在当今数据驱动的时代,企业对数据分析和洞察的需求日益增长。传统的关系型数据库在处理大规模数据时,往往面临性能瓶颈,比如存储大、处理速度慢、数据分析模型固定灵活性较低、运维成本高等,而分析型数据库(Apache Doris)以其卓越的性能和高效的数据处理能力,正在改变这一现状,SelectDB 作为基于 Apache Doris 构建的现代化数据仓库, 支持大规模实时数据上的极速查询分析。
早期的数据仓库架构往往存在以下的痛点:
-
依赖组件多。大部分的数据仓库 在 2.x、3.x 版本中强依赖 Hadoop 和 HBase ,应用组件较多导致开发链路较长,架构稳定性隐患多,维护成本比很高。
-
构建过程复杂,构建任务容易失败。构建需要进行打宽表、去重列、生成字典,构建 Cube 等如果每天有 1000-2000 个甚至更多的任务,其中至少会有 10 个甚至更多任务构建失败,导致需要大量时间去写自动运维脚本。
-
维度/字典膨胀严重。维度膨胀指的是在某些业务场景中需要多个分析条件和字段,如果在数据分析模型中选择了很多字段而没有进行剪枝,则会导致 Cube 维度膨胀严重,构建时间变长。而字典膨胀指的是在某些场景中需要长时间做全局精确去重,会使得字典构建越来越大,构建时间也会越来越长,从而导致数据分析性能持续下降。
-
数据分析模型固定,灵活性较低。在实际应用过程中,如果对计算字段或者业务场景进行变更,则要回溯部分甚至全部数据。
-
不支持数据明细查询。早期数仓架构是无法提供明细数据查询的,Kylin 官方给的解决方法是下推给 Presto 做明细查询,这又引入了新的架构,增加了开发和运维成本。
现代分析型数据库(Apache Doris)架构的优势:
-
极简运维,维护成本低,不依赖 Hadoop 生态组件。Apache Doris 的部署简单,只有 FE 和 BE 两个进程, FE 和 BE 进程都是可以横向扩展的,单集群支持到数百台机器,数十 PB 的存储容量,并且这两类进程通过一致性协议来保证服务的高可用和数据的高可靠。这种高度集成的架构设计极大的降低了一款分布式系统的运维成本。
-
链路短,开发排查问题难度大大降低。基于 Doris 构建实时和离线统一数仓,支持实时数据服务、交互数据分析和离线数据处理场景,这使得开发链路变的很短,问题排查难度大大降低。
-
支持 Runtime 形式的 Join 查询。Runtime 类似 MySQL 的表关联,这对数据分析模型频繁变更的场景非常友好,解决了早期结构数据模型灵活性较低的问题。
-
同时支持 Join、聚合、明细查询。解决了早期架构中部分场景无法查询数据明细的问题。
-
支持多种加速查询方式。支持上卷索引,物化视图,通过上卷索引实现二级索引来加速查询,极大的提升了查询响应时间。
-
支持多种联邦查询方式。支持对 Hive、Iceberg、Hudi 等数据湖和 MySQL、Elasticsearch 等数据库的联邦查询分析。
新的数仓在速度上的优势,具体我们来看看数据上的表现吧!
