
“统一”是 Apache Doris 长期以来秉持的设计理念之一。在这一理念指引下,构建完善的 Catalog 生态是实现异构数据源统一查询分析的关键。目前,Doris 已支持 Iceberg、Paimon、Hudi 等数据湖 Catalog,以及 JDBC Catalog,用户无需迁移数据,即可对不同数据湖和传统数据库进行联邦查询分析。
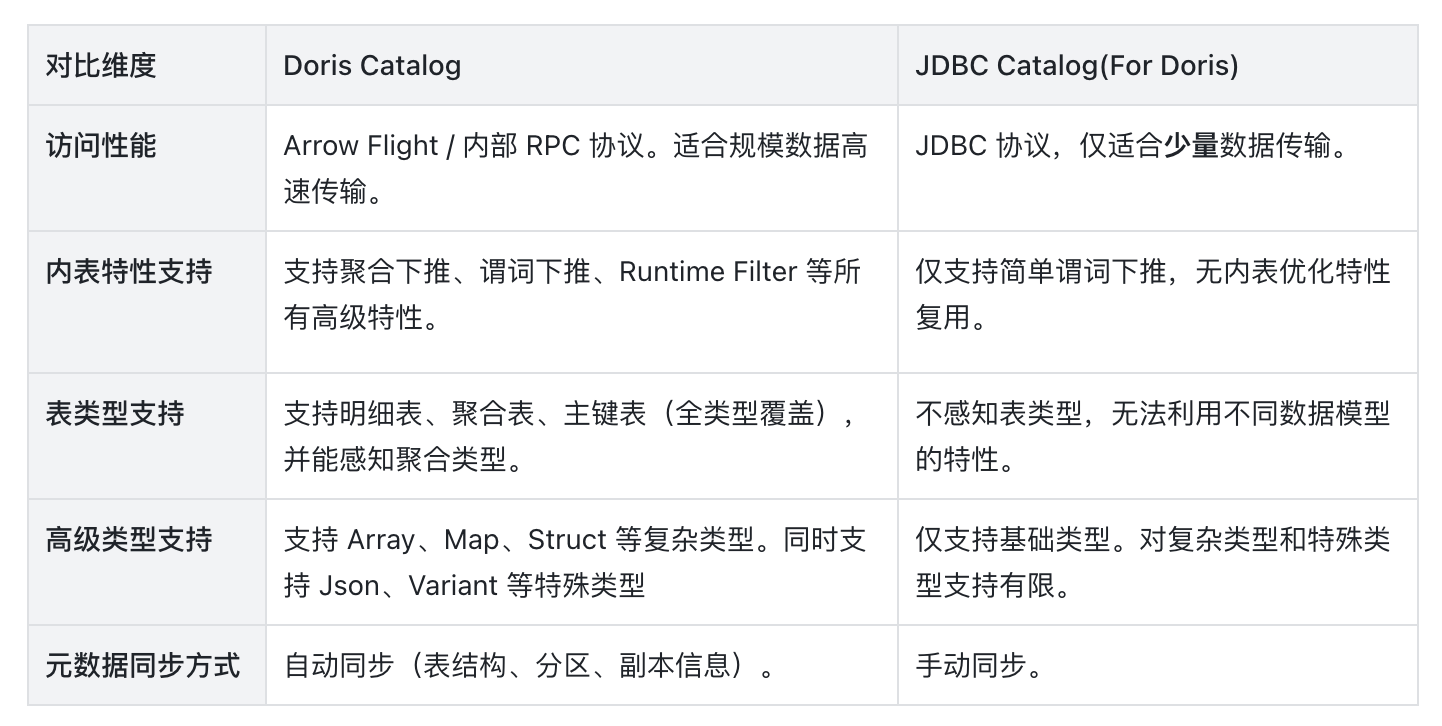
本文聚焦 Doris 多集群间的查询分析。实现跨 Doris 集群的分析通查需要通过 JDBC Catalog,但该方式存在明显短板,比如协议开销较大、无法复用 Doris 查询优化策略、查询性能受限等等。同时,随着生产环境中多 Doris 集群部署愈加普遍,跨集群的数据联动分析需求也日益增长。在这种情况下,JDBC Catalog 很难满足用户的性能要求。
为此,Apache Doris 4.0.2 版本推出重磅特性:Doris Catalog。该功能专为跨 Doris 集群联邦分析设计,支持通过 Arrow Flight 和虚拟集群两种模式,进行更高效、更贴合原生优化的跨集群查询。
特此说明:Doris Catalog 当前为实验性特,欢迎大家体验并反馈,我们将持续优化
Doris Catalog vs. JDBC Catalog
JDBC Catalog 主要借助 MySQL 兼容的 JDBC 协议访问其他 Doris 集群数据。由前文可知,该方式在跨集群大数据量交互时性能受限,难以满足联邦分析高吞吐与低延迟的性能要求。不同于 JDBC Catalog 的交互方式, Doris Catalog 通过 Arrow Flight 或虚拟集群这两种方式,能够直接、高效的访问其他 Doris 集群,进行多集群联邦分析。
01 功能对比
那么,与 JDBC Catalog 相比,Doris Catalog 到底具备哪些能力优势呢?
