摘要
本文基于 ClickBench 数据集,展示了 Apache Doris 如何通过选择压缩算法、调整数据页大小与分桶数、优化编码策略以及改进数据排序来提升压缩效率。最终,相同数据集的压缩空间从 16.08 GB 降至 8.2 GB,压缩率提升 48.6%。通过合理的调整与优化,Doris 成功在保持查询性能的同时显著降低了存储成本。
在分析型数据库中,列式存储是压缩和查询性能的核心基础。它按列组织数据,同一列值类型一致且分布相似,为编码与压缩算法提供极高空间局部性和可预测性。当存储的值变化较小或重复频繁时,列式布局能够减少冗余存储,并提升向量化扫描的 CPU 效率。
Apache Doris 作为一款典型的列式存储引擎,可独立存储每一列数据。导入时,每列数据写入近似固定大小的数据页,经过编码和压缩处理,以实现更紧凑的存储。在 Doris 中,数据的压缩和解压均以数据页为单位,压缩算法的上下文限制在单个数据页内。因此,数据页大小、编码方式及压缩算法都直接影响最终的压缩效率和查询性能。
在接下来的章节中,我们将结合基于 ClickBench 数据集,较为直观的展示 Apache Doris 在存储压缩方面的优化思考及改进策略。 使读者了解如何通过数据页大小与分桶数调整、编码策略优化、数据排序来提升压缩效率。
一、数据集与基线结果
我们使用 ClickBench 公共数据集来进行本次测试。该数据集包含 10 个 tsv 文件,总大小约 70GB,包括网站访问日志类字段,如 URL、Referer、UserID 等。这类数据通常混合了短字符串与整数列,结构化特征明显。
在导入前先对原始数据进行文件级压缩测试,以作为基线参考:
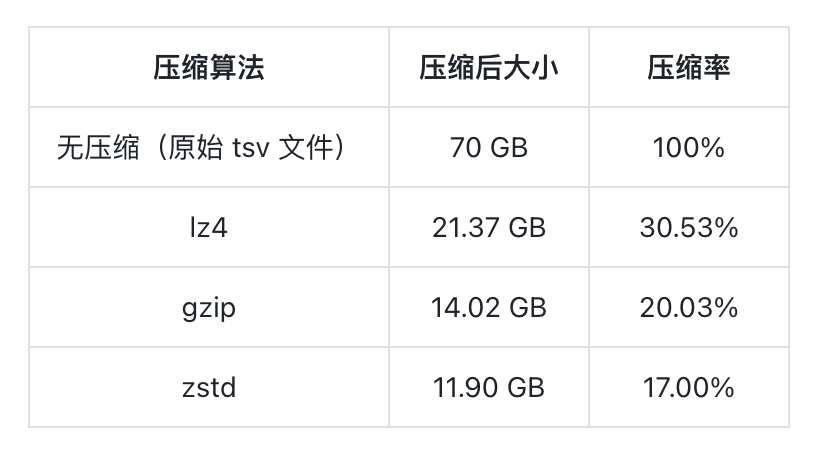
随后将这批数据直接导入 Doris。使用默认建表参数,建表语句可参考:https://github.com/apache/doris/blob/master/tools/clickbench-tools/sql/create-clickbench-table.sql
数据导入后,整体存储空间约为 16.08 GB。在 Doris 的列式存储下,经过默认 LZ4 压缩,已实现相较于原始文件(21.37 GB)1.33x 倍的压缩效果。但如果从一个以高压缩比著称的列式系统角度来看,这一结果仍存在进一步的优化空间。
接下来从研发角度出发,依次对压缩算法、数据页参数与编码方式、数据排序及特征等层面介绍优化及改进思路。
二、选择合适的压缩算法
Doris 默认使用 LZ4 压缩算法,因其解压速度快且 CPU 占用均衡,适合大多数查询型负载。而在重复性强或结构化明显的数据场景中,LZ4 的压缩比较低。相较之下,ZSTD 提供更高的压缩率,但会增加压缩和解压的 CPU 消耗。在使用时,可根据实际情况灵活选择。
考虑到测试数据集中大量字符串字段存在相似前缀与重复片段的特征,我们将默认的 LZ4 压缩算法调整为 ZSTD,这可以通过在建表语句中设置表属性实现:
CREATE TABLE IF NOT EXISTS hits (
....
