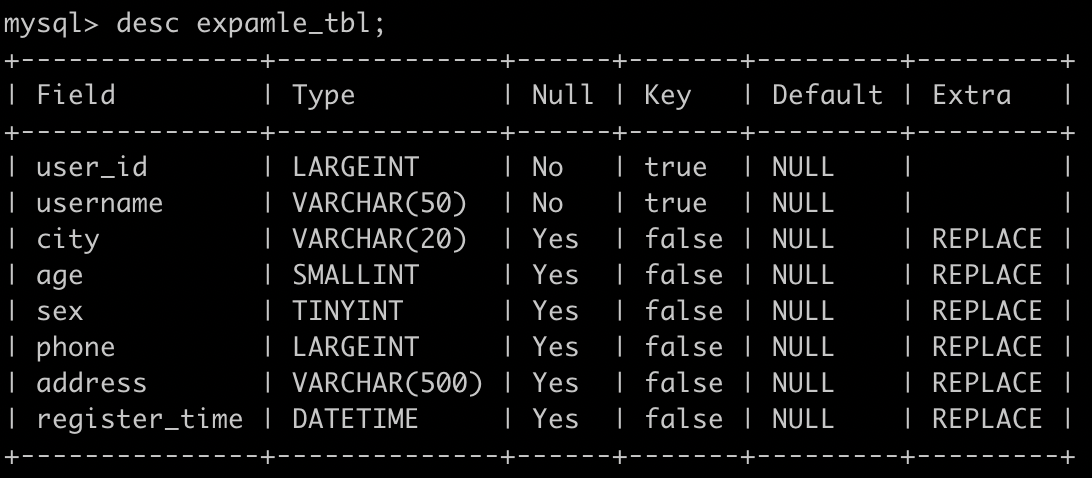
Unique Key 数据模型和 Aggregate Key 数据模型都是 Merge- O n-Read 的实现方式,也就是说数据在导入时先写入一个新的 Rowset,写入后并不会执行去重,只有在发起查询时才会做多路并发排序,在进行多路归并排序时,会将重复的 Key 排在一起,并进行聚合操作,其中高版本 Key 的会覆盖低版本的 Key,最终只返回给用户版本最高的那一条记录。
下图是一个简化后的 Unique Key 模型执行过程表示:
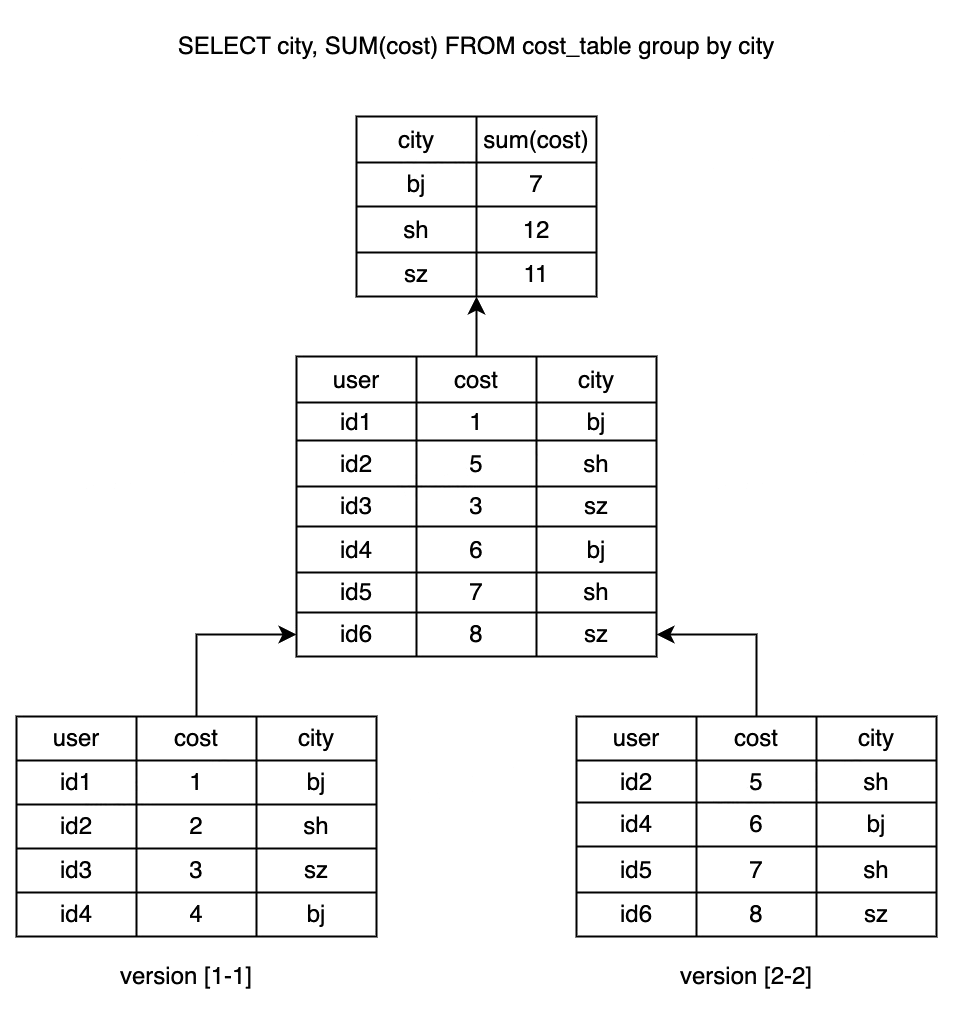
虽然其实现方式较为一致,但是 Unique Key 和 Aggregate Key 数据模型的使用场景有明显的差异:
用户在创建 Aggregate Key 模型的表时,对于聚合查询的条件是非常明确的——按照 Aggregate Key 指定的列进行聚合,Value 列上的聚合函数就是用户主要使用的聚合方法(COUNT/SUM/MAX/MIN 等),例如将
user_id作为 Aggregate Key,将访问次数和时长进行 SUM 聚合来计算 uv 和用户使用时长。但 Unique Key 数据模型的 Key 的主要作用其实是保证唯一性,而不是作为聚合的 Key。例如在订单场景中,通过 Flink CDC 从 TP 数据库同步过来的数据,是以订单 ID 作为 Unique Key 来进行去重的,但查询的时候通常是对某些 Value 列(例如订单状态,订单金额,订单耗时,下单时间等)进行过滤、聚合和分析。
不足之处
以上可知,用户使用 Unique Key 模型进行查询的时候,实际上是进行了两次聚合操作,第一次是按照 Unique Key 进行全部数据的逐 Key 聚合,去除掉重复的 Key;第二次是按照查询真正需要的聚合条件进行聚合。而这两次聚合的操作就带来了比较严重的效率问题,导致查询性能低下:
数据去重需要执行代价很高的多路归并排序,全量 Key 的比较非常消耗 CPU 的计算资源。
无法进行有效的数据裁剪,引入大量额外的数据 IO。例如某个数据分区有 1 千万条数据,但是符合筛选条件的数据只有 1000 条, OLAP 系统丰富的索引就是用来高效地筛选出这 1000 条数据的。但由于无法确定具体文件里某条数据的值是否有效,使得这些索引派不上用场,必须先全部进行一次归并排序并对数据进行去重之后,才能对这些最终确认有效的数据进行过滤。这就带来了约 1 万倍的 IO 放大(这一数字仅为粗略的估计,实际的放大效应计算起来更为复杂)。
