
中通快递作为快递行业领军企业之一,年包裹数达数百亿件,市场份额稳定在 20% 左右,展现出强劲的市场竞争力和持续发展态势。在业务规模持续扩张下,其对大数据基础设施建设要求日益提高,对数据处理及分析的需求也持续增加。
中通快递原先使用以 Hadoop 为核心的离线数仓,但随着数据的不断增长、数据处理需求不断变化, Hadoop 这一多套异构的复杂架构逐步暴露瓶颈,面临数据时效性、查询性能、并发能力、维护成本等多种挑战。
在此背景下,引入基于 Apache Doris 内核的 SelectDB 构建了湖仓分析架构,补齐 OLAP 分析能力,为离线、实时分析提供了高效的查询能力。在离线场景中,实现 2000+ QPS 并发点查;在实时场景中,仅以 1/3 原集群机器数量覆盖所有业务,90% 分析任务从 10 分钟缩短至 1 分钟内,投入产出比大幅提升。
一、早期架构及挑战
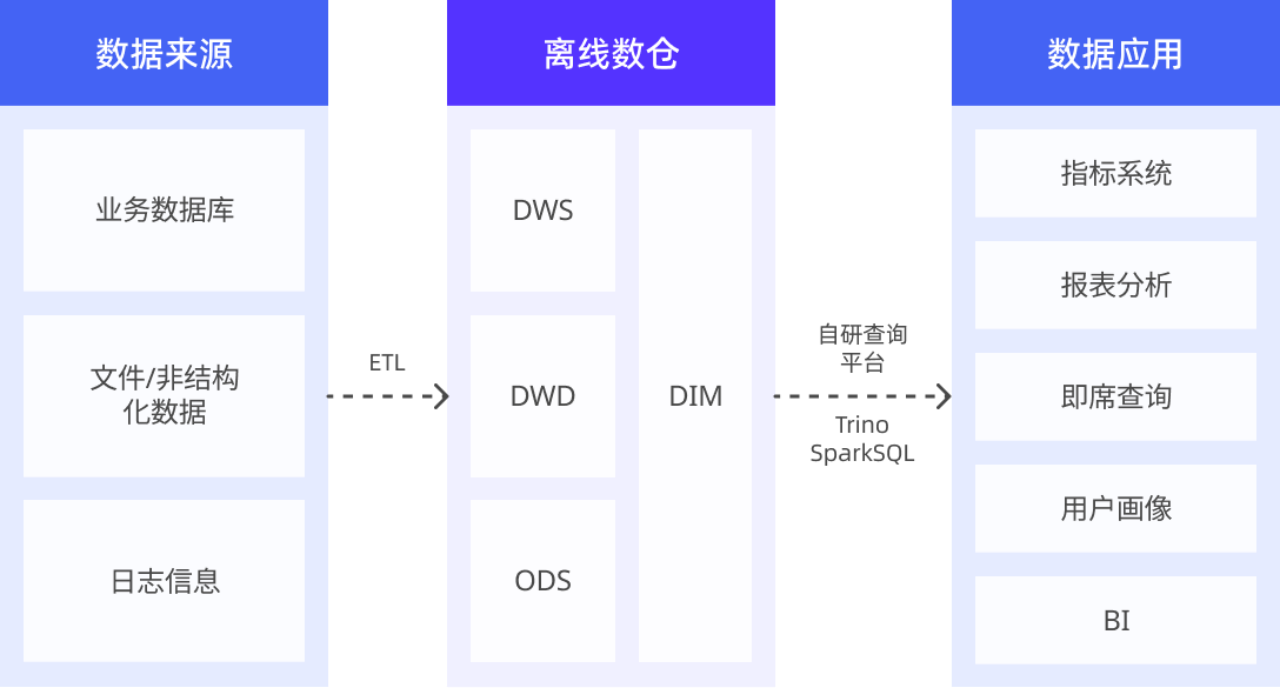
在引入 SelectDB 之前,中通基于 Hadoop 构建离线数仓应对数据分析需求。在业务量高速增长的背景下,该架构面临严峻挑战:
- 数据时效性不足:离线数仓 T+1 数据抽取产出模式无法满足报表和数据大盘实时更新的需求;
- 查询性能较差:离线数仓读取、写入等操作均基于 HDFS 进行,耗时普遍为分钟级别,以及 Spark SQL 的处理时间亦为分钟级,严重影响查询效率,无法支持需要秒级响应的交互式分析场景。
- 查询稳定性与高并发支持能力弱:在超大的 Hadoop 集群规模下,NameNode 的轻微抖动就会严重影响短平快的即席查询和报表分析的稳定性,Trino 在处理高并发查询时效率也远低于预期,难以支撑日益增长的高并发需求。
二、基于 SelectDB 的湖仓分析架构
随着业务的不断发展,昔日双 11 的业务高峰现已成为每日常态。为了满足各大场景对实时分析时效的要求,并确保数据的快速写入和高效查询,亟需合适的 OLAP 引擎来补充现有架构。