02 性能对比
为了更直观地展示二者在实际查询中的表现,我们基于跨集群的 TPC-DS 查询场景,对比了 Doris Catalog(两种连接模式) 与 JDBC Catalog 的执行性能。以下是测试结果概要:
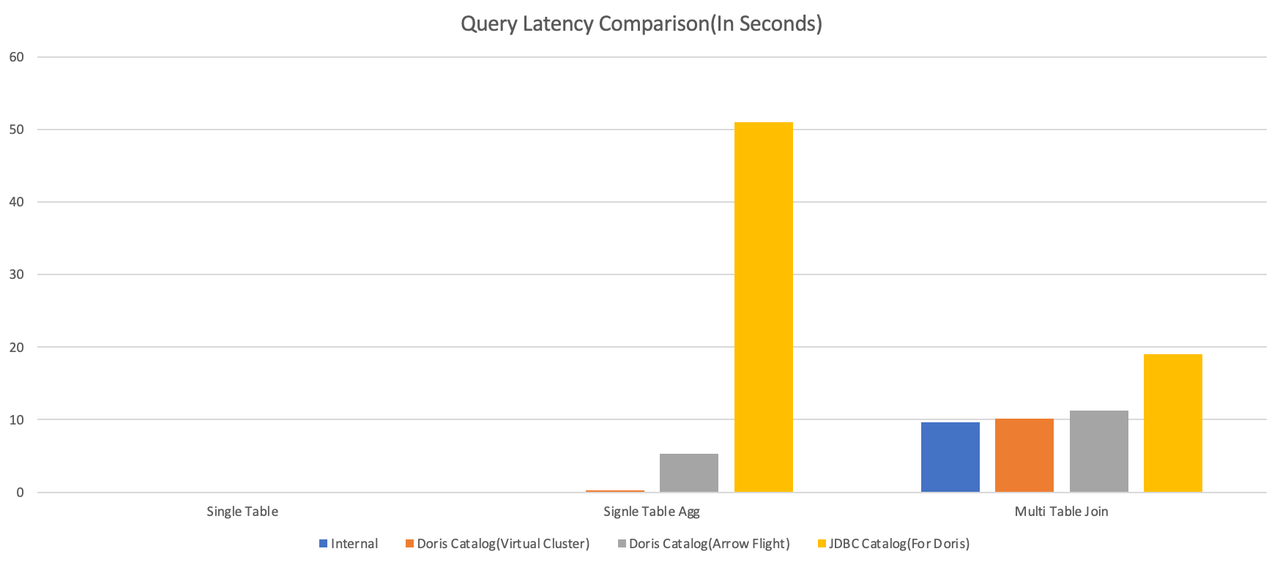
结果显示,在涉及聚合、Join 等复杂查询场景下,Doris Catalog 相比 JDBC Catalog 展现出不同程度的性能优势。其中,在单表聚合查询场景下优势尤为突出:Doris Catalog(虚拟集群)的查询耗时仅为 0.21 秒,相较于 JDBC Catalog,速度提升超过 200 倍。
具体测试如下:
- 在单表简单查询(直接查询远端集群)模式下:Doris Catalog 与 JDBC Catalog 基本持平。
SELECT
ss_sold_date_sk,
ss_store_sk,
ss_item_sk,
ss_ticket_number,
ss_quantity,
ss_sales_price,
ss_ext_sales_price,
ss_net_profit
FROM jdbc_mode.tpcds100.store_sales
WHERE ss_sold_date_sk = 2450816
AND ss_store_sk = 10
AND ss_quantity BETWEEN 1 AND 3
LIMIT 100;

- 在单表聚合查询(直接查询远端集群)模式下:Doris Catalog 两种模式均优于 JDBC Catalog,Doris Catalog(虚拟集群)的查询耗时仅为 0.21 秒,相较于 JDBC Catalog,速度提升超过 200 倍。
SELECT
ss_sold_date_sk,
ss_store_sk,
SUM(ss_ext_sales_price) AS total_sales,
SUM(ss_net_profit) AS total_profit,
COUNT(*) AS txn_cnt
FROM tpcds100.store_sales
WHERE ss_sold_date_sk BETWEEN 2450816 AND 2451179
GROUP BY
ss_sold_date_sk,
ss_store_sk
ORDER BY
ss_sold_date_sk,
ss_store_sk
LIMIT 100;

- 在多表关联查询(两个大表分别存储在本地和远端集群,进行关联查询)模式下:Doris Catalog 两种模式均优于 JDBC Catalog,相较于 JDBC Catalog,速度提升约 42%。
SELECT count(ss_item_sk), count(store_sales_amt), count(catalog_sales_amt) FROM
(
SELECT
ss.ss_item_sk as ss_item_sk,
SUM(ss.ss_ext_sales_price) AS store_sales_amt,
SUM(cs.cs_ext_sales_price) AS catalog_sales_amt
FROM internal.tpcds100.store_sales ss
JOIN external.tpcds100.catalog_sales cs
