本文整理自度小满 Doris 数据库负责人汤斯在 Doris Summit 2025 中的演讲,并以演讲者第一视角进行叙述。
度小满金融(原百度金融)作为一家覆盖现代财富管理、支付、金融科技等多板块的科技公司,数据的分析处理对其极为重要,已经深度融入业务生命周期的每个环节,是进行风险控制、商业决策、用户体验优化及运营提效的基石。
随着业务高速发展,度小满原有基于 Greenplum 搭建的 OLAP 平台,逐渐暴露出三大痛点:
- 规模与稳定性瓶颈:存储已接近饱和,扩容至百余台已接近硬件规模的承载上限,如果继续扩容,将面临更严重的稳定性挑战。
- 性能与体验不佳:Greenplum SQL 查询执行速度慢,且经常出现 “计算时间远小于排队时间” 的情况,严重影响业务分析效率。
- 缺失技术支持:当前使用的 Greenplum 6 版本技术架构已显得陈旧,并且 2024 年 Greenplum 宣布将停止开源,后续的技术支持与迭代升级将无法保障。
为了应对这些痛点,度小满金融迫切寻找更为高效、稳定且具备现代化技术架构的数据处理解决方案,以支持其未来的业务发展。
Apache Doris:高吞吐、快查询
面对日益增长的业务体量与复杂多变的分析需求,选用一个高效、可靠的数据库系统,已成为支撑业务稳健发展与快速创新的关键。Apache Doris 以其出色的性能表现与高度灵活的架构,成为众多场景下的优选方案。为深入验证其在海量数据与复杂分析场景中的能力,我们展开了一系列性能测试,关键结果如下:
- 查询性能:在 1TB TPC-DS 标准测试集中, Apache Doris 的查询速度约是 Greenplum 6 的 20-30 倍。
- 导入性能:在基于 Flink 写入的 TPS 测试中,基于单分片导入,压测最大 TPS 为:5000W/s。
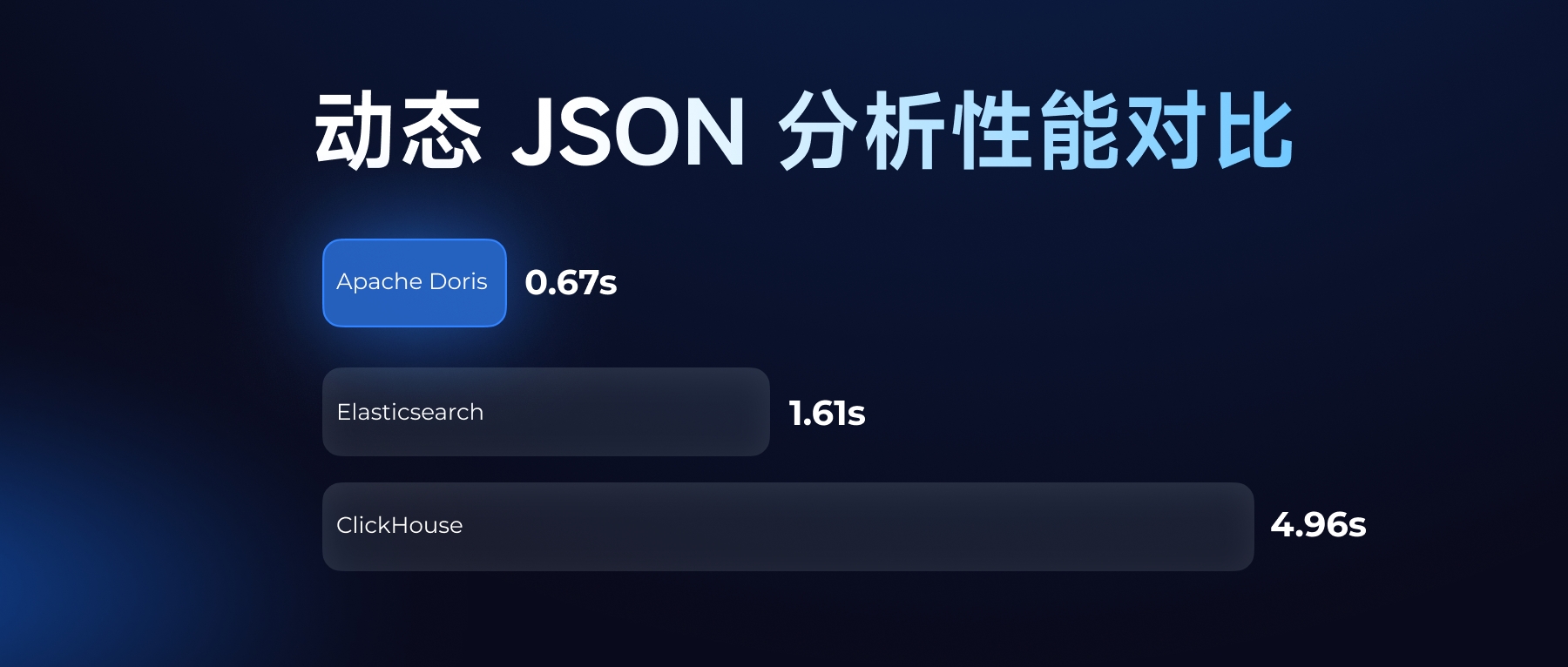
- JSON 数据处理:针对新推出的 Variant JSON 数据类型,测试显示:存储 2-3 万 Key 时,其空间占用仅为普通 JSON 的 1/10 甚至更低,查询效率则提升至 10 倍以上。
综上可知,Apache Doris 在写入吞吐、响应速度及存储效率上表现卓越,有力证明了其应对大规模、实时化、半结构化数据分析挑战的坚实技术基础。
基于 Apache Doris 的大规模数据分析平台
在上述详实的选型调研之后,我们决定采用 Apache Doris 替代原有 Greenplum 集群,构建超大规模数据分析平台。
为验证 Apache Doris 在真实业务场景中的表现,我们先进行了小范围试点,部署了少量 Doris 集群,并先行接入几个关键业务方。试点期间,系统在性能、稳定性和易用性方面获得高度评价。基于这一积极反馈,我们稳步扩展 Doris 集群规模,最终在效率与成本上实现大幅提升:
- 整体效率:端到端分析任务耗时从 274 秒降至 47 秒,效率提升 82%,任务超时查杀比例从 1.3%骤降至 0.11%,降幅达 91%,彻底解决高峰期排队问题实现 0 排队,使分析师的工作不再因拥堵而中断,体验和生产力均有极大提升。
- 集群成本:在同等资源成本下, Doris 仅以 1/3 的集群数量即可提供与 Greenplum 同等的服务能力,存储性能提升 200%。截至目前,已完成 百余台原 Greenplum 服务器的清退工作,以更少的硬件资源支撑了更高的计算与存储需求,实现年度硬件成本节约数百万元。
从 0-1 数据平台建设经验
我们基于 Apache Doris 成功替换了 Greenplum,完成了从 0-1 的数据平台重构,覆盖架构设计、数据流转与业务协同的系统性工程。以下将围绕快速平滑迁移、异地多活容灾与全链路生态集成三个核心环节,展开具体实践。
01 快速迁移
为保障业务连续性与数据安全,我们开发了自动化迁移工具 SqlGlot,将大规模数据从原有 GP 集群迁移至 Doris 集群。整个过程历经半年,累计迁移 PB 级规模数据,全程业务无感知。
- 表结构迁移:在表结构迁移阶段,团队从 GP 系统中导出表结构及相关元数据,借助 SqlGlot 工具实现字段映射与语法适配,并在此基础上完成分区构建与分桶策略设计,确保每个分桶数据量控制在 1G~3G 的合理范围内。该流程最终成功转换超过 20,000 张表,并保障了所有表的分区与分桶结构符合业务与性能要求。
- 表数据迁移:我们通过分布式导出将 GP 数据并行迁移至 Doris 机器,并基于 Doris 官方推荐的 Stream Load 进行并发控制,以文件流式加载的方式高效导入数据至 Doris 集群。整个过程累计完成 PB 级规模数据迁移,稳定支持了 5000+ 次数据同步任务。
- SQL 迁移:为解决因业务规模庞大、场景复杂而导致的官方工具语法支持不全的问题,我们基于 SqlGlot 并结合正则匹配能力,将 PostgreSQL SQL 高效转换为 Doris SQL。整个迁移流程包括“转换成功 → 执行成功 → 数据一致” ,累计完成约 47 万个 SQL 的转换,实现 95% 的执行成功率 与 92% 的数据一致率。
02 异地双机房灾备
为保障数据安全并实现集群高可用,我们基于 Apache Doris 构建了异地双机房灾备架构,确保数据与服务具备跨机房容灾与双活能力。核心设计如下:
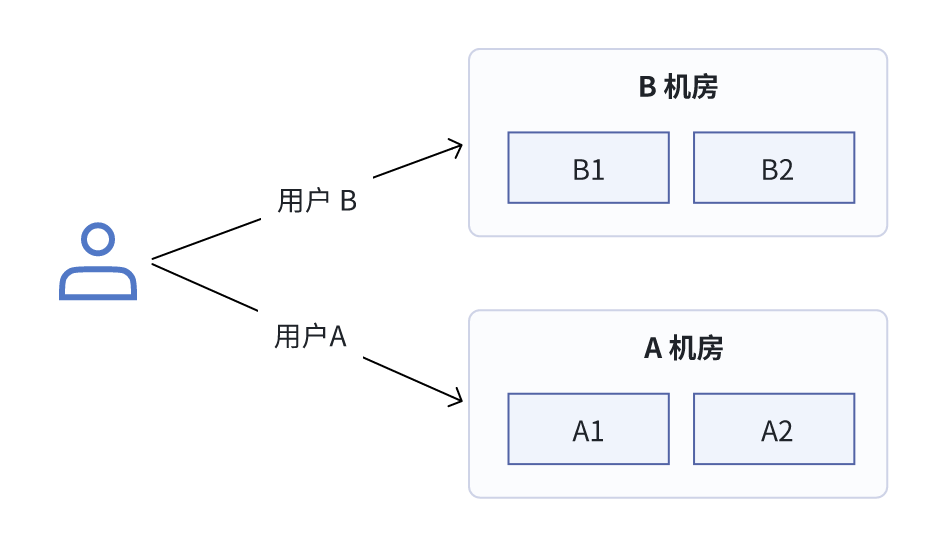
我们将所有 Doris 集群节点均匀部署于 A 与 B 两个异地机房,通过设置 tag.location 属性明确节点所属机房。用户账号按机房绑定,访问请求通过轮询机制自动分配,实现负载均衡(例如首次请求路由至 A 机房,第二次则路由至 B 机房)。建表时通过配置 location 参数,确保每张表在双机房各保留 2 个副本,从而达成数据异地双活与故障自动切换。
关键配置示例:
- 设置节点机房标签