)
DUPLICATE KEY (CounterID, EventDate, UserID, EventTime, WatchID)
DISTRIBUTED BY HASH(UserID) BUCKETS 48
PROPERTIES (
"replication_num"="1",
"compression"="ZSTD");
经过该调整,表空间降至 12.9GB,相比 LZ4 减少了近 20%。虽然在导入阶段 CPU 开销略有上升,但查询性能几乎不受影响,表明 ZSTD 对典型分析型查询的解压成本是可接受的。
三、调整数据页大小与分桶数
在 Doris 的列式存储中,数据压缩的基本单位是数据页。每个数据页在写入之前经过编码与压缩,页内数据的相似程度直接影响通用压缩算法的效果。数据页的大小选择影响压缩效率与查询性能的平衡:过小的页无法形成可识别的模式,而过大的页会增加读取开销和内存负担。
Doris 默认数据页大小为 64KB,适合大部分场景。然而,对于具有明显模式或高重复率的数据集,过小的页会使数据被切得太碎,通用压缩算法的效率会变差。因此,适当增大页的大小可显著提升压缩效果。更大的页可覆盖更多连续数据,聚集相似值于同一压缩上下文内,让压缩算法更充分地挖掘重复模式与统计特征。
对于测试数据集来说,我们选择将页大小从默认的 64KB 调整为 1MB,并同时将分桶数从 48 减少到 4。分桶数越多,每个桶的数据越少,页内数据的相似性降低,压缩率就会下降。通过让数据集中到更少的桶中,可以提高页内数据的相似性,从而带来更好的压缩效果。
CREATE TABLE IF NOT EXISTS hits (
....
) DUPLICATE KEY (CounterID, EventDate, UserID, EventTime, WatchID)
DISTRIBUTED BY HASH(UserID) BUCKETS 4
PROPERTIES (
"replication_num"="1",
"compression"="ZSTD",
"storage_page_size"="1048576");
经过测试,存储空间进一步减小到 10.71 GB。页更大、桶更少,使得压缩算法更有效去除冗余。
不过,页大小和分桶数并非越大越好。比如,在高并发查询的场景中,过大的页可能导致额外的 I/O 开销;而在分析型和离线统计类负载中,1MB 的页与较少的分桶数通常能取得最佳效果。因此,最佳取值应根据数据规模、查询模式与导入方式进行综合考虑。
四、优化编码方式
此外,数据在页内的编码方式也与列式存储压缩效果密切相关。Doris 针对不同类型的数据采用了多种编码策略:对整数默认使用 Bitshuffle 编码 + LZ4 压缩,对字符串则使用字典编码或纯二进制编码。这些编码在大多数场景中表现优异,但仍有进一步优化的空间。
01 问题定位
为明确编码方式的改进方向,我们在 Doris 中新增一个系统表:information_schema.column_data_sizes。它精确展示每一列在压缩前后的空间占用情况(压缩前uncompressed_bytes、压缩后compressed_bytes、原始数据raw_data_bytes)以及根据这些数据计算出的压缩比(ratio=compressed_bytes/uncompressed_bytes)。在系统表中执行如下查询:
SELECT
COLUMN_NAME, COLUMN_TYPE,
sum(COMPRESSED_DATA_BYTES) AS compressed_bytes,
sum(UNCOMPRESSED_DATA_BYTES) AS uncompressed_bytes,
sum(RAW_DATA_BYTES) AS raw_data_bytes,
round(sum(COMPRESSED_DATA_BYTES) * 100.0 / sum(UNCOMPRESSED_DATA_BYTES), 2) as ratio
FROM information_schema.column_data_sizes
WHERE table_id = 1761704935641
GROUP BY COLUMN_NAME, COLUMN_TYPE
ORDER BY sum(COMPRESSED_DATA_BYTES) DESC;
查询结果如下(部分节选):
+-----------------------+-------------+------------------+--------------------+----------------+--------+
| COLUMN_NAME | COLUMN_TYPE | compressed_bytes | uncompressed_bytes | raw_data_bytes | ratio |
+-----------------------+-------------+------------------+--------------------+----------------+--------+
| URL | STRING | 1747139004 | 9404393858 | 9038895826 | 18.58 |
| Referer | STRING | 1552943801 | 7023847152 | 6662498316 | 22.11 |
| Title | STRING | 1480554020 | 9838412581 | 9488276782 | 15.05 |
| OriginalURL | STRING | 810663093 | 5680006400 | 5317485214 | 14.27 |
| WatchID | BIGINT | 781560948 | 781560948 | 799979976 | 100.00 |
| URLHash | BIGINT | 760852247 | 766458338 | 799979976 | 99.27 |
| RefererHash | BIGINT | 743785927 | 747950617 | 799979976 | 99.44 |
| FUniqID | BIGINT | 389556325 | 512285220 | 799979976 | 76.04 |