ON ss.ss_item_sk = cs.cs_item_sk
WHERE ss.ss_sold_date_sk BETWEEN 2450815 AND 2451079
AND cs.cs_sold_date_sk BETWEEN 2450815 AND 2451079
GROUP BY ss.ss_item_sk) x;

03 方案选择
由上可知,不同的查询场景中,需要选择适合的的访问模式,以获取最佳的查询性能:
- 对于复杂 Join/Agg 查询或依赖 Doris 内表优化特性时,优先选择 Doris Catalog 虚拟集群模式。
- 对于简单单表查询、UNION 查询、远端集群规模大且无需复杂 Join 优化或 Doris 集群版本不一致,优先选择 Doris Catalog Arrow Flight 模式。
Doris Catalog 核心设计
Doris Catalog 本质是跨集群访问的“中间代理”,核心职责包括:
- 元数据同步:通过 HTTP 协议从远端 Doris 集群 FE 拉取表结构、分区、副本、 Tablet 位置等元数据;
- 执行计划生成:根据访问模式,将用户查询转换为适配远端集群的执行计划;
- 数据路由与传输:协调本地 BE 与远端 BE 进行数据传输,支持并行拉取与分片处理;
- 结果聚合:将远端返回的数据聚合后,返回给用户或上层应用。
Doris Catalog 支持 Arrow Flight 和 虚拟集群两种访问模式。在了解具体实现之前,先了解两种模式的区别:

01 Arrow Flight 模式
![]()
该模式的工作流程如下(假设本地集群为 ClusterA,远端集群为 ClusterB):
- 查询规划:ClusterA 的 FE 节点先进行完整的查询规划,针对存储在 ClusterB 中的表,生成
RemoteDorisScanNode节点。RemoteDorisScanNode会生成一条应用谓词下推规则后的单表查询 SQL,通过 HTTP 协议向 ClusterB 的 FE 节点发送并执行这条 Arrow Flight SQL。 - 查询计划执行:ClusterA 的 FE 节点将物理执行计划发送给 ClusterA 的 BE 节点,并告知 BE 节点 Arrow Flight 的数据流获取位置。
- 数据查询与传输:ClusterA 的 BE 节点的 Scan Node 通过 Arrow Flight 协议直接从 ClusterB 的 BE 节点获取 Arrow Flight SQL 的执行结果。然后在 ClusterA 中执行 Join、Agg 等其他算子,并返回最终结果。
02 虚拟集群模式
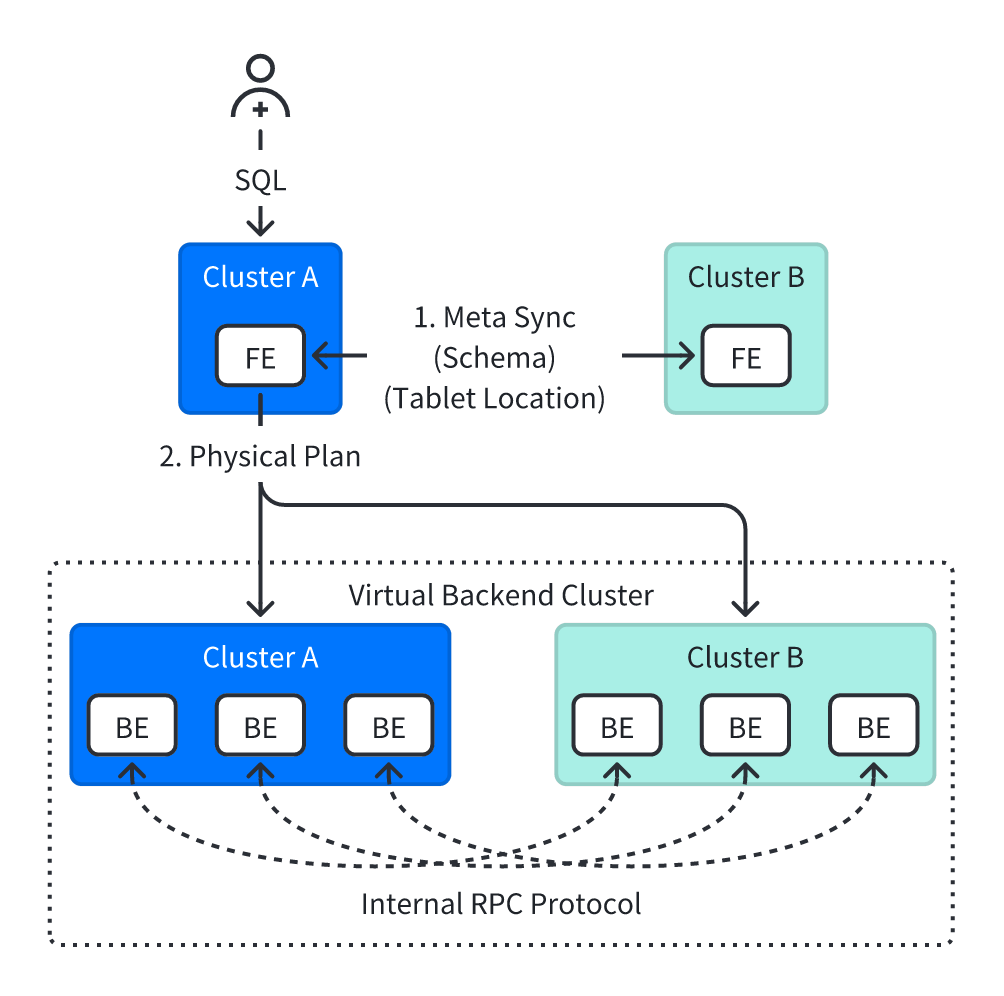
该模式的工作流程如下(假设本地集群为 ClusterA,远端集群为 ClusterB):
- 元数据同步:ClusterA 的 FE 节点通过 HTTP 协议同步 ClusterB 中完整的元数据,包括表结构、分区、副本、Tablet 位置等。
- 查询规划:ClusterA 的 FE 节点将 ClusterB 的 BE 节点视为“虚拟 BE”,生成全局统一的执行计划(与单集群查询逻辑一致)。
