
亲爱的社区小伙伴们,我们很高兴地向大家宣布,近期我们迎来了 Apache Doris 4.0 版本的正式发布,欢迎大家下载使用体验。
本次发布围绕 “AI 驱动、搜索增强、离线提效” 三大核心方向,新增向量索引、AI 函数等关键特性,完善搜索功能矩阵,优化离线计算稳定性与资源利用率,并通过多项底层改进提升查询性能与数据质量,为用户构建更高效、更灵活的企业级数据分析平台。
在 4.0 版本的研发过程中,有超过 200 名贡献者为 Apache Doris 提交了 9000+ 个优化与修复。 在此向所有参与版本研发、测试和需求反馈的贡献者们表示最衷心的感谢。
一、AI 能力深度集成,开启智能分析新范式
随着大模型与向量检索技术在企业级场景的加速落地与深度渗透,本次 Doris 版本迭代将重点强化 AI 原生支持能力。通过向量索引技术,高效融合企业的结构化与非结构化数据,Doris 将突破传统数据库的功能边界,直接升级为企业核心的 “AI 分析中枢”,为业务端的智能化决策与创新实践提供稳定、高效的底层数据支撑。
01 向量索引(Vector Index)
正式引入向量索引功能,支持对高维向量数据(如文本嵌入、图像特征等)进行高效存储与检索。结合 Doris 原生的 SQL 分析能力,用户可直接在数据库内完成 “结构化数据查询 + 向量相似性搜索” 的一体化分析,无需跨系统整合,大幅降低 AI 应用(如智能推荐、语义搜索、图像检索)的开发与部署成本。
向量索引检索函数介绍
l2_distance_approximate()使用 HNSW 索引按 欧氏距离(L2) 近似计算相似度。数值越小越相似。inner_product_approximate()使用 HNSW 索引按 内积(Inner Product) 近似计算相似度。数值越大越相似。
示例
-- 1) 建表与索引
CREATE TABLE doc_store (
id BIGINT,
title STRING,
tags ARRAY<STRING>,
embedding ARRAY<FLOAT> NOT NULL,
INDEX idx_vec (embedding) USING ANN PROPERTIES (
"index_type" = "hnsw",
"metric_type" = "l2_distance",
"dim" = "768",
"quantizer" = "flat" -- 可选:flat / sq8 / sq4
),
INDEX idx_title (title) USING INVERTED PROPERTIES ("parser" = "english")
)
DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 16
PROPERTIES("replication_num"="1");
-- 2) TopN 最近邻(建议使用 PreparedStatement 传入向量), 用真实向量替换下面的 ... 占位符
SELECT id, l2_distance_approximate(embedding, [...]) AS dist
FROM doc_store
ORDER BY dist ASC
LIMIT 10;
-- 3) 带过滤条件的 ANN(先过滤后TopN,保障召回), 用真实向量替换下面的 ... 占位符
SELECT id, title,
l2_distance_approximate(embedding, [...]) AS dist
FROM doc_store
WHERE title MATCH_ANY 'music' -- 使用倒排索引快速过滤
AND array_contains(tags, 'recommendation') -- 结构化过滤
ORDER BY dist ASC
LIMIT 5;
-- 4) 范围查询,, 用真实向量替换下面的 ... 占位符
SELECT COUNT(*)
FROM doc_store
WHERE l2_distance_approximate(embedding, [...]) <= 0.35;
建索引参数
index_type:必填,当前支持hnsw。metric_type:必填,l2_distance/inner_product。dim:必填,正整数,需与导入向量维度严格一致。max_degree:可选,默认 32;控制 HNSW 图节点出度(M)。ef_construction:可选,默认 40;构建阶段候选队列长度。quant:可选,flat(默认)/sq8/sq4;量化可显著降低内存占用,SQ8 索引体积约为 FLAT 的 1/3,以小幅召回损失换取更高容量/更低成本。
注意事项
- Doris 默认采用“前过滤”:先用可精确定位的索引(如倒排)做谓词过滤,再在剩余集合上进行 ANN TopN,确保结果可解释与召回稳定。
- 如 SQL 中出现 无法由二级索引精确定位 的谓词(例:
ROUND(id) > 100且id无倒排等二级索引),为保证前过滤语义与正确性,系统将 回退精确暴力搜索。 - 向量列需为
ARRAY<FLOAT> NOT NULL,且导入向量维度必须与索引dim一致。 - ANN 目前仅支持 Duplicate Key 表模型。
AI Functions 函数库
让数据分析师能够直接通过简单的 SQL 语句,调用大语言模型进行文本处理。无论是提取特定重要信息、对评论进行情感分类,还是生成简短的文本摘要,现在都能在数据库内部无缝完成:
- AI_CLASSIFY: 在给定的标签中提取与文本内容匹配度最高的单个标签字符串。
- AI_EXTRACT: 根据文本内容,为每个给定标签提取相关信息。
- AI_FILTER: 判断文本内容是否正确,返回值为 bool 类型。
- AI_FIXGRAMMAR: 修复文本中的语法、拼写错误。
- AI_GENERATE: 基于参数内容生成内容。
- AI_MASK: 根据标签,将原文中的敏感信息用
[MASKED]进行替换处理。 - AI_SENTIMENT: 分析文本情感倾向,返回值为
positive、negative、neutral、mixed其中之一。 - AI_SIMILARITY: 判断两文本的语义相似度,返回值为 0 - 10 之间的浮点数,值越大代表语义越相似。
- AI_SUMMARIZE: 对文本进行高度总结概括。
- AI_TRANSLATE: 将文本翻译为指定语言。
- AI_AGG: 对多条文本进行跨行聚合分析。
目前支持的大模型包括:OpenAI、Anthropic、Gemini、DeepSeek、Local、MoonShot、MiniMax、Zhipu、Qwen、Baichuan。例如:模拟一个简历筛选的需求,通过以下 SQL 在语义层进行筛选。
以下表模拟在招聘时的候选人简历和职业要求:
CREATE TABLE candidate_profiles (
candidate_id INT,
name VARCHAR(50),
self_intro VARCHAR(500)
)
DUPLICATE KEY(candidate_id)
DISTRIBUTED BY HASH(candidate_id) BUCKETS 1
PROPERTIES (
"replication_num" = "1"
);
CREATE TABLE job_requirements (
job_id INT,
title VARCHAR(100),
jd_text VARCHAR(500)
)
DUPLICATE KEY(job_id)
DISTRIBUTED BY HASH(job_id) BUCKETS 1
PROPERTIES (
"replication_num" = "1"
);
INSERT INTO candidate_profiles VALUES
(1, 'Alice', 'I am a senior backend engineer with 7 years of experience in Java, Spring Cloud and high-concurrency systems.'),