alter system modify backend ”BE1:9050" set ("tag.location" = "group_a");
alter system modify backend ”BE2:9050" set ("tag.location" = "group_b");
- 建表时指定双机房副本分布
CREATE TABLE ubevent
(ts DATETIME, uid INT, ...)
DUPLICATE KEY(ts)
DISTRIBUTED BY HASH(uid) BUCKETS 10
PROPERTIES ("replication_allocation" = "tag.location.group_b: 2, tag.location.group_a: 2");
03 生态整合
为构建高效、稳定、易用的数据平台,我们还围绕 Apache Doris 进行系统性生态整合:
- 计算引擎无缝集成:通过 Doris 官方提供的 Spark Connector 与 Flink Connector,实现了与现有 Spark、Flink 计算引擎的高效对接,保障了数据流水线稳定运行。
- 运维体系化与自动化:集成 Prometheus、Grafana 及 Doris Manager,构建了覆盖监控、告警、管理与调优的自动化运维体系,全面提升集群稳定性与运维效率。
优化经验
为进一步提升数据平台的效率及资源利用率,在实际落地过程中,围绕集群、负载、存储等多维度总结了以下优化经验:
01 集群隔离
当前我们有多个 Doris 集群,为合理承接不同业务方的接入需求,我们主要依据业务成本与稳定性要求两大维度进行评估与路由。通常而言,稳定性越高,对应成本也越高。
新建集群时,稳定性最优,但相应成本也最高。为在成本与稳定性之间取得平衡,我们大多场景是基于 Workload Group 资源硬隔离方案,对 CPU 与内存进行资源组级别的隔离,有效减少不同业务负载间的资源竞争。若业务对稳定性的要求超出共享集群所能提供的范围,则仍需要通过新建独立集群来满足。
02 存储压力
在 Apache Doris 的落地与运维过程中,我们曾面临因业务快速增长带来的高达 80%-90% 的磁盘存储压力。针对这一问题,进行了一系列优化:
- 控制表生命周期:部分业务或因对动态分区相关语法不熟悉,未主动采用该策略。为此,集成动态分区的参数配置,简化了开发难度,并提供统一注册入口,业务开发人员仅需选择是否开启、保留天数即可。
- 修改压缩格式:将默认压缩算法从 LZ4 切换为 ZSTD。实测表明,存储空间平均节省约 50%,虽带来约 20%~30% 的 CPU 与内存负载上升,但整体 ROI 仍然较高。
- 存储指标监控告警:为预防因误操作或异常行为导致的存储激增,建立了针对“人员”与“表”双维度的监控体系。环比分析业务人员数据占用趋势及单表每日增长量,可自动识别异常(如单日增长飙升至日常 10 倍),并及时触发告警及通知。