- 查询计划执行:执行计划会将 ClusterA 与 ClusterB 的 BE 节点视作一个统一 BE 集群,并在其上执行查询计划。因此,各类算子会同时在 ClusterA 和 ClusterB 的 BE 节点中执行。
- 数据查询与传输:ClusterA 与 ClusterB 的 BE 节点间使用内部通信协议进行数据交互。
实战演示:10 分钟完成跨集群订单履约率分析
回归到实际使用中,Doris Catalog 可有效支撑以下五大核心业务场景,精准解决跨集群分析痛点:
多业务集群联合分析:如在电商场景中,交易集群存储订单数据、物流集群存储履约数据,通过 Doris Catalog 直接关联计算“订单履约率”“物流时效”等核心指标,无需跨集群数据同步。
地域分布式集群全局统计:如零售企业在多地域部署 Doris 集群,通过 Doris Catalog 一站式汇总各区域销售数据,实时计算全国总销售额、区域占比、用户活跃度等全局指标。
实时数据跨集群关联查询:如用户行为分析场景中,通过 Doris Catalog 实时关联用户实时行为集群(点击、浏览等)与长期用户画像集群,支撑个性化推荐、精准营销等实时决策场景。
跨地域超大规划集群分治:不同地域的分公司采用相同的业务模式部署和使用 Doris 集群。母公司通过 Doris Catalog 完成对全地域多集群的集中访问,实现超大规模业务数据管理。
跨集群数据迁移验证与对比分析:新旧集群迁移过程中,通过 Doris Catalog 直接对比两端数据一致性,无需导出导入工具,简化迁移验证流程,降低数据丢失风险。
接下来,我们以常见场景 1:多业务集群联合分析为例,实战演示如何在 10 分钟完成跨集群订单履约率分析。
1、背景介绍 现有两个 Doris 集群,需跨集群关联计算核心业务指标:
- 本地集群(Trading-Cluster):存储订单基础数据,库表为
trading_db.order_info(订单表); - 远端集群(Logistics-Cluster):存储物流履约数据,库表为
logistics_db.delivery_info(履约表); - 业务需求:计算近 7 天各订单类型的履约率(已履约订单数/总订单数),支撑运营决策。
2、表结构定义
- 本地订单表
trading_db.order_info:CREATE TABLE trading_db.order_info ( order_id STRING COMMENT '订单ID', order_type STRING COMMENT '订单类型:实物订单/虚拟订单', create_time DATETIME COMMENT '创建时间', amount DECIMAL(10,2) COMMENT '订单金额' ) ENGINE=OLAP DUPLICATE KEY(order_id) PARTITION BY RANGE(create_time) ( PARTITION p202511 VALUES [('2025-11-01 00:00:00'), ('2025-12-01 00:00:00')) ) DISTRIBUTED BY HASH(order_id) BUCKETS 10;
- 远端履约表