1. 技术选型
中通技术团队通过深入的技术调研和测试验证,了解到 基于 Apache Doris 内核构建的 SelectDB。SelectDB 以高效的向量化引擎、Pipeline 执行模式、完善的缓存机制支持、高度兼容的 SQL 语法以及灵活的湖仓分析能力吸引了他们
为了验证 SelectDB 向量化引擎和 Pipeline 执行模式的高性能查询能力,团队进行了多轮对比测试,以评估二者之间的性能差异:
- 在生产环境 SQL 测试中,单表 100GB 数据量的查询场景下,SelectDB 相比 Trino 有 1-2 倍的性能提升;
- 在 1TB TPC-DS 标准测试中,SelectDB 完成 99 个查询的总耗时仅为 Trino 的 1/5。
2. 湖仓分析实时架构
中通基于 SelectDB 构建了新一代的湖仓分析架构,其核心是将 SelectDB 作为统一、高性能的查询加速引擎覆盖在数据湖之上。数据依然存储在 Hive 数据湖中,保持其经济性和容纳海量原始数据的能力。
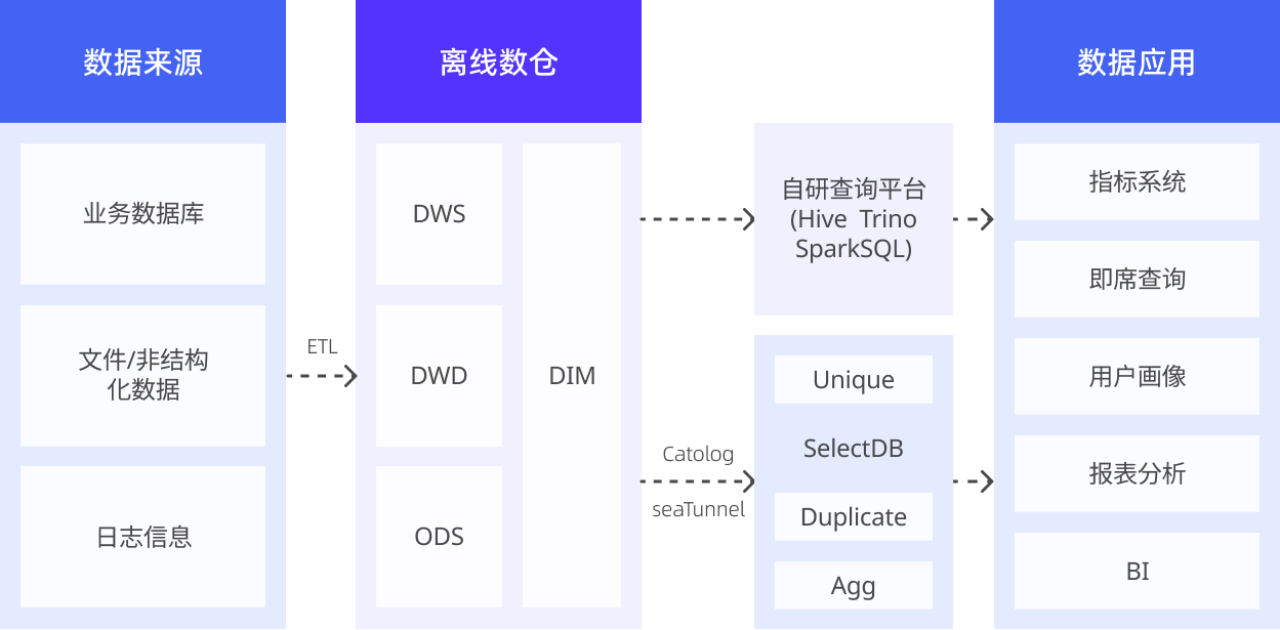
具体而言,SelectDB 通过 Multi-Catalog 直接对接 Hive Metastore,无需数据迁移即可创建外部表,实现对 Hive 湖中数据的直接、高速查询。为了进一步提升查询体验,中通广泛采用了 SelectDB 的缓存加速、数据预热、索引体系、分区分桶等能力,有效保障了系统的稳定性及查询的高效性。
截止当前,在 OLAP 分析层面, Trino 集群规模已超过 130 台,日峰值响应接近 56 万个查询。相比之下,SelectDB 虽仅拥有三套集群规模,总数为 60 台,但日峰值响应量接近 90 万个查询。这一数据表明,SelectDB 在实时计算的响应能力方面具有显著优势,能够更加高效地满足大量查询需求。