(2, 'Bob', 'Frontend developer focusing on React, TypeScript and performance optimization for e-commerce sites.'),
(3, 'Cathy', 'Data scientist specializing in NLP, large language models and recommendation systems.');
INSERT INTO job_requirements VALUES
(101, 'Backend Engineer', 'Looking for a senior backend engineer with deep Java expertise and experience designing distributed systems.'),
(102, 'ML Engineer', 'Seeking a data scientist or ML engineer familiar with NLP and large language models.');
可以通过 AI_FILTER 把职业要求和候选人简介做语义匹配,筛选出合适的候选人:
SELECT
c.candidate_id, c.name,
j.job_id, j.title
FROM candidate_profiles AS c
JOIN job_requirements AS j
WHERE AI_FILTER(CONCAT('Does the following candidate self-introduction match the job description?',
'Job: ', j.jd_text, ' Candidate: ', c.self_intro));
得到结果:
+--------------+-------+--------+------------------+
| candidate_id | name | job_id | title |
+--------------+-------+--------+------------------+
| 3 | Cathy | 102 | ML Engineer |
| 1 | Alice | 101 | Backend Engineer |
+--------------+-------+--------+------------------+
二、搜索功能全面升级,赋能全文检索
针对企业级搜索场景的多样化需求,本次版本完善搜索能力矩阵,提供更精准、更灵活的文本检索体验:
01 新增 Search 函数:统一入口的轻量 DSL 全文检索
核心亮点
- 一个函数搞定全文检索:将复杂文本检索算子收拢到
SEARCH()统一入口,语法贴近 Elasticsearch Query String,极大降低 SQL 拼接复杂度与迁移成本。 - 多条件索引下推:复杂检索条件直接下推至倒排索引执行,避免“解析一次、拼接一次”的重复开销,显著提升性能。
DSL 语法支持简介
- 当前版本支持的语法功能:
- 词项查询(Term):
field:value - ANY / ALL 多值匹配:
field:ANY(v1 v2 ...)/field:ALL(v1 v2 ...) - 布尔组合:
AND / OR / NOT与括号分组 - 多字段搜索:在一个
search()中对多个字段做布尔组合
- 词项查询(Term):
- 后续版本会持续迭代以支持以下语法功能:
- 短语
- 前缀
- 通配符
- 正则
- 范围
- 列表
使用方式举例
-- 词项查询
SELECT * FROM docs WHERE search('title:apache');
-- ANY:匹配任意一个值
SELECT * FROM docs WHERE search('tags:ANY(java python golang)');
-- ALL:同时包含多个值
SELECT * FROM docs WHERE search('tags:ALL(machine learning)');
-- 布尔 + 多字段
SELECT * FROM docs
WHERE search('(title:Doris OR content:database) AND NOT category:archived');
-- 结合结构化过滤(结构化条件不参与打分)
SELECT * FROM docs
WHERE search('title:apache') AND publish_date >= '2025-01-01';
02 文本检索打分
为了更好的支持混合检索场景,Doris4.0 版本引入业界主流的 BM25 相关性评分算法,替代传统的 TF-IDF 算法。BM25 可根据文档长度动态调整词频权重,在长文本、多字段检索场景下(如日志分析、文档检索),显著提升结果相关性与检索准确性。
使用方式举例
SELECT *, score() as score
FROM search_demo
WHERE content MATCH_ANY 'search query'
ORDER BY score DESC
LIMIT 10;
功能特性和限制
支持的索引类型
- Tokenized 索引:预定义分词器和自定义分词器
- 非 Tokenized 索引:不分词索引
支持的文本检索算子
- MATCH_ANY
- MATCH_ALL
- MATCH_PHRASE
- MATCH_PHRASE_PREFIX
- SEARCH
注意事项
- 分数范围:BM25 分数没有固定的上下界,分数的相对大小比绝对值更有意义
- 空查询:如果查询词项在集合中不存在,将返回 0 分
- 文档长度影响:较短的文档在包含查询词项时通常获得更高分数
- 查询词项数量:多词项查询的分数是各词项分数的组合(相加)
03 倒排索引分词能力增强
Doris 在 3.1 版本初步提供了分词能力,在 4.0 版本中,我们对分词能力进一步增强,能够满足用户在不同场景下的分词和文本检索需求。
增加三种内置分词器
ICU(International Components for Unicode)分词器
- 适用场景:包含复杂文字系统的国际化文本,特别适合多语言混合文档
- 分词能力举例
SELECT TOKENIZE('مرحبا بالعالم Hello 世界', '"parser"="icu"');
-- 结果: ["مرحبا", "بالعالم", "Hello", "世界"]
SELECT TOKENIZE('มนไมเปนไปตามความตองการ', '"parser"="icu"');
-- 结果: ["มน", "ไมเปน", "ไป", "ตาม", "ความ", "ตองการ"]
IK 分词器
- 适用场景:对分词质量要求较高的中文文本处理
- ik_smart:智能模式,词少且更长,语义集中,适合精确搜索
- ik_max_word:最细粒度模式,更多短词,覆盖更全面,适合召回搜索
- 分词能力举例
SELECT TOKENIZE('中华人民共和国国歌', '"parser"="ik","parser_mode"="ik_smart"');
-- 结果: ["中华人民共和国", "国歌"]
SELECT TOKENIZE('中华人民共和国国歌', '"parser"="ik","parser_mode"="ik_max_word"');
-- 结果: ["中华人民共和国", "中华人民", "中华", "华人", "人民共和国", "人民", "共和国", "共和", "国歌"]
Basic 分词器
- 适用场景:简单场景、对性能要求极高的场景,可以作为日志场景中 unicode 分词器的平替
- 分词能力举例
-- 英文文本分词
SELECT TOKENIZE('Hello World! This is a test.', '"parser"="basic"');
-- 结果: ["hello", "world", "this", "is", "a", "test"]