- Hive 与 Doris 打通:在基于 Kerberos 认证的 Hive 环境中,对 Doris Hive Catalog 功能进行了二次开发,实现跨系统的直接数据访问,无需依赖 Flink 等同步工具,简化了架构并提升了数据使用效率。
03 负载均衡
为确保系统在负载高峰期的稳定运行,特别是应对异常 SQL 与大查询带来的资源压力,应对措施如下:
- 双机房负载均衡:基于已有的异地双机房架构,通过轮询机制实现业务流量在 A 与 B 机房之间的自动分发:首个 SQL 请求路由至 A,次个请求则导向 B,以此循环,确保双机房负载均衡,避免单点资源过载。
- SQL 参数限制:通过
enable_query_memory_overcommit = false、exec_mem_limit = 256 * 1024 * 1024 * 1024等参数将最大占用内存限制为 256G,避免集群被打满,后续计划降至 60G。 - Workload 资源队列动态调整:基于任务类型划分资源队列,配置 CPU 的软隔离和内存的硬隔离,并支持错峰调度。比如:例行任务通常在夜间执行,为其创建专门资源队列,数据分析等公共任务大多在白天执行,将配置更大的资源队列,随着白天/夜间需求的变化动态调整资源。此外,依据各队列负载设定并行度与并发数,控制任务排队时长。
- 异常 SQL 拦截:实时识别与拦截异常 SQL,避免其影响 BE 节点稳定性。初期使用 Doris 内置正则规则进行拦截,但规则复杂导致 CPU 开销上升。为此,我们将拦截逻辑外移至平台层执行,以避免正则匹配及超大 JOIN 导致的 CPU 负载过高。
04 集群稳定性
随着集群规模不断扩大,保障 FE、BE 节点稳定性成为运维工作的核心挑战,为此,我们构建了以下保障体系:
- 分层触达+全维度覆盖:根据不同指标优先级设置通知电话、短信、飞书提醒,P0 监控准确率 ≥80%;
- 自动异常处理:为 FE 和 BE 的宕机重启设置了自动化处理方案,在识别到服务卡住时,系统会自动重启进程。此外,对于磁盘掉线,将自动下线故障盘并触发副本补齐。
我们同时采用对战分析、火焰图和日志查看等方法进行详细记录,以便后续调优。此外,编写了 SOP 手册,涵盖不同场景的应对措施,并进行了异常处理演练。
结束语
截至目前,我们已搭建 3 个基于 Doris 2.1.10 版本的线上集群,其中最大规模的集群达万 core 级别、上百 TB 内存和 PB 级磁盘。目前仍在扩容中,计划在年底前新增百余台 CN 节点和数十台 Mix 节点。未来,我们将重点关注并探索以下能力:
- 存算分离:重点关注 Doris 3.X 版本的存储分离架构,推动落地实践。
- 湖仓一体:全面打通数据湖与数据仓库,目前已小规模试点 Paimon;此外,针对数据外置场景,计划通过异步物化视图提升查询性能。
- 智能物化视图探索:引入语义建模与 AI 智能分析,降低研发与业务沟通门槛,并对智能推荐与模板化方案进行探索与实践。