方案调研与选型
为了解决原 Unique Key 模型存在的问题,以更好的满足业务场景的需求,我们决定对 Unique Key 模型进行优化,针对读写效率问题的优化方案展开了详细的调研。
关于以上问题的解决方案,业内已经有了较多的探索。代表性的有三类:
Delete + Insert。即在数据写入时通过一个主键索引查找到被覆盖的 key,将其标记为删除。比较有代表性的系统是微软的 SQL Server。
Delta Store。将数据分为base data和 delta data,base data中的每一个主键都保证唯一,所有更新都记录在 Delta Store中,查询时将 base data 和 delta data 进行merge同,时有后台的 merge 线程定期将 delta data和 base data进行合并。比较有代表性的系统是 Apache Kudu。
Copy-on-Write。在更新数据时直接将原来的数据整行拷贝、更新后写入新文件。数据湖采用这类方式的比较多,比较有代表性的系统是 Apache Hudi 与 Delta Lake。
具体三类方案的实现机制及对比如下:
Delete + Insert ( 即 Merge-on-Write)
比较有代表性的是 SQL Server 在 2015 年 VLDB 上发表的论文《Real-Time Analytical Processing with SQL Server》中提出的方案。简单来说,这篇论文提出了数据写入时将旧的数据标记删除(使用一个 Delete Bitmap 的数据结构),并将新数据记录在 Delta Store 中,查询时将 Base 数据、Delete Bitmap、Delta Store 中的数据 Merge 起来以得到最新的数据。整体方案如下图所示,由于篇幅限制就不展开进行介绍了。
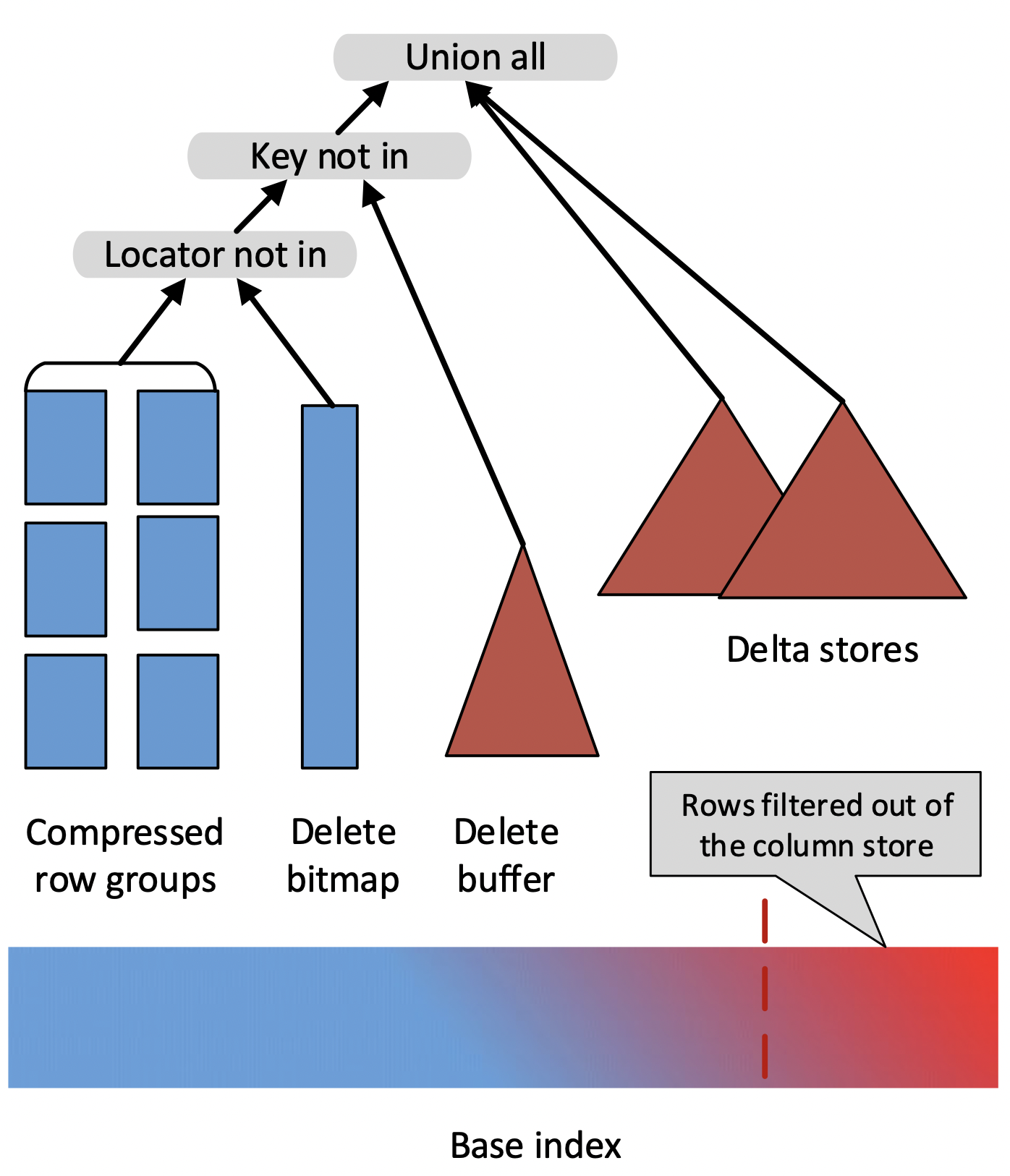
这个方案的优势在于,任何一个有效的主键只存在于一个地方(要么在 Base Data 中,要么在 Delta Store 中),这样就避免了查询过程中的大量归并排序的消耗,同时 Base 数据中的各种丰富的列存索引也仍然有效。
Delta Store