-- 中文文本分词
SELECT TOKENIZE('你好世界', '"parser"="basic"');
-- 结果: ["你", "好", "世", "界"]
-- 混合语言分词
SELECT TOKENIZE('Hello你好World世界', '"parser"="basic"');
-- 结果: ["hello", "你", "好", "world", "世", "界"]
-- 包含数字和特殊字符
SELECT TOKENIZE('GET /images/hm_bg.jpg HTTP/1.0', '"parser"="basic"');
-- 结果: ["get", "images", "hm", "bg", "jpg", "http", "1", "0"]
-- 处理长数字序列
SELECT TOKENIZE('12345678901234567890', '"parser"="basic"');
-- 结果: ["12345678901234567890"]
新增自定义分词能力
- 管道化组合:通过 char filter、tokenizer 与多个 token filter 的链式配置,构建自定义文本处理流程。
- 组件复用:常用的 tokenizer 和 filter 可在多个 analyzer 中共享,减少重复定义,降低维护成本。
- 用户可以通过 Doris 提供的自定义分词机制,支持灵活组合 char filter、tokenizer 和 token filter,从而为不同字段定制合适的分词流程,满足复杂场景下的个性化文本检索需求。
使用方式举例 1
- 创建类型为 word_delimiter 的 token filter,通过配置 Word Delimiter Filter,将点号(.)和下划线(_)设置为分隔符。
- 创建自定义分词器 complex_identifier_analyzer,引用 token filter complex_word_splitter。
-- 1. 创建自定义 token filter
CREATE INVERTED INDEX TOKEN_FILTER IF NOT EXISTS complex_word_splitter
PROPERTIES
(
"type" = "word_delimiter",
"type_table" = "[. => SUBWORD_DELIM], [_ => SUBWORD_DELIM]");
-- 2. 创建自定义分词器
CREATE INVERTED INDEX ANALYZER IF NOT EXISTS complex_identifier_analyzer
PROPERTIES
(
"tokenizer" = "standard",
"token_filter" = "complex_word_splitter, lowercase"
);
SELECT TOKENIZE(‘apy217.39_202501260000026_526’, ‘”analyzer“=” complex_identifier_analyzer“‘);
-- 结果为[apy]、[217]、[39]、[202501260000026]、[526]
-- MATCH(‘apy217’)或者MATCH(‘202501260000026’)都可以命中
使用方式举例 2
- 创建类型为 char_group 的 tokenizer multi_value_tokenizer,只将符号 | 设置为分隔符。
- 创建自定义分词器 multi_value_analyzer,引用 tokenizer multi_value_tokenizer 。
-- 创建用于多值列分割的 char group tokenizer
CREATE INVERTED INDEX TOKENIZER IF NOT EXISTS multi_value_tokenizer
PROPERTIES
(
"type" = "char_group",
"tokenize_on_chars" = "[|]",
"max_token_length" = "255"
);
-- 创建多值列分词器
CREATE INVERTED INDEX ANALYZER IF NOT EXISTS multi_value_analyzer
PROPERTIES
(
"tokenizer" = "multi_value_tokenizer",
"token_filter" = "lowercase, asciifolding"
);
SELECT tokenize('alice|123456|company', '"analyzer"="multi_value_analyzer"');
-- 结果为[alice]、[123456]、[company]
-- MATCH_ANY(‘alice’)或者MATCH_ANY(‘123456’)都可以命中
三、离线计算能力强化,保障大规模任务稳定运行
当前越来越多的用户将 ETL 数据加工,多表物化视图处理等离线计算任务迁移到 Doris 上运行,针对离线批处理场景的资源消耗大、任务易溢出等痛点,4.0 新增 Spill Disk 功能,当离线计算任务的内存占用超出阈值时,自动将部分中间数据写入磁盘,避免因内存不足导致任务失败,大幅提升大规模离线任务的稳定性与容错能力。目前支持落盘的算子有:
- Hash Join 算子
- 聚合算子
- 排序算子
- CTE 算子
BE 配置项
spill_storage_root_path=/mnt/disk1/spilltest/doris/be/storage;/mnt/disk2/doris-spill;/mnt/disk3/doris-spill
spill_storage_limit=100%
- spill_storage_root_path:查询中间结果落盘文件存储路径,默认和 storage_root_path 一样。
- spill_storage_limit: 落盘文件占用磁盘空间限制。可以配置具体的空间大小(比如 100G, 1T)或者百分比,默认 20%。如果 spill_storage_root_path 配置单独的磁盘,可以设置为 100%。这个参数主要是防止落盘占用太多的磁盘空间,导致无法进行正常的数据存储。
FE Session Variable
set enable_spill=true;
set exec_mem_limit = 10g;
set query_timeout = 3600;
- enable_spill 表示一个 query 是否开启落盘,默认关闭;如果开启,在内存紧张的情况下,会触发查询落盘;
- exec_mem_limit 表示一个 query 使用的最大的内存大小;
- query_timeout 开启落盘,查询时间可能会显著增加,query_timeout 需要进行调整。
一旦落盘发生,用户可以通过多种方式监测落盘的执行状况。
审计日志
FE audit log 中增加了SpillWriteBytesToLocalStorage和SpillReadBytesFromLocalStorage字段,分别表示落盘时写盘和读盘数据总量。
SpillWriteBytesToLocalStorage=503412182|SpillReadBytesFromLocalStorage=503412182
Profile
如果查询过程中触发了落盘,在 Query Profile 中增加了Spill 前缀的一些 Counter 进行标记和落盘相关 counter。以 HashJoin 时 Build HashTable 为例,可以看到下面的 Counter:
PARTITIONED_HASH_JOIN_SINK_OPERATOR (id=4 , nereids_id=179):(ExecTime: 6sec351ms)
- Spilled: true
- CloseTime: 528ns
- ExecTime: 6sec351ms
- InitTime: 5.751us
- InputRows: 6.001215M (6001215)