logistics_db.delivery_info:CREATE TABLE logistics_db.delivery_info ( order_id STRING COMMENT '订单ID', delivery_status TINYINT COMMENT '履约状态:1-已履约,0-未履约', delivery_time DATETIME COMMENT '履约时间' ) ENGINE=OLAP DUPLICATE KEY(order_id) PARTITION BY RANGE(delivery_time) ( PARTITION p202511 VALUES [('2025-11-01 00:00:00'), ('2025-12-01 00:00:00')) ) DISTRIBUTED BY HASH(order_id) BUCKETS 10;
3、数据准备 向两张表分别插入测试数据(本地表 100 万行订单数据,远端表 80 万行履约数据),确保订单 ID 存在关联关系。 4、配置 Doris Catalog 在本地 Doris 集群执行以下 SQL,创建连接远端物流集群的 Catalog(虚拟集群模式):
-- 创建Doris Catalog,启用虚拟集群模式(复用内表优化)
CREATE CATALOG IF NOT EXISTS logistics_ctl PROPERTIES (
'type' = 'doris', -- 固定类型
'fe_http_hosts' = 'http://logistics-fe1:8030,http://logistics-fe2:8030', -- 远端FE HTTP地址
'fe_arrow_hosts' = 'logistics-fe1:8040,http://logistics-fe2:8040', -- 远端FE Arrow Flight地址
'fe_thrift_hosts' = 'logistics-fe1:9020,http://logistics-fe2:9020', -- 远端FE Thrift地址
'use_arrow_flight' = 'false', -- false=虚拟集群模式,true=Arrow Flight模式
'user' = 'doris_admin', -- 远端集群登录用户
'password' = 'Doris@123456', -- 远端集群登录密码
'compatible' = 'false', -- 集群版本接近(4.0.3 vs 4.0.2),无需兼容
'query_timeout_sec' = '30' -- 延长查询超时时间(默认15秒)
);
5、跨集群查询
- 切换 Catalog 后查询
-- 切换到远端物流集群的Catalog SWITCH logistics_ctl; -- 使用本地订单库 USE trading_db; -- 关联本地订单表与远端履约表,计算履约率 SELECT o.order_type, COUNT(DISTINCT o.order_id) AS total_orders, COUNT(DISTINCT CASE WHEN d.delivery_status = 1 THEN o.order_id END) AS delivered_orders, ROUND(COUNT(DISTINCT CASE WHEN d.delivery_status = 1 THEN o.order_id END) / COUNT(DISTINCT