Delta Store 的方式比较有代表性的系统就是 Apache Kudu。在 Kudu 中,数据分为 Base Data 和 Delta Data,Base Data 中的主键都是唯一的,任何对于 Base 数据的修改会先写入 Delta Store 中(通过行号标记与 Base Data 中的对应关系,这样可以避免 Merge 时的排序)。与前面 SQL Server 的 Base + Delta 不同的是,Kudu 没有标记删除,所以同一个主键的数据会存在于两个地方,所以查询时必须将 Base 和 Delta 的数据合并才能得到最新的结果。Kudu 的方案如下图所示:
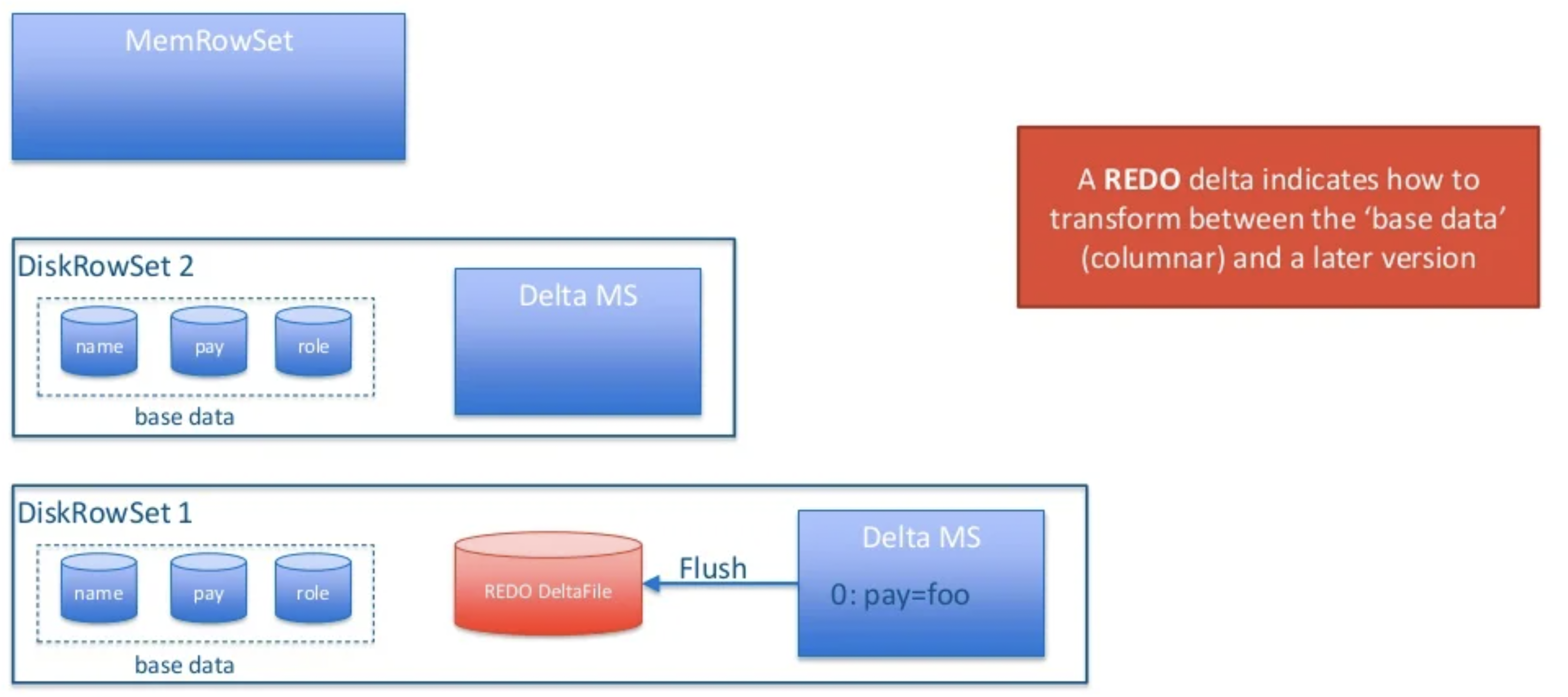
Kudu 这套方案也能避免读取数据时的归并排序所带来的高昂代价,但是由于一个主键的数据会存在于多个地方,它就难以保证索引的准确性,也无法做一些高效的谓词下推。而索引和谓词下推都是分析型数据库进行性能优化的一个重要手段,这个缺点对于性能影响还是挺大的。
Copy-On-Write
由于 Apace Doris 定位是一个实时分析型数据库,Copy On Write 方案对于实时更新来说成本太高,并不适合 Doris。
方案比较
下面的表格对比了各个方案,其中 Merge-On-Read 是 Unique Key 模型的默认实现,即1.2版本之前的实现方式,Merge-On-Write(写时合并)即前面提到的 Delete + Insert 方案。
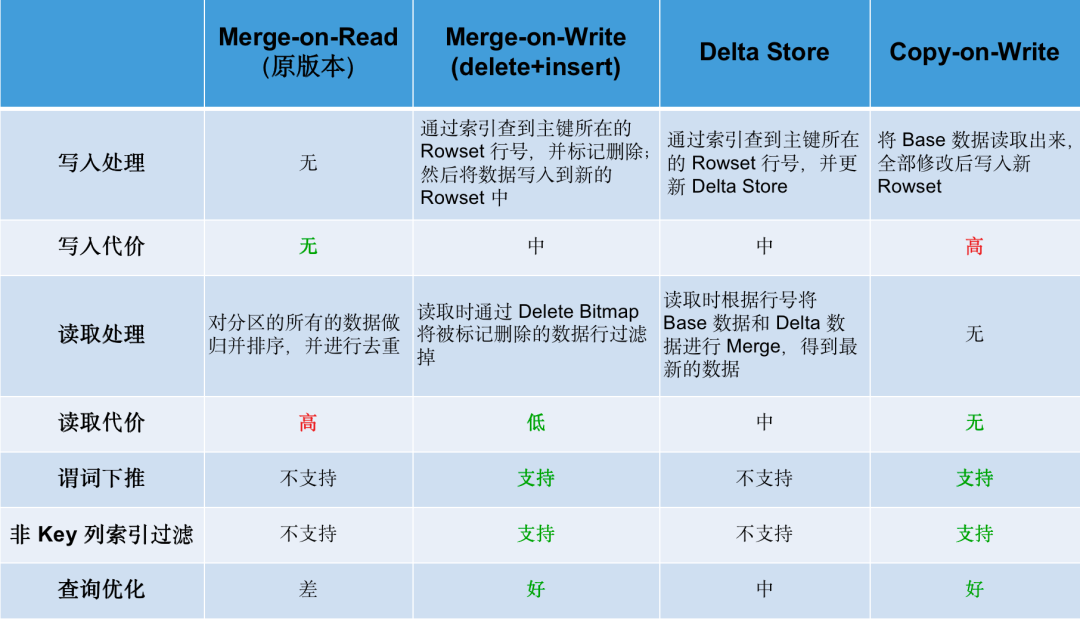
如上可知,Merge-On-Write 付出中等的写入代价,换取了较低的读取成本,对谓词下推、非 key 列索引过滤均能友好支持,并对查询性能优化有较好的效果。综合对比后,我们选择了 Merge-On-Write 作为最终的优化方案。
新版方案的设计与实现
简单来讲,Merge-On-Write 的处理流程是:
对于每一条 Key,查找它在 Base 数据中的位置(rowsetid + segmentid + 行号)
如果 Key 存在,则将该行数据标记删除。标记删除的信息记录在 Delete Bitmap中,其中每个 Segment 都有一个对应的 Delete Bitmap
将更新的数据写入新的 Rowset 中,完成事务,让新数据可见(能够被查询到)
查询时,读取 Delete Bitmap,将被标记删除的行过滤掉,只返回有效的数据
关键问题
设计适合 Doris 的 Merge-On-Write方案,需要重点解决以下几个问题:
导入时如何高效定位到是否存在需要被标记删除的旧数据?