- MemoryUsage: 0.00
- MemoryUsagePeak: 554.42 MB
- MemoryUsageReserved: 1024.00 KB
- OpenTime: 2.267ms
- PendingFinishDependency: 0ns
- SpillBuildTime: 2sec437ms
- SpillInMemRow: 0
- SpillMaxRowsOfPartition: 68.569K (68569)
- SpillMinRowsOfPartition: 67.455K (67455)
- SpillPartitionShuffleTime: 836.302ms
- SpillPartitionTime: 131.839ms
- SpillTotalTime: 5sec563ms
- SpillWriteBlockBytes: 714.13 MB
- SpillWriteBlockCount: 1.344K (1344)
- SpillWriteFileBytes: 244.40 MB
- SpillWriteFileTime: 350.754ms
- SpillWriteFileTotalCount: 32
- SpillWriteRows: 6.001215M (6001215)
- SpillWriteSerializeBlockTime: 4sec378ms
- SpillWriteTaskCount: 417
- SpillWriteTaskWaitInQueueCount: 0
- SpillWriteTaskWaitInQueueTime: 8.731ms
- SpillWriteTime: 5sec549ms
系统表 backend_active_tasks
增加了SPILL_WRITE_BYTES_TO_LOCAL_STORAGE和SPILL_READ_BYTES_FROM_LOCAL_STORAGE字段,分别表示一个查询目前落盘中间结果写盘数据和读盘数据总量。
mysql [information_schema]>select * from backend_active_tasks;
+-------+------------+-------------------+-----------------------------------+--------------+------------------+-----------+------------+----------------------+---------------------------+--------------------+-------------------+------------+------------------------------------+-------------------------------------+
| BE_ID | FE_HOST | WORKLOAD_GROUP_ID | QUERY_ID | TASK_TIME_MS | TASK_CPU_TIME_MS | SCAN_ROWS | SCAN_BYTES | BE_PEAK_MEMORY_BYTES | CURRENT_USED_MEMORY_BYTES | SHUFFLE_SEND_BYTES | SHUFFLE_SEND_ROWS | QUERY_TYPE | SPILL_WRITE_BYTES_TO_LOCAL_STORAGE | SPILL_READ_BYTES_FROM_LOCAL_STORAGE |
+-------+------------+-------------------+-----------------------------------+--------------+------------------+-----------+------------+----------------------+---------------------------+--------------------+-------------------+------------+------------------------------------+-------------------------------------+
| 10009 | 10.16.10.8 | 1 | 6f08c74afbd44fff-9af951270933842d | 13612 | 11025 | 12002430 | 1960955904 | 733243057 | 70113260 | 0 | 0 | SELECT | 508110119 | 26383070 |
| 10009 | 10.16.10.8 | 1 | 871d643b87bf447b-865eb799403bec96 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | SELECT | 0 | 0 |
+-------+------------+-------------------+-----------------------------------+--------------+------------------+-----------+------------+----------------------+---------------------------+--------------------+-------------------+------------+------------------------------------+-------------------------------------+
2 rows in set (0.00 sec)
测试
为验证落盘功能的稳定性,我们采用 TPC-DS 10TB 标准数据集 开展测试,测试环境配置为 3 台 BE 服务器(每台 16 核 CPU、64GB 内存)。BE 的内存与数据规模的比例为 1:52。测试结果显示,整体运行时长为 28102.386 秒,且成功跑完 TPC-DS 基准测试中的全部 99 条查询,验证了落盘功能的基础稳定性。
具体数据请参考:https://doris.apache.org/docs/dev/admin-manual/workload-management/spill-disk。
四、数据质量全链路保障,筑牢分析结果可信基石
数据正确性是企业制定决策的核心前提与关键基石。为进一步夯实这一基础,4.0 版本对大量函数的运行行为进行了系统性梳理与规范,从数据导入环节到计算分析环节构建全链路校验机制,全面保障数据处理结果的准确性与可靠性,为企业决策提供坚实的数据支撑。
注:数据质量问题的梳理会导致一些行为跟过去产生差异,升级之前请务必仔细阅读文档并提前做好环境测试。
01 Cast
CAST 是 SQL 中逻辑最复杂的函数之一,其核心作用是实现不同数据类型间的转换 —— 这一过程不仅需处理大量细碎的格式规则与边界场景,更因涉及类型语义的精准映射,成为实际使用中极易出错的环节。尤其在数据导入场景中,本质是将外部字符串转换为数据库内部类型的 CAST 操作,因此 CAST 的行为直接决定了导入逻辑的准确性与稳定性。同时,我们可以预见未来的数据库将大量的被 AI 来操作,而 AI 需要对数据库的行为有明确的定义,为此,我们引入了 BNF 范式,希望通过范式定义的方式,为开发者和 AI Agent 提供清晰的操作依据。例如仅 DATE 类型的 CAST 就已通过 BNF 覆盖数十种格式组合场景(https://doris.apache.org/zh-CN/docs/dev/sql-manual/basic-element/sql-data-types/conversion/datetime-conversion),同时在测试阶段我们通过这些规则,派生出百万级的测试 case,保障结果的正确性。
<datetime> ::= <date> (("T" | " ") <time> <whitespace>* <offset>?)?