o.order_id), 4) * 100 AS delivery_rate FROM internal.trading_db.order_info o JOIN delivery_info d ON o.order_id = d.order_id WHERE o.create_time >= DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY) GROUP BY o.order_type ORDER BY delivery_rate DESC;
- 全限定名查询
SELECT o.order_type, COUNT(DISTINCT o.order_id) AS total_orders, COUNT(DISTINCT CASE WHEN d.delivery_status = 1 THEN o.order_id END) AS delivered_orders, ROUND(COUNT(DISTINCT CASE WHEN d.delivery_status = 1 THEN o.order_id END) / COUNT(DISTINCT o.order_id), 4) * 100 AS delivery_rate FROM internal.trading_db.order_info o JOIN logistics_ctl.logistics_db.delivery_info d ON o.order_id = d.order_id WHERE o.create_time >= DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY) GROUP BY o.order_type ORDER BY delivery_rate DESC;
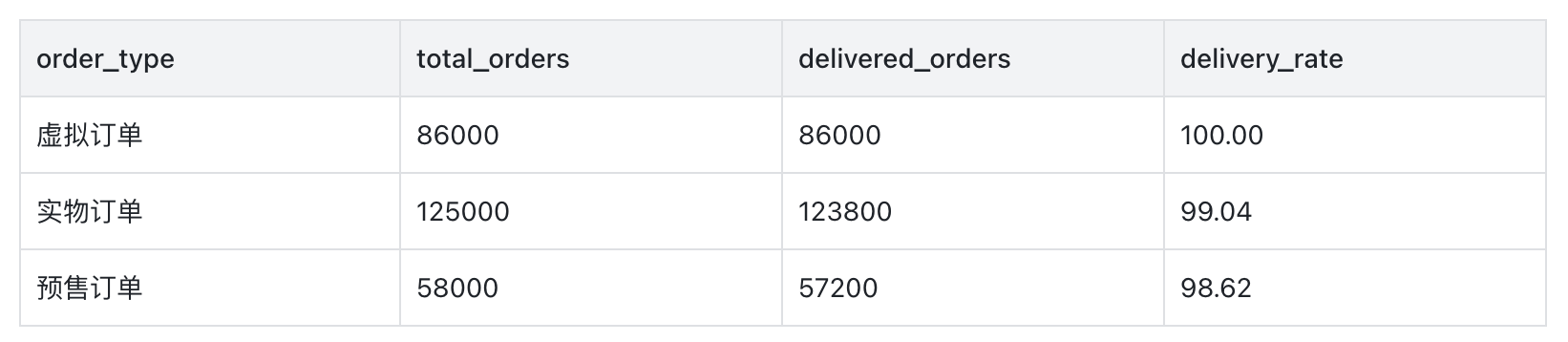
6、查询结果与优化验证
- 执行结果示例
- 优化特性验证
- 执行
EXPLAIN查看执行计划,可发现: - 虚拟集群模式下,执行计划中远端表扫描节点为
VOlapScanNode(与本地表一致),说明复用了 Doris 内表扫描优化; - Join 操作中自动启用
Runtime Filter,减少远端数据传输量。
- 执行
总结与展望
Doris Catalog 的推出,补齐了 Doris 跨集群联邦查询的性能短板。在此特别感谢社区同学的 Chen768959 和 HonestManXin 贡献,帮助延续了 Doris Catalog 生态“无需迁移、一站式分析”的核心优势,让多 Doris 集群从“数据孤岛”变为“互联一体”。
作为实验性特性,Doris Catalog 后续将持续迭代优化:
- 增强 Arrow Flight 模式,使其能够访问任意支持标准 Arrow Flight 协议的数据源。
- 降低虚拟集群模式 FE 内存开销,优化元数据存储和同步策略;
- 支持存算分离部署的 Doris 集群(虚拟集群模式)
- 新增更多监控指标,方便排查跨集群查询故障。
更多信息,请访问 Doris 官网文档:
https://doris.apache.org/zh-CN/docs/4.x/lakehouse/catalogs/doris-catalog