标记删除的信息如何进行高效的存储?
查询阶段如何高效的使用标记删除的信息来过滤数据?
能否实现多版本支持?
如何避免并发导入的事务冲突,导入与 Compaction 的写冲突?
方案引入的额外内存消耗是否合理?
写入代价导致的写入性能下降是否在可接受范围内?
根据以上关键问题,我们进行了一系列优化措施,使得以上问题得到较好的解决。 下 文中我们将进行详细介绍:
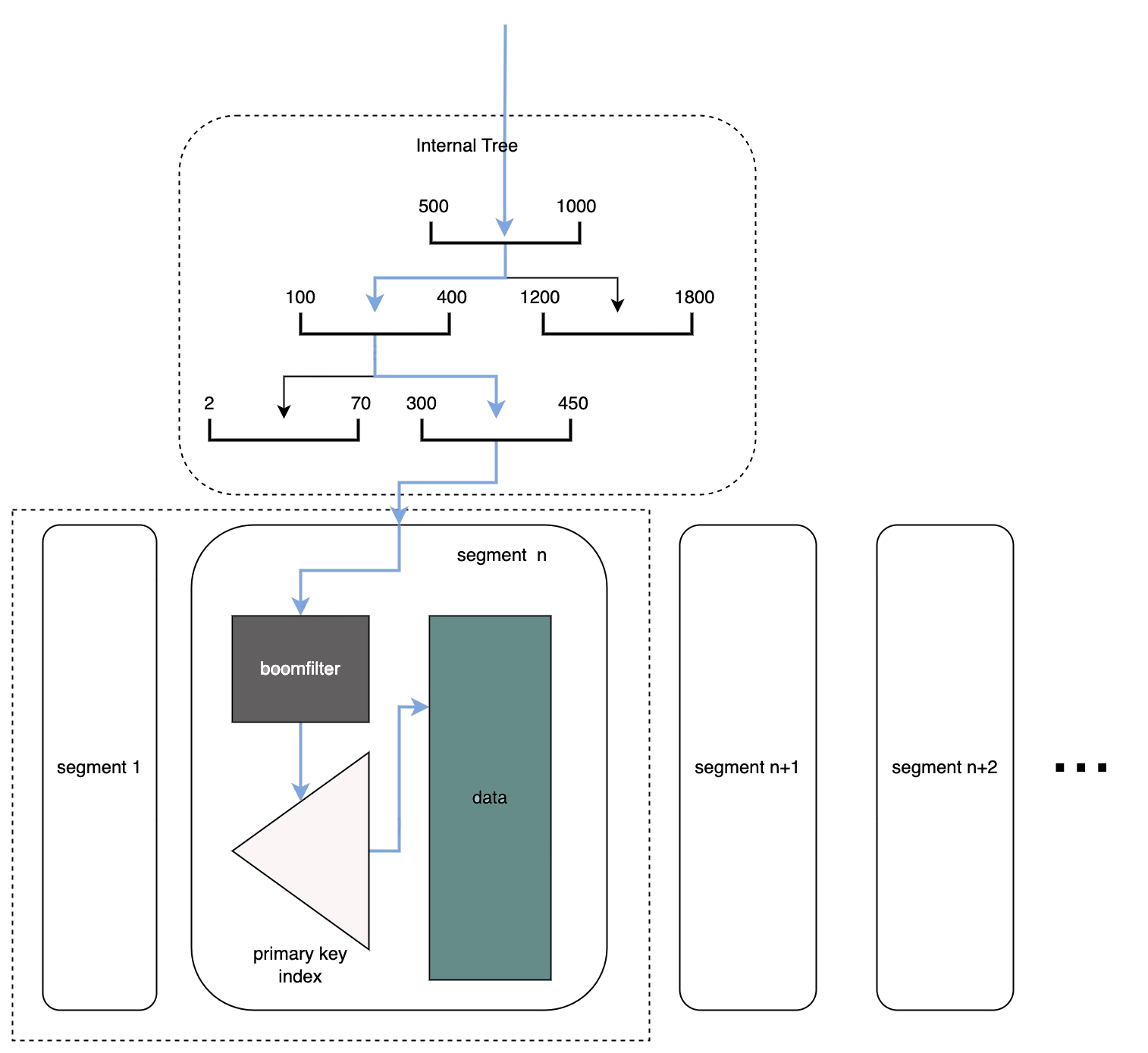
主键索引
由于 Doris 是面向大规模分析设计的列存系统,并没有主键索引的能力,因此为了能够快速定位到有没有要覆盖的主键,以及要覆盖的主键的行号,就需要给 Doris 增加一个主键索引。
我们采取了如下的优化措施:
为每个 Segment 维护一个主键索引。主键索引的实现采用了似于 RocksDB Partitioned Index 的方案。该方案能够实现非常高的查询 QPS,同时基于文件的索引方案也能够节省内存占用。
为每个 Segment 维护一个主键索引对应的 Bloom Filter。当 Bloom Filter 命中时才会查询主键索引。
为每个 Segment 记录一个主键的区间范围 [min-key, max-key]
维护一个纯内存的区间树,使用所有 Segment 的主键区间构造。在查询一个主键时,无需遍历所有的 Segment,可以通过区间树定位到可能包含该主键的 Segment,大幅减少需要查询的索引量 。
对于命中的所有 Segment,按照版本从高到低进行查询。在 Doris 中高版本意味着更新的数据,因此如果一个主键在高版本的 Segment 索引中命中,就无需继续查询更低版本的 Segment 。
查询单个主键的流程如下图所示:
Delete Bitmap
Delete Bitmap 采取多版本的方式进行记录,具体如下图所示:
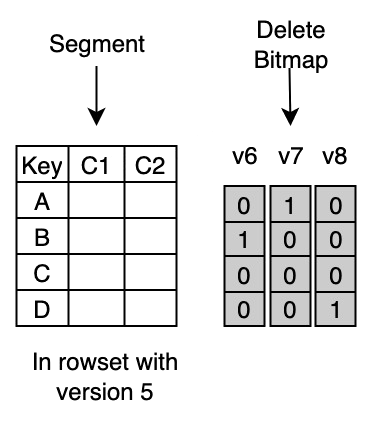
图中的 Segment 文件是由版本 5 的导入产生的,包含了该 Tablet 中版本 5 的导入数据
版本 6 的导入中包含了对主键 B 的更新,因此会在 Bitmap 中将第二行标记删除,并在 DeleteBitmap 中记录版本 6 的导入对该 Segment 的修改
版本 7 的导入包含了对主键 A 的更新,也会产生一个对应版本的 Bitmap;同理版本 8 的导入也会产生一个对应的 Bitmap
所有的 Delete Bitmap 存储在一个大的 Map 中,每次导入都会将最新的 Delete Bitmap 序列化到RocksDB 中。其中关键定义如下:
using SegmentId = uint32_t;
using Version = uint64_t;