| <digit>{14} <fraction>? <whitespace>* <offset>?
––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––
<date> ::= <year> ("-" | "/") <month1> ("-" | "/") <day1>
| <year> <month2> <day2>
<year> ::= <digit>{2} | <digit>{4} ; 1970 为界
<month1> ::= <digit>{1,2} ; 01–12
<day1> ::= <digit>{1,2} ; 01–28/29/30/31 视月份而定
<month2> ::= <digit>{2} ; 01–12
<day2> ::= <digit>{2} ; 01–28/29/30/31 视月份而定
––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––
<time> ::= <hour1> (":" <minute1> (":" <second1> <fraction>?)?)?
| <hour2> (<minute2> (<second2> <fraction>?)?)?
<hour1> ::= <digit>{1,2} ; 00–23
<minute1> ::= <digit>{1,2} ; 00–59
<second1> ::= <digit>{1,2} ; 00–59
<hour2> ::= <digit>{2} ; 00–23
<minute2> ::= <digit>{2} ; 00–59
<second2> ::= <digit>{2} ; 00–59
<fraction> ::= "." <digit>*
––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––
<offset> ::= ( "+" | "-" ) <hour-offset> [ ":"? <minute-offset> ]
| <special-tz>
| <long-tz>
<hour-offset> ::= <digit>{1,2} ; 0–14
<minute-offset> ::= <digit>{2} ; 00/30/45
<special-tz> ::= "CST" | "UTC" | "GMT" | "ZULU" | "Z" ; 忽略大小写
<long-tz> ::= ( ^<whitespace> )+ ; e.g. America/New_York
––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––
<digit> ::= "0" | "1" | "2" | "3" | "4" | "5" | "6" | "7" | "8" | "9"
<area> ::= <alpha>+
<location> ::= (<alpha> | "_")+
<alpha> ::= "A" | … | "Z" | "a" | … | "z"
<whitespace> ::= " " | "\t" | "\n" | "\r" | "\v" | "\f"
02 严格模式、非严格模式、TRY_CAST
在 Doris 4.0 中,对CAST操作增加了严格模式、非严格模式(通过 enable_strict_cast 来控制)以及TRY_CAST函数,以更好地处理数据类型转换时的各种情况。具体如下:
- 严格模式:系统会依据预定义的 BNF(语法规则,对输入数据的格式、类型、取值范围进行严格校验:若数据不符合规则(如字段类型应为 “数值型” 却传入字符串、日期格式不符合 “YYYY-MM-DD” 规范),系统会直接终止数据处理流程并抛出明确报错(含具体不符合规则的字段与原因),杜绝不合法数据进入存储或计算环节。这种 “零容忍” 的校验逻辑,与 PostgreSQL 数据库的严格数据校验行为高度一致,能从源头保障数据质量的准确性与一致性,因此在对数据可靠性要求极高的场景中不可或缺 —— 例如金融行业的交易对账、财务领域的账单核算、政务系统的信息登记等场景,一旦出现不合法数据(如交易金额为负数、账单日期格式错误),可能引发资金损失、合规风险或业务流程混乱。
- 非严格模式:系统同样会依据 BNF 规则校验数据,但采用 “容错式” 处理逻辑:若数据不符合规则,不会终止流程或报错,而是自动将不合法数据转换为 NULL 值后继续执行 SQL(例如将字符串 “xyz” 转换为数值型 NULL),确保 SQL 任务能正常完成,优先保障业务流程的连续性与执行效率。这种模式更适用于对 “数据完整性要求较低、但对 SQL 执行成功率要求高” 的场景 —— 例如日志数据处理、用户行为数据清洗、临时数据分析等场景,此类场景中数据量庞大且来源复杂(如 APP 日志可能因设备异常产生格式错乱字段),若因少量不合法数据中断整个 SQL 任务,会大幅降低处理效率,且少量 NULL 值对整体分析结果(如统计活跃用户数、点击量)影响极小。