以下将简述分析型数据库在多个公开标准测试数据集上的优异性能表现,揭示其如何助力企业实现更快速、更准确的数据洞察。
我们通过使用 3 台 16core, 64GB 云主机测试, SF100 得出以下结论(测试数据图如下):
- 多表关联复杂查询场景 Doris 2.0 性能相比 Doris0.15 提升 13 倍,相比其他的 MPP 数据库有明显优势;
- 单表场景 Doris 2.0 性能相比 Doris 0.15 提升 10 倍,相比擅长单表的 CK 有优势;
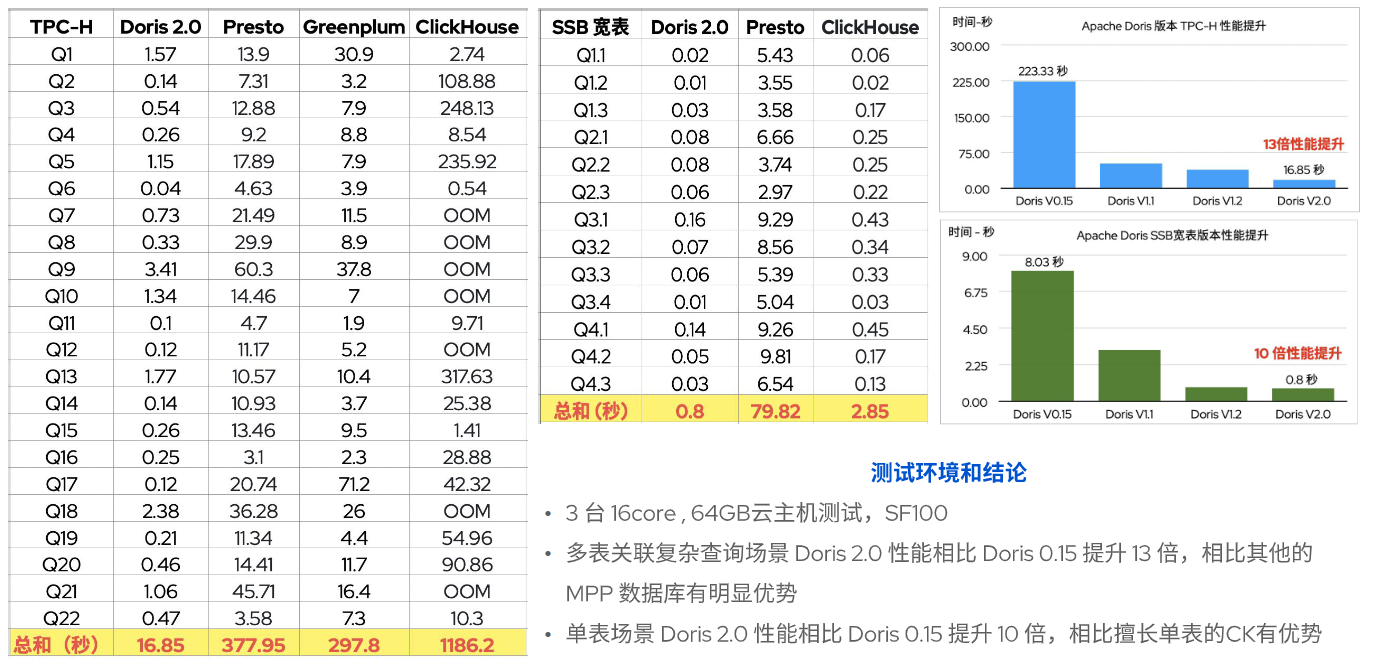
从上面的测试数据看,不管是多表关联复杂查询场景还是单表场景 Doris 2.0 都比传统的 Doris 0.15 要提升了 10 倍以上。现在你对于分析型数据库(Apache Doris)以及分析性能的速度到底有多快有一定的概念和理解了吗?
Apache Doris 凭借其灵活的查询模型、极低的运维成本、短平快的开发链路以及优秀的查询性能等诸多方面优势,如今已经在实时业务运营、自助/对话式分析等多个业务场景得到运用,满足了设备画像/用户标签、业务场景实时运营、数据分析看板、自助 BI、财务对账等多种数据分析需求。
基于 Apache Doris 构建的现代化数据仓库 SelectDB, 支持大规模实时数据上的极速查询分析,当前市场上 SelectDB 研发的 SelectDB 产品被广泛使用。
在未来,随着数据量的不断增长和技术的不断创新,SelectDB 将在更多领域发挥重要作用。从金融行业的风险管理到医疗领域的疾病预测,从电商平台的用户行为分析到政府部门的政策效果评估,Apache Doris 等分析型数据库将为企业提供更快速、更准确的数据洞察,助力企业实现更高效、更智能的决策。