三、场景实践
1. BI 报表与离线分析
在 BI 报表和离线分析场景中,原有 Trino 架构面临查询稳定性差和并发能力不足的双重挑战。特别是在早高峰时段,业务人员集中访问报表系统,频繁出现查询超时和系统卡顿。同时,Trino 和 SparkSQL 在在面对高并发查询时,处理效率与预期存在较大差距。
在查询超时问题上,我们开启了数据缓存(Data Cache)功能,并配置大容量本地磁盘,将热数据持久化缓存。在每日数据就绪后,通过定时任务触发对关键报表数据的预加载,使其在业务高峰前已缓存至本地。避免了查询延迟高的问题,同时降低早高峰期间集中访问导致带宽拉满的问题。在同等查询量下,SelectDB 的慢 SQL(>10s)仅为 Trino 的百分之一。
在高并发查询挑战的应对上,中通快递在实时数仓建设阶段,将离线数据 DIM 维度层、应用层的数据通过 SeaTunnel 写入了 SelectDB 中,实现了结果表的查询加速。从而实现 2000+ QPS 并发点查,数据报表更新及时度大大提高。
其次,SelectDB 提供了灵活丰富的 SQL 函数公式,并拥有高吞吐量的计算能力,数据分析师、产品经理等业务人员通过可视化报表工具 + SelectDB 即可基本满足 BI 的数据探索需求,大部分查询响应速度都在秒级完成。
该场景下,在保持高性能、高并发的同时,显著节约了计算资源,SelectDB 集群规模约为 Trino 的 1/4。
2. 实时数据分析
面向决策层和运营监控的实时数据大屏,对查询时效性要求极高,需要支持灵活的多维筛选和聚合分析。该场景涉及一张日增量超 6 亿、总量超 45 亿、字段超 200 列的超级宽表,并需基于该宽表进行分钟级准实时分析。
原有 OLAP 引擎在任务增多时,负载过高时,任务执行时效难以保证。比如,当总任务数超 50 时,执行时间达 5-10 分钟,效率极为低下。