enable_strict_cast 是在一个语句级别控制 cast 的行为的方式,但是可能会出现,在一个 SQL 中有多个 cast 函数,有一部分函数用户希望用严格模式,另外一部分函数使用非严格模式,所以我们引入了TRY_CAST 函数。
TRY_CAST函数的作用是将一个表达式转换为指定的数据类型,如果转换成功则返回转换后的值,如果转换失败则返回 NULL。其语法为TRY_CAST(source_expr AS target_type),其中source_expr是要转换的表达式,target_type是目标数据类型。例如,TRY_CAST('123' AS INT)会返回 123,而TRY_CAST('abc' AS INT)会返回 NULL。TRY_CAST函数提供了一种更灵活的类型转换方式,在不需要严格保证转换成功的场景下,可以使用该函数来避免因转换失败而导致的错误。
03 浮点类型计算
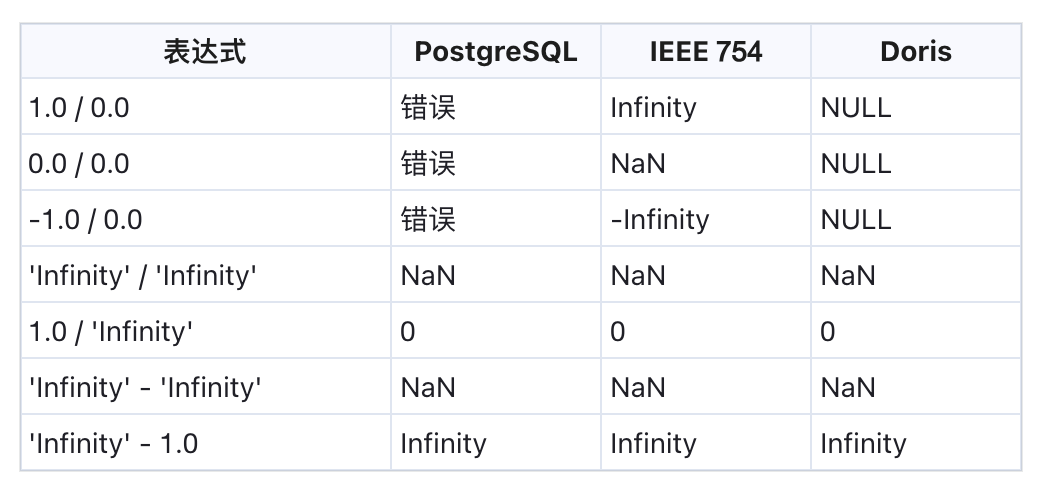
Doris 提供了两种浮点数据类型:FLOAT 和 DOUBLE,但是在有 INF 或者 NaN 的时候由于行为不确定,导致 Order BY 或者 Group BY 时结果可能错误,在这个版本中我们规范并且明确了这个行为。
算术运算
Doris 的浮点数支持常见的加减乘除等算术运算。需要特别注意的是,Doris 在处理浮点数除以 0 的情况时,并不完全遵循 IEEE 754 标准。
Doris 在这方面参考了 PostgreSQL 的实现,当除以 0 时不会生成特殊值,而是返回 SQL NULL:
比较运算
IEEE 标准定义的浮点数比较与通常的整数比较有一些重要区别。例如,负零和正零被视为相等,而任何 NaN 值与任何其他值(包括它自身)比较时都不相等。所有有限浮点数都严格小于 +∞,严格大于 -∞。
为了确保结果的一致性和可预测性,Doris 对 NaN 的处理与 IEEE 标准有所不同。 在 Doris 中,NaN 被视为大于所有其他值(包括 Infinity),NaN 等于 NaN。
mysql> select * from sort_float order by d;
+------+-----------+
| id | d |
+------+-----------+
| 5 | -Infinity |
| 2 | -123 |
| 1 | 123 |
| 4 | Infinity |
| 8 | NaN |
| 9 | NaN |
+------+-----------+
mysql> select
cast('Nan' as double) = cast('Nan' as double) ,
cast('Nan' as double) > cast('Inf' as double) ,
cast('Nan' as double) > cast('123456.789' as double);
+-----------------------------------------------+-----------------------------------------------+------------------------------------------------------+
| cast('Nan' as double) = cast('Nan' as double) | cast('Nan' as double) > cast('Inf' as double) | cast('Nan' as double) > cast('123456.789' as double) |
+-----------------------------------------------+-----------------------------------------------+------------------------------------------------------+
| 1 | 1 | 1 |
+-----------------------------------------------+-----------------------------------------------+------------------------------------------------------+