using BitmapKey = std::tuple<RowsetId, SegmentId, Version>;
std::map<BitmapKey, roaring::Roaring> delete_bitmap;
每个 Rowset 中的每个 Segment,都会记录多个版本的 Bitmap。Version 为 x 的 Bitmap 意味着版本为 x 的导入对当前 Segment 的修改。
多版本 Delete Bitmap 的优点:
能很好的支持多版本的查询,例如版本 7 的导入完成后,一个该表的查询开始执行,会使用 Version 7 来执行,即使这个查询执行时间较长,在查询执行期间版本 8 的导入已经完成,也无需担心读到版本 8 的数据(或者漏掉被版本 8 删除的数据)
能够很好的支持复杂的 Schema Change。在 Doris 中,复杂的 Schema Change(例如类型转换)需要先进行双写,同时将某个版本之前的历史数据进行转换后再删除掉旧版的数据。多版本的 Delete Bitmap 可以很好的支持当前的 Schema Change 实现
可以支持数据拷贝和副本修复时的多版本需求
不过多版本 Delete Bitmap也有对应的代价,在刚才的例子中,访问版本 8 的数据,需要将 v6、v7、v8 的三个 Bitmap Merge 在一起才能得出完整的 Bitmap,再用该 Bitmap 对 Segment 数据进行过滤。在实时高频导入场景中,很容易产生大量的 Bitmap,而 Roaringbitmap 的并集操作的 CPU Cost 很高,为了尽可能减少大量并集操作的影响,我们为 DeleteBitmap 增加了 LRUCache 来记录最新合并过的 Bitmap。
写入流程
写入数据时会先创建每个 Segment 的主键索引,再更新 Delete Bitmap。主键索引的建立比较简单,篇幅有限不再详细描述,重点介绍一些比较复杂的 Delete Bitmap 更新流程:
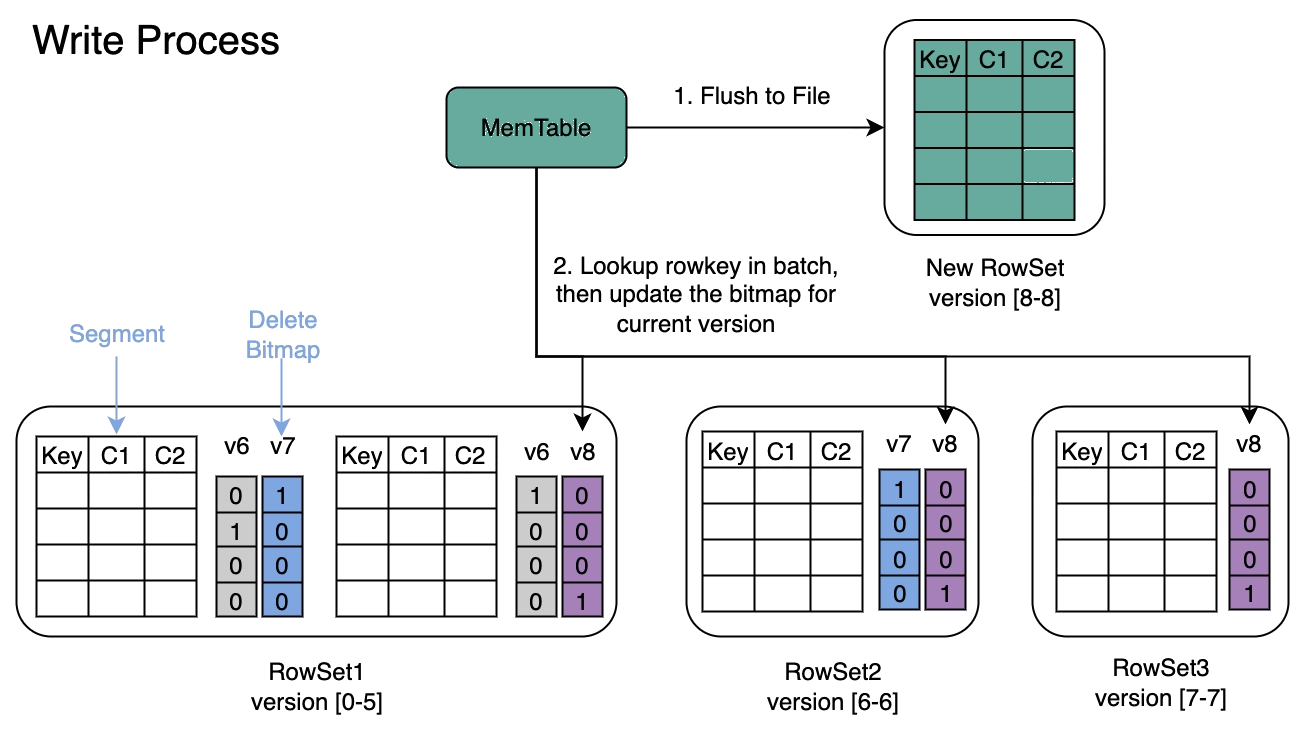
DeltaWriter 会先将数据 Flush 到磁盘
在 Publish 阶段去批量的点查所有的 Key,并且更新被覆盖的 Key 对应的 Bitmap。在下图中,新写入的 Rowset 版本是 8,它修改了 3 个 Rowset 中的数据,因此会产生 3 个 Bitmap 的修改记录
在 Publish 阶段去更新 Bitmap,保证了批量点查 Key 和更新 Bitmap 期间不会有新增可见的Rowset,保证了Bitmap更新的正确性。
如果某个 Segment 没有被修改,则不会有对应版本的 Bitmap 记录,比如 Rowset1 的 Segment1 就没有 Version 8 对应的 Bitmap
读取流程
Bitmap 的读取流程如下图所示,从图片中我们可知:
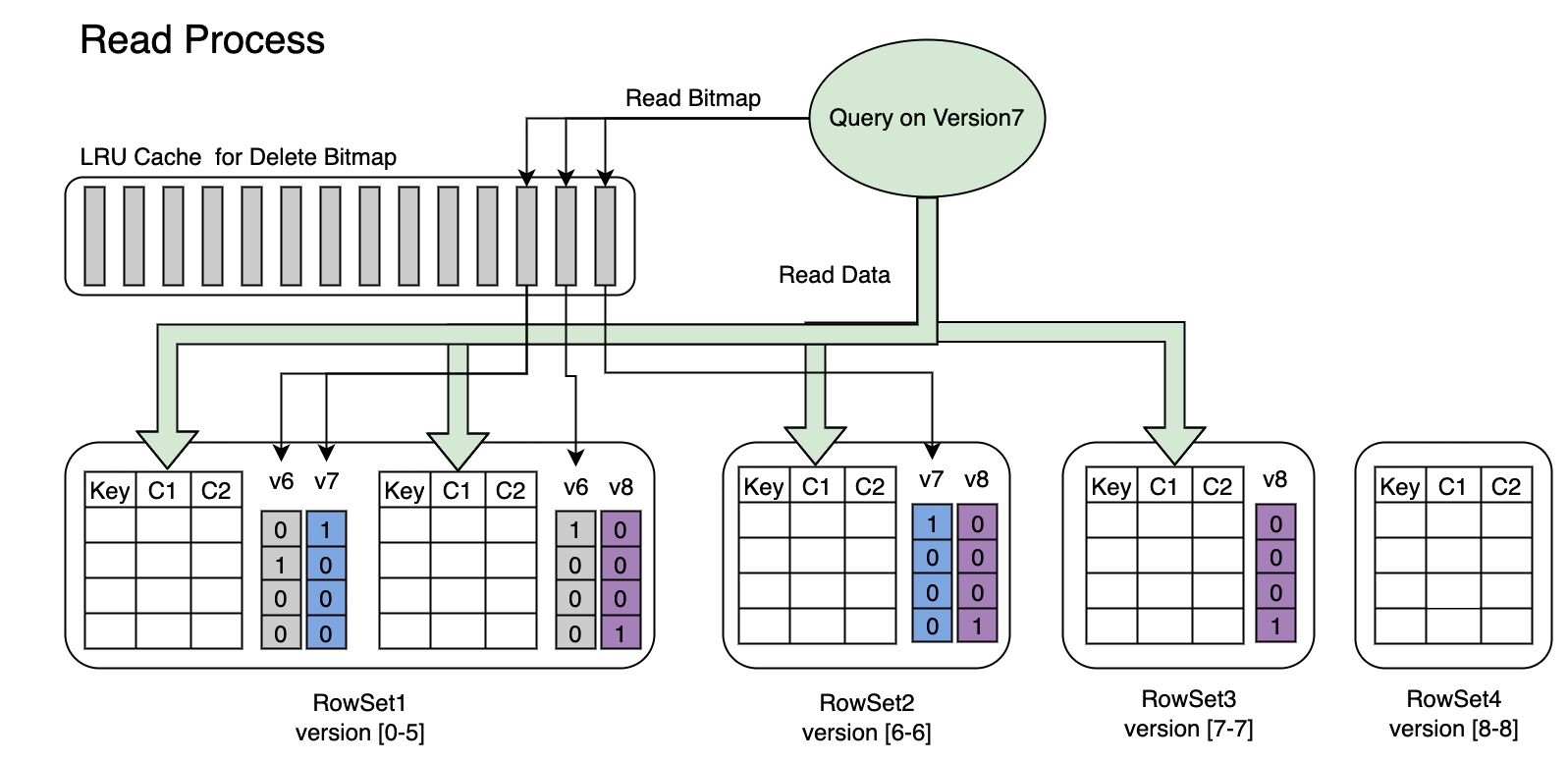
一个请求了版本 7 的 Query,只会看到版本 7 对应的数据
读取 Rowset5 的数据时,会将 v6 和 v7 对它的修改产生的 Bitmap 合并在一起,得到 Version7 对应的完整 DeleteBitmap,用来过滤数据
在下图的示例中,版本 8 的导入覆盖了 Rowset1 的 Segment2 一条数据,但请求版本 7 的 Query 仍然能读到该条数据
在高频导入场景下,可能会存在大量版本的 Bitmap,合并这些 Bitmap 本身可能也有较大的 CPU 计算消耗。因此我们引入了一个LRUCache,每个版本的 Bitmap 只需要做一次合并操作。
Compaction 与写冲突的处理
Compaction 正常流程
- Compaction 在读取数据时,获取当前处理的 Rowset 的版本 Vx,会自动通过 Delete Bitmap 过滤掉被标记删除的行(见前面的查询层适配部分)
- Compaction 结束后即可清理源 Rowset 上所有小于等于版本 Vx 的 DeleteBitmap
Compaction 与写冲突的处理
- 在 Compaction 的执行过程中,可能会有新的导入任务提交,假设对应版本为 Vy。如果 Vy 对应的写入有对 Compaction 源 Rowset 中的修改,则会更新到该 Rowset 的 DeleteBitmap 的Vy中
- 在 Compaction 结束后,检查该 Rowset 上所有大于 Vx 的 DeleteBitmap,将它们中的行号更新为新生成的 Rowset 中的 Segment 行号
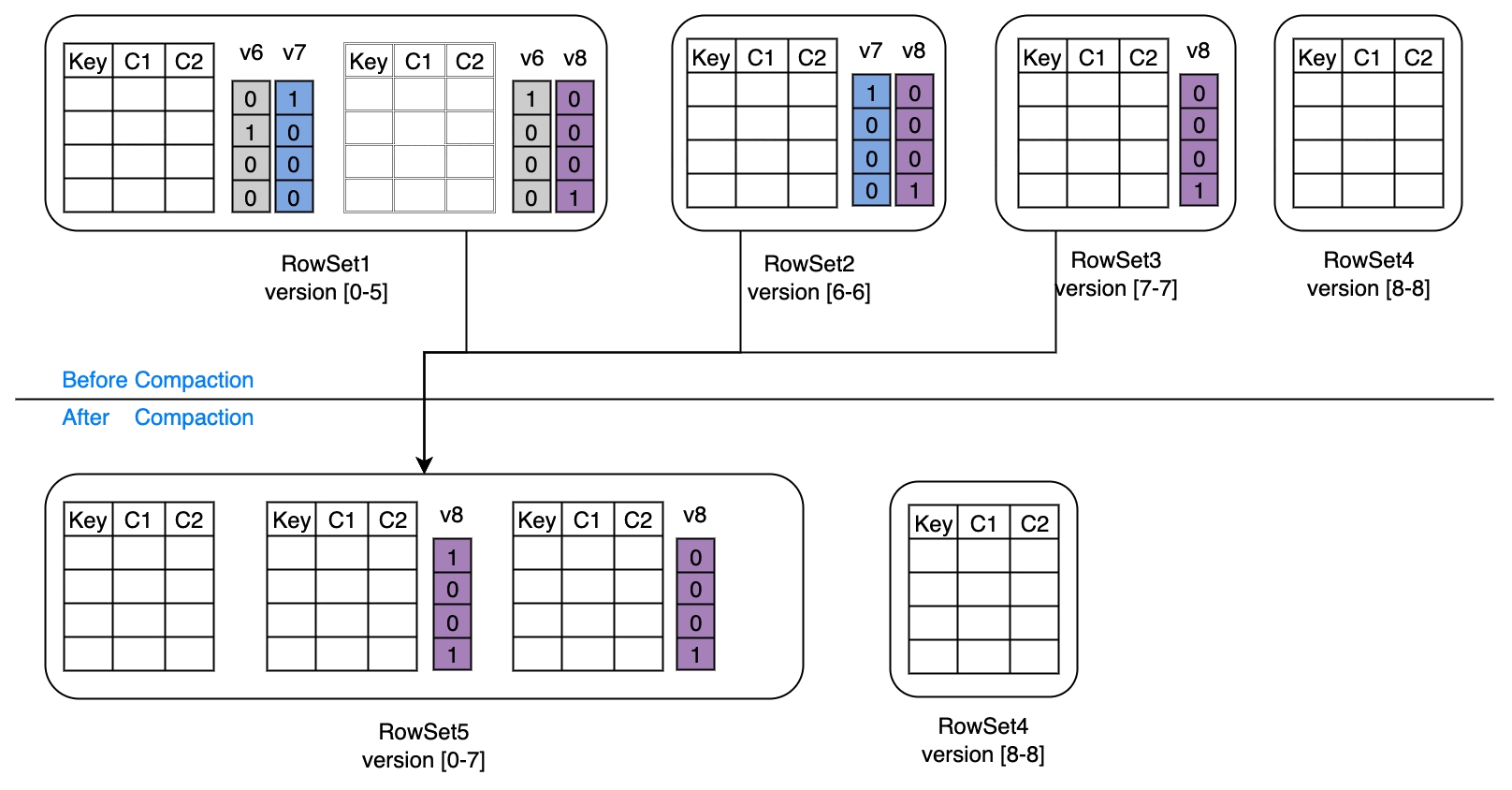
如下图所示,Compaction 选择了[0-5], [6-6], [7-7]三个 Rowset, 在 Compaction 过程中,Version8 的导入执行成功,在 Compaction Commit 阶段,需要处理由 Version8 的数据导入所生成的新 Bitmap
写入性能优化
在最初设计时,DeltaWriter 不在写入数据阶段进行点查和 Delete Bitmap 更新,而是在 Publish 阶段做,这样能保证 Delete Bitmap 更新时可以看到该版本之前所有的数据,保证 Delete Bitmap 的正确性。但是在实际的高频导入测试中发现,Publish 阶段串行对每个 Rowset 的数据进行全量点查和更新时,所引入的额外消耗会使得导入吞吐出现较大幅度下降。
因此在最终设计中,我们将 Delete Bitmap 的更新改成两阶段的形式:第一阶段可以并行执行,只查找和标记删除当时能看到的 Version;第二阶段必须串行执行,将此前第一阶段可能漏查的新导入的 Rowset 中的数据再更新一遍。第二阶段增量更新数据量很少,因此对整体的吞吐影响非常有限。