| UserID | BIGINT | 379008085 | 495166618 | 799979976 | 76.54 |
| HID | INT | 371392630 | 371392630 | 399989988 | 100.00 |
+-----------------------+-------------+------------------+--------------------+----------------+--------+
从结果可知出,字符串列(URL, Referer, Title, OriginalURL)占据了压缩后大部分空间,而部分 BIGINT 列(WatchID,URLHash,RefererHash)的压缩率几乎是 100%。这说明字符串编码方式和整数编码方式还需优化。
02 字符串编码优化
这些存储占用大的字符串列(如 URL 与 Title)的长度大多都很短,平均长度不超过百字节。在 Doris 默认的字符串编码策略中,这类数据的存储方式并不完全高效。
字符串列默认采用 字典编码 与 Plain Binary 编码 的混合策略:系统在 segment 级别范围内优先对一列数据构建字典页,将重复字符串以索引形式存储,以减少空间占用;当字典页超过设定大小上限时(默认 256KB),后续数据自动退化为 Plain Binary 格式,其布局如下:
| binary1 | binary2 | ... | offset1 (fixed uint32) | offset2 (fixed uint32) | ...
这种格式在页尾维护了一个定长的 uint32 数组,记录每个字符串在页内的偏移位置。而当短字符串量较多时,固定 4 字节的 offset 数组浪费空间。以 10 万条短字符串为例,仅 offset 数组就需要约 400 KB,这是一笔不小的开销,且压缩算法几乎无法对其有效压缩。
为了解决这一问题,我们重新设计了页内字符串的布局,将存储方式调整为“长度 加 内容”顺序写入:
| length1 (varuint32) | binary1 | length2 (varuint32) | binary2 | ...
这种设计省去了独立的 offset 数组,通过变长整数(varuint32)直接记录字符串长度,提高页空间利用率。同时,数据的局部性得到改善,压缩算法(如 ZSTD)可以更有效地捕捉重复模式。经过修改,字符串列的存储空间进一步下降:
+-----------------------+-------------+------------------+--------------------+----------------+--------+
| COLUMN_NAME | COLUMN_TYPE | compressed_bytes | uncompressed_bytes | raw_data_bytes | ratio |
+-----------------------+-------------+------------------+--------------------+----------------+--------+
| URL | STRING | 1455177520 | 9057197818 | 9038895826 | 16.07 |
| Referer | STRING | 1331679271 | 6730874117 | 6662498316 | 19.78 |
| Title | STRING | 1122300920 | 9505664009 | 9488276782 | 11.81 |
| WatchID | BIGINT | 800004249 | 800004249 | 799979976 | 100.00 |
| OriginalURL | STRING | 768372911 | 5402777190 | 5317485214 | 14.22 |
+-----------------------+-------------+------------------+--------------------+----------------+--------+
03 整数编码的优化
在进一步分析 BIGINT 列(如 WatchID、URLHash)时,我们发现其数据分布特征与普通递增或低熵数据截然不同。这些列通常是哈希值或全局唯一 ID,熵值很高,默认使用的 Bitshuffle 编码加 LZ4 压缩效果几乎为零。
基于这一发现,通过设置 integer_type_default_use_plain_encoding=false 禁用了对这些列的 Bitshuffle 编码+ LZ4 压缩,直接写入原始字节序列再通过通用压缩算法压缩。这样省去无效的 Shuffle 操作和 Padding,结合 ZSTD 压缩算法,整体空间还略有下降,写入和读取性能也有所提升。
+-----------------------+-------------+------------------+--------------------+----------------+--------+
| COLUMN_NAME | COLUMN_TYPE | compressed_bytes | uncompressed_bytes | raw_data_bytes | ratio |
+-----------------------+-------------+------------------+--------------------+----------------+--------+
| WatchID | BIGINT | 800004249 | 800004249 | 799979976 | 100.00 |
| URLHash | BIGINT | 348739226 | 800004249 | 799979976 | 43.59 |
| RefererHash | BIGINT | 295833828 | 800004249 | 799979976 | 36.98 |