04 日期函数
本次优化围绕日期函数与时区支持两大维度展开,进一步提升了数据处理的准确性与适用性:
统一日期溢出行为:针对众多日期函数在日期溢出场景(如日期小于 0000-01-01 或大于 9999-12-31)下的行为进行标准化修正,此前不同函数处理溢出时结果不一致的问题被解决,当前所有相关函数在触发日期溢出时均统一返回报错,避免因异常结果导致的数据计算偏差。
扩展日期函数支持范围:将部分日期类型函数的参数签名从 int32 升级为 int64。这一调整突破了原 int32 类型对日期范围的限制,使相关函数能够支持更大跨度的日期计算。
优化时区支持描述:结合 Doris 时区管理的实际逻辑,对时区支持内容进行了更精准的补充与说明,明确了 system_time_zone 与 time_zone 两大核心参数的作用、修改方式,以及时区对日期函数(如 FROM_UNIXTIME、UNIX_TIMESTAMP)、数据导入转换的具体影响,为用户配置与使用时区功能提供更清晰的指引。
为构建真正 Agent-Friendly 的数据库生态,并帮助大模型更精准、深度地理解 Doris,我们对 Doris 的 SQL Reference 进行了系统性完善,具体涵盖数据类型定义、函数定义、数据变换规则等核心内容,为 AI 与数据库的协同交互奠定清晰、可靠的技术基础。 这项工作得到了很多社区小伙伴的支持,他们的智慧与力量为项目注入了关键活力。我们也热切期待更多社区同仁加入进来,与我们携手共建,在技术探索与生态完善的道路上凝聚更多力量,共创更大价值。
五、性能优化
01 TopN 延迟物化
SELECT * FROM tableX ORDER BY columnA ASC/DESC LIMIT N 作为典型的 TopN 查询模式,广泛应用于日志分析、向量检索、数据探查等高频场景。由于此类查询未携带过滤条件,当数据规模庞大时,传统执行方式需对全表数据进行扫描并排序,这会导致大量不必要的数据读取,引发严重的读放大问题。尤其在高并发请求或大数据量存储场景中,该类查询的性能瓶颈更为显著,用户对其优化需求极为迫切。
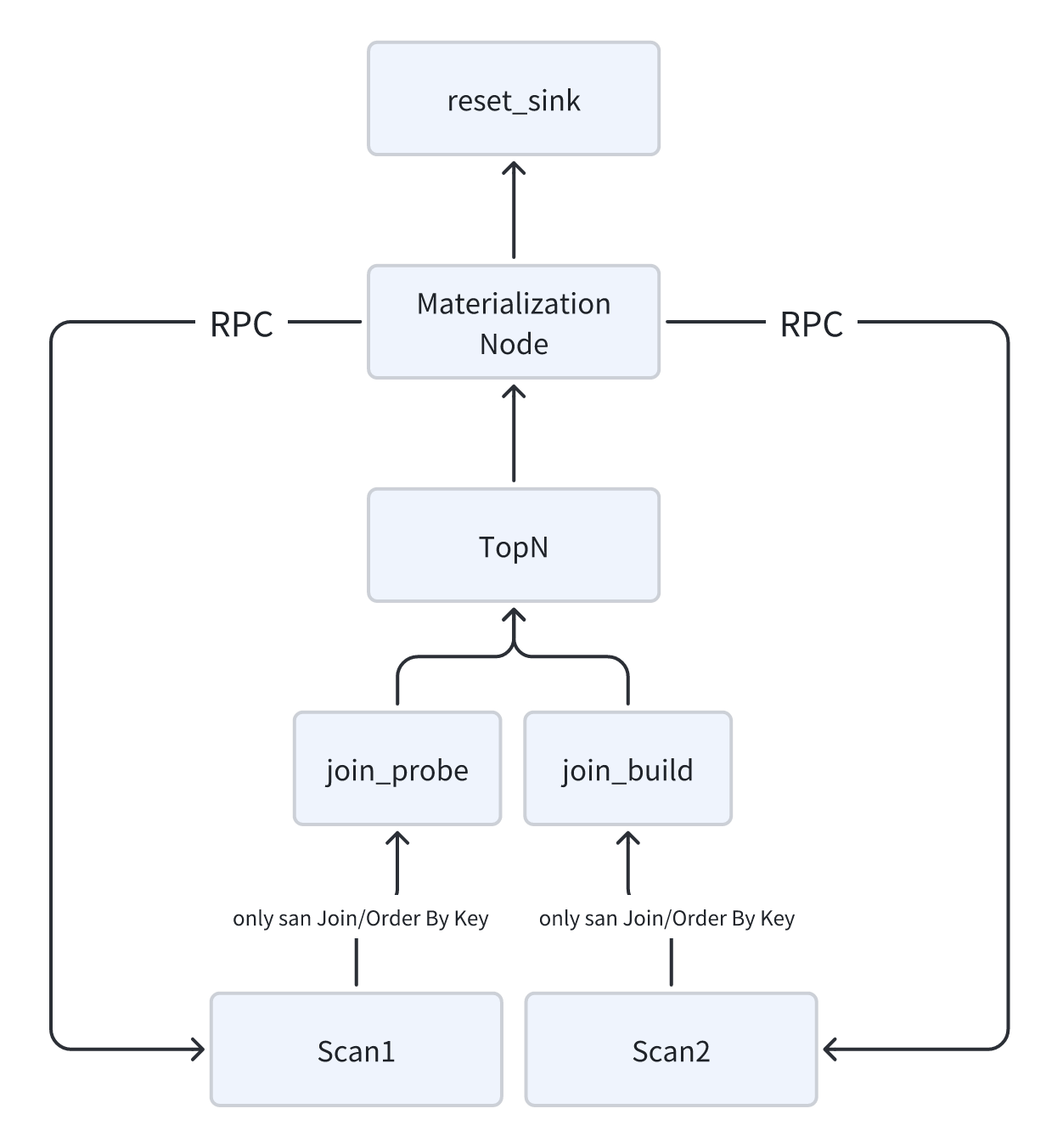
为攻克这一痛点,我们引入了「延迟物化」优化机制,将 TopN 查询拆解为两阶段高效执行:第一阶段仅读取排序字段(columnA)与用于定位数据的主键 / 行标识,通过排序快速筛选出符合 LIMIT N 条件的目标行;第二阶段再基于行标识精准读取目标行的所有列数据。
在 4.0 上,我们对这个能力做出了更进一步的扩展:
- 支持在多表关联的时候也进行 TopN 的延迟物化
- 支持在外表查询时进行 TopN 的延迟物化
在这两个新的场景之中,这个方案能大幅削减非必要列的读取量,从根源上降低读放大效应,在宽表小 LIMIT 场景下 TopN 查询的执行效率有几十倍的提升。
02 SQL Cache 缓存
SQL Cache 是 Doris 在早期版本中提供的功能,受限于很多条件,默认处于关闭状态,在这个版本中,我们系统的梳理了可能影响 SQL Cache 结果的问题,例如 Catalog、DB、Table、Column、Row 查询权限变更,Session variables 发生变更,出现常量折叠规则不能化简的非确定函数等,为了确保 SQL Cache 结果的正确性,该功能现已默认开启。
同时我们对优化器解析 SQL 的性能做了巨大的改进提升,具体而言,SQL 解析性能提升了 100 倍。例如以下 SQL,其中 big_view 是一个包含嵌套视图的大型视图,里面有嵌套的 view,共计 163 个 join 和 17 个 union,我们将 SQL 解析的性能从 400ms 提升到了 2ms。这个优化不仅对 SQL Cache 帮助很大,在 Doris 的高并发查询场景中也有明显提升。
SELECT *,now() as etl_time from big_view;
03 JSON 性能优化
JSON 是半结构化数据常见的一种存储方式,在 4.0 版本我们对 JSONB 也进行了升级。一方面,新增对 Decimal 类型的支持,完善了 JSON 中 Number 类型与 Doris 内部类型的映射体系(此前已覆盖 Int8/Int16/Int32/Int64/Int128/Float/Double 等),进一步满足高精度数值场景的存储与处理需求,避免大数值或高精度数据在 JSON 转换中因类型适配问题导致的精度损失,这有助于 Variant 类型的推导;另一方面,对 JSONB 相关的全量函数(如 json_extract 系列、json_exists_path、json_type 等)进行系统性性能优化,优化后函数执行效率普遍提升 30% 以上,显著加快了 JSON 字段提取、类型判断、路径校验等高频操作的处理速度,为半结构化数据的高效分析提供更强支撑。