优化效果
新的 Merge-On-Write 实现通过在写入的时候将旧的数据标记删除的方式,能够始终保证有效的主键只会出现在一个文件中(即在写入的时候保证了主键的唯一性),不需要在读取的时候通过归并排序来对主键进行去重,这对于高频写入的场景来说,大大减少了查询执行时的额外消耗。
此外,新版实现还能够支持谓词下推,并能够很好利用 Doris 丰富的索引,在数据 IO 层面就能够进行充分的数据裁剪,大大减少数据的读取量和计算量,因此在很多场景的查询中都有比较明显的性能提升。
需要注意的是,如果用户使用 Unique Key 的场景都是低频的批量更新,则 Merge-On-Write 实现对于用户查询效果的提升不一定明显,因为对于低频的批量更新,Doris 的 Compaction 机制通常就能够较快的将数据给 Compact 到比较好的状态(也就是说 Compaction 完成了主键的去重),避免了查询时的去重计算代价。
对于聚合分析的优化效果
我们使用 TPC-H 100 中数据量最大的 Lineitem 表进行了测试,为了模拟出多个持续写入的场景,将数据切分了 100 份,并进行了 3 次的重复导入。之后进行了 count(*) 的查询,效果对比如下:
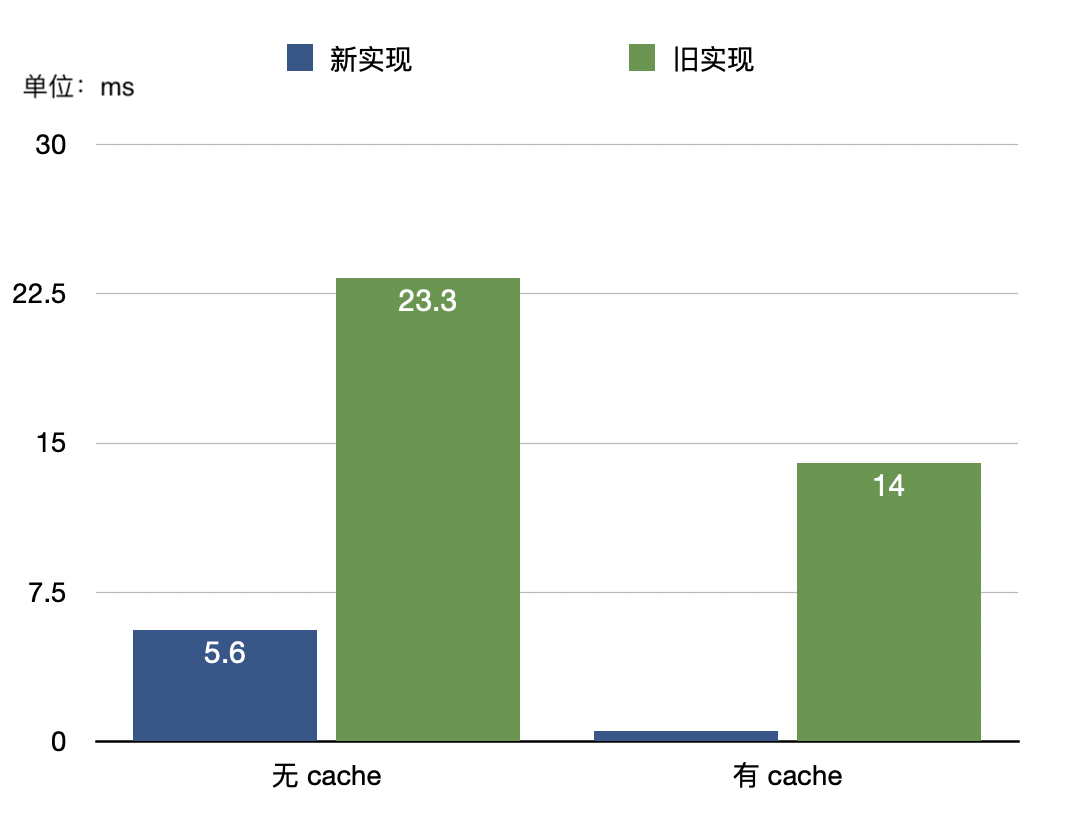
分别对比了无 Cache 和有 Cache 的情形,在无Cache 的情况下由于从磁盘加载数据的耗时较多,整体上有大约4倍的性能提升;而排除掉磁盘读取数据的开销影响,在有Cache 的情况下新版实现的计算效率能够有20多倍的性能提升。
Sum 的效果类似,篇幅有限就不再列举。
SSB Flat
除了简单的 Count 和 Sum,我们还对 SSB-Flat 数据集进行了测试,在 100G 数据集(切分成 10 份,多次导入来模拟有数据更新的场景)上的优化效果如下图所示:
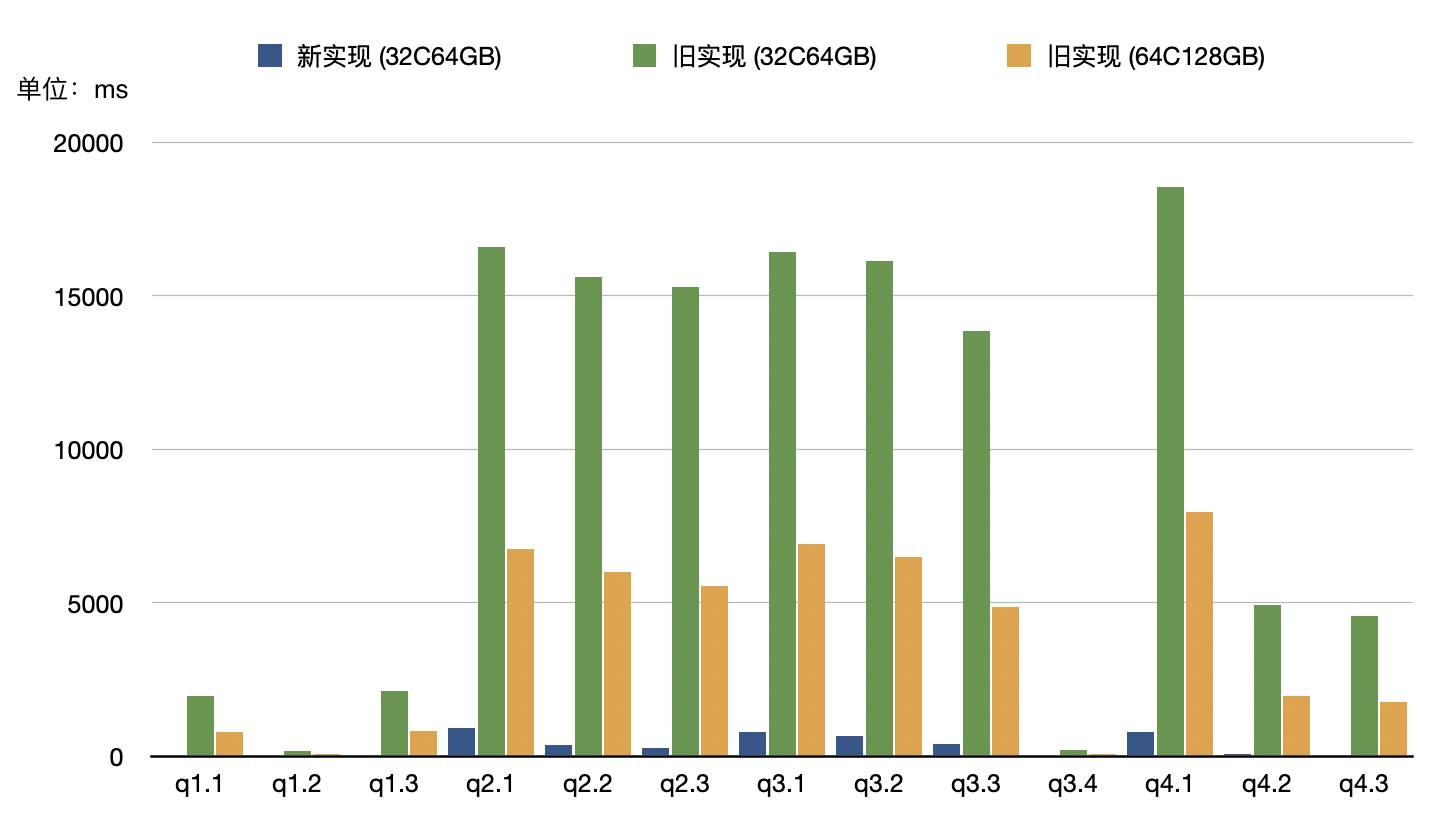
关于测试结果的说明:
在 32C64GB 的典型配置下,所有查询跑完的总耗时,在新版实现上是 4.5 秒,旧版实现为 126.4 秒,速度相差近 30倍。进一步分析,我们发现在旧版实现的表上的查询执行时,32核CPU全部打满。因此更换了配置更高的机型来测试计算资源充足时旧版实现的表上的查询耗时
在 64C128GB 的配置下,旧版实现总耗时 49.9s,最高约跑满了48 个核。在计算资源充足的情况下,旧版实现仍然与新版实现有12倍的性能差距
由此可见,新版实现不仅大大提升了查询速度,而且能够显著减少 CPU 的消耗。
对数据导入的影响