| FUniqID | BIGINT | 169720968 | 800004249 | 799979976 | 21.22 |
| UserID | BIGINT | 169536965 | 800004249 | 799979976 | 21.19 |
+-----------------------+-------------+------------------+--------------------+----------------+--------+
04 优化效果
基于字符串和整数编码方式的改进,结合前面压缩算法与页参数的调整,表空间从最初的 16.08 GB 进一步降至 8.27 GB,整体压缩率较初始阶段提升约 48.6%。在此基础上,基于 ClickBench 查询集的测试结果显示,系统在热查询场景下保持了与原有版本相同的性能,而在冷查询场景下的性能提升近一倍,实现了压缩率与查询效率的双重收益。

五、数据本身的排序与特征
数据的排序与特征也是决定压缩效率的关键因素,常被忽视。列式存储的压缩效果依赖于相邻数据的相似性,若表的数据分布或排序与列值变化方向不一致,相似性将被打散,压缩算法难以识别模式。
在实际测试中,这种排序差异的影响非常显著。以刚才测试的 ClickBench 数据为例,通过系统表 information_schema.column_data_sizes,我们发现占用空间最大的列是 URL 列,压缩后约为 1.36 GB。
SELECT
COLUMN_NAME,COLUMN_TYPE,
sum(COMPRESSED_DATA_BYTES) AS compressed_bytes,
sum(UNCOMPRESSED_DATA_BYTES) as uncompressed_bytes,
sum(RAW_DATA_BYTES) as raw_data_bytes,
round(sum(COMPRESSED_DATA_BYTES) * 100.0 / sum(UNCOMPRESSED_DATA_BYTES), 2) as ratio
FROM information_schema.column_data_sizes
WHERE table_id=1761728747278
GROUP BY COLUMN_NAME, COLUMN_TYPE
ORDER BY sum(COMPRESSED_DATA_BYTES) desc limit 1;
+-----------------------+-------------+------------------+--------------------+----------------+--------+
| COLUMN_NAME | COLUMN_TYPE | compressed_bytes | uncompressed_bytes | raw_data_bytes | ratio |
+-----------------------+-------------+------------------+--------------------+----------------+--------+
| URL | STRING | 1456833417 | 9144581584 | 9038895826 | 15.93 |
+-----------------------+-------------+------------------+--------------------+----------------+--------+
将该列数据导入到一个仅包含 URL 一列并按照 URL 排序的新表中:
create table t1(
`URL` varchar(8000) NOT NULL
) DUPLICATE KEY (URL)
DISTRIBUTED BY HASH(URL) BUCKETS 1
PROPERTIES ( "replication_num"="1", "storage_page_size"="1048576");
insert into t1 select URL from hits;
查看新表中该列的数据大小,为 0.72 GB:
+-------------+-------------+------------------+--------------------+----------------+-------+
| COLUMN_NAME | COLUMN_TYPE | compressed_bytes | uncompressed_bytes | raw_data_bytes | ratio |
+-------------+-------------+------------------+--------------------+----------------+-------+
| URL | VARCHAR | 773983002 | 9148474115 | 9038895826 | 8.46 |
+-------------+-------------+------------------+--------------------+----------------+-------+
可以看到,在仅调整了排序与数据聚集方式后,压缩后数据大小从 1.36 GB 减少到了 0.72 GB,压缩比从 15.9% 提升到 8.46%,压缩空间几乎减少了一半。这充分说明了数据的有序性与局部相似性对压缩率的决定性影响。
因此,当用户发现 Doris 的压缩率与其他系统存在差异时,除了压缩算法与参数的区别,更常见的原因在于数据排序和分布模式的不同。压缩算法的效率对数据本身的排序极为敏感,合理设计排序键、分桶列、分桶数与导入方式,往往能带来更大的收益。因此,理解数据的分布特征、控制其在物理层面的布局,是提升 Doris 存储效率的核心手段。
六、结束语
在实际场景中,实现高压缩比的数据存储充满挑战,但列式存储系统 Doris 让这一目标变得可行。经过一系列针对性优化,最终数据的存储空间从最初的 16.08 GB 降至 8.2 GB,整体压缩率提升超过 48%。这一结果并非来自某一个独立的技术点,而是多层次调整叠加的结果:压缩算法的优化、页大小与分桶参数的调整,以及对数据特征的深入理解共同作用,才让压缩效率得到显著提升。