因此,基于 SelectDB 以下特性成功解决上述问题:
- 查询加速:借助倒排、BloomFilter 来支持多维分析,通过合理的分区分桶,在查询时过滤非必要的数据,使数据扫描快速定位,加速查询响应时间。使 90% 以上的查询从 10 分钟左右缩短到 1 分钟内,部分达到秒级,性能提升 10 倍。
- 数据写入秒级可见:SelectDB 支持主键表(Unique Key),并对 Upsert、条件更新/条件删除、部分列更新、分区覆盖等各类更新提供了完备的支持,借助 Flink,可完成对数据的秒级可见,满足高效灵活的数据更新需求
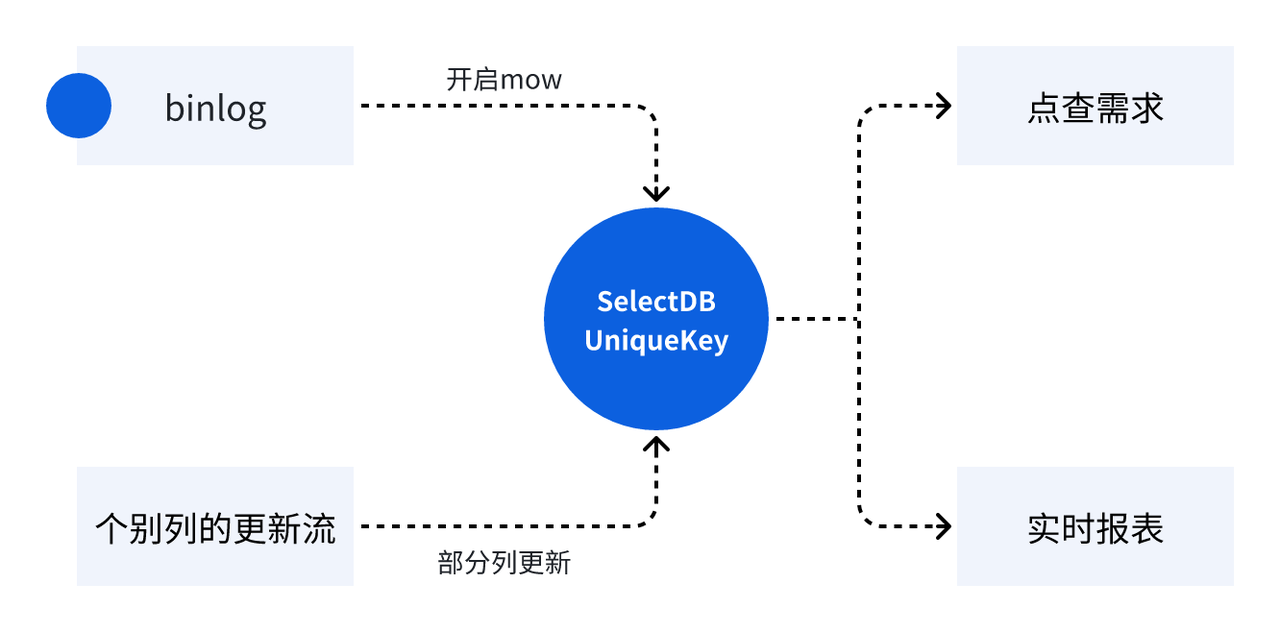
注意:对表结构的设计需要结合业务、因地制宜,合理规划 Key 和分区分桶列,一般将 where 条件或者 join 的字段定义成分桶较为合适
在该场景下,SelectDB 仅使用原集群 1/3 的资源就覆盖了所有业务,实现了高效且经济的运行。满足了业务方对数据“既快又准”的严格要求,提升了监控和决策的效率。
四、成果及价值
中通引入 SelectDB 后,查询性能实现巨大飞跃,延迟大幅下降,并发能力显著提升,同时成本大幅降低,系统稳定性与易维护性也得到增强。
未来,中通将会深化与 SelectDB 的合作:
- 提升易用性:利用 SelectDB 提供的更精炼、直观的 Profile 信息,降低 SQL 调优的难度和复杂度,提升开发运维效率;
- 增强系统可观测性:强化文件缓存等功能的可观测性,加强数据倾斜处理能力,以提升整个系统的可靠性与可维护性;
- 深化湖仓一体:加强 Multi Catalog 功能的应用,提升湖仓分析能力,并测试 SelectDB 读写 Hive 外表的能力,实现更灵活的数据流转;
- 打通权限与集成:推动实现 Hive Catalog 权限通过 JDBC 账号的透传,与公司现有大数据权限体系无缝融合,确保数据安全。