新版的 Merge-On-Write 实现主要是为了优化数据的查询性能,如前所述也取得了不错的效果。不过这些优化效果是通过在写入时做了一些额外工作换取的,因此,新版 Merge-On-Write 实现会使得数据导入效率有小程度的变慢,但由于存在并发并且多个批次之间的导入可以形成 Pipeline 的效应,整体的吞吐没有明显的下降
使用方式
在 1.2 版本中,作为一个新的 Feature,写时合并默认关闭,用户可以通过在建表时添加下面的 Property 来开启:
“enable_unique_key_merge_on_write” = “true”
另外新版本 Merge-on-Write 数据更新模式与旧版本 Merge-on-Read 实现方式存在差异,因此已经创建的 Unique Key 表无法直接通过 Alter Table 添加 Property 来支持,只能在新建表的时候指定。如果用户需要将旧表转换到新表,可以使用 insert into new_table select * from old_table 的方式来实现。
未来的规划
新版的 Merge-On-Write 实现能够兼容之前 Unique Key 的所有功能,包括条件更新(使用 Sequence 列在乱序写入中保证数据更新的正确性)、通过 Delete Sign 进行批量删除、Schema Change、UPDATE 语句等。
从用户的反馈来看,Unique Key 模型目前对如下几个需求的支持水平还需要进一步提升,这也是我们下一步工作的重点:
部分列更新。 目前 Unique Key主要支持的是 Upsert 操作(也就是整行更新),暂时不支持 Update操作(也就是每次只更新一部分列的数据)。但在订单、画像等场景中,存在大量的需求,需要频繁且实时的更新一部分状态列,当前只能通过 Aggregate Key 模型的
REPLACE_IF_NOT_NULL功能来实现部分列更新。未来在 Doris 1.3 版本中,我们计划支持完整的 Unique Key 模型的部分列更新。提高点查性能。 Doris 采用的是列式存储,数据按列组织,列存系统天然在大规模数据分析中具有优势,在按行点查上存在劣势(因为一次读取一行需要进行 N 次磁盘文件的访问,相比行存系统来说存在非常大的 IO 放大问题)。随着 Doris 在订单、画像等对实时数据更新有强需求的领域的广泛使用,越来越多的用户提出了希望 Doris 支持高性能点查,以替代 HBase 等系统,来简化运维。这方面我们已经有了初步方案,正在开发中,预计在 2023 年上半年的新版本中可以发布。
目前 Apache Doris 1.2 版本已经发布,欢迎大家下载使用!新版本特性全面了解:全面进化!Apache Doris 1.2.0 Release 版本正式发布|版本通告,也欢迎有兴趣的开发者可以一起参与到社区的开发中。