相关功能细节可参考 Doris 官方文档:https://doris.apache.org/zh-CN/docs/dev/sql-manual/basic-element/sql-data-types/semi-structured/JSON
六、更易用的资源管控
4.0 版本对 Workload Group 的使用机制进行了优化:统一了 CPU 与内存的软限、硬限定义方式,无需再通过各类配置项单独开启软限或硬限功能,并且同时支持在同一 Workload Group 中并存使用软限与硬限。优化后不仅简化了参数配置流程,还增强了 Workload Group 的使用灵活性,能更精准地满足多样化的资源管控需求。
MIN_CPU_PERCENT 和 MAX_CPU_PERCENT 定义了在出现 CPU 争用时,Workload Group 中所有请求的最低和最高保证 CPU 资源。
- MAX_CPU_PERCENT(最大 CPU 百分比)是该池中 CPU 带宽的最大限制,不论当前 CPU 使用率是多少, 当前 Workload Group 的 CPU 使用率超过都不会超过 MAX_CPU_PERCENT。
- MIN_CPU_PERCENT(最小 CPU 百分比)是为该 Workload 预留的 CPU 带宽,在存在争用时,其他池无法使用这部分带宽, 但是当资源空闲时可以使用超过 MIN_CPU_PERCENT 的带宽。
例如,假设某公司的销售部门和市场部门共享同一个 Doris 实例。销售部门的工作负载是 CPU 密集型的,且包含高优先级查询;市场部门的工作负载同样是 CPU 密集型,但查询优先级较低。通过为每个部门创建单独的 Workload Group,可以为销售 Workload Group 分配 40% 的最小 CPU 百分比,为市场 Workload Group 分配 30% 的最大 CPU 百分比。这种配置能确保销售工作负载获得所需的 CPU 资源,同时市场工作负载不会影响销售工作负载对 CPU 的需求。
MIN_MEMORY_PERCENT 和 MAX_MEMORY_PERCENT 是 Workload Group 可以使用的最小和最大内存量。
- MAX_MEMORY_PERCENT,意味着当请求在该池中运行时,它们占用的内存绝不会超过总内存的这一百分比,一旦超过那么 Query 将会触发落盘或者被 Kill。
- MIN_MEMORY_PERCENT,为某个池设置最小内存值,当资源空闲时,可以使用超过 MIN_MEMORY_PERCENT 的内存,但是当内存不足时,系统将按照 MIN_MEMORY_PERCENT(最小内存百分比)分配内存,可能会选取一些 Query Kill,将 Workload Group 的内存使用量降低到 MIN_MEMORY_PERCENT,以确保其他 Workload Group 有足够的内存可用。
与落盘相结合
在这个版本中,我们将 Workload Group 的内存管理能力与落盘功能进行融合,用户不仅可以通过为每一个 query 设置内存大小来控制落盘,还可以通过 Workload Group 的 Slot 机制来实现动态落盘,在 Workload Group 之上实现了以下策略:
- none,默认值,表示不启用;在这种方式下,query 就尽量的使用内存,但是一旦达到 Workload Group 的上限,就会触发落盘;此时不会根据查询的大小选择。
- fixed,每个 query 可以使用的的内存 =
workload group的mem_limit * query_slot_count/ max_concurrency;这种内存分配策略实际是按照并发,给每个 query 分配固定的内存。 - dynamic,每个 query 可以使用的的内存 =
workload group的mem_limit * query_slot_count/ sum(running query slots),该参数克服了 fixed 模式下存在的 Slot 未使用的情况;实际是把大的查询先落盘。
fixed 或者 dynamic 设置的都是 query 的硬限,一旦超过,就会落盘或者 kill,并且覆盖用户设置的静态内存分配的参数。因此设置 slot_memory_policy 时,一定要注意 Workload Group 的 max_concurrency,否则会出现内存不足的问题。
总结
本次 Apache Doris 新版本通过 AI 与搜索能力的深度融合、离线计算的稳定性提升、性能与易用性的双重优化,进一步拓宽了数据库的应用边界,可更好地支撑企业从传统 BI 分析到 AI 智能检索、从实时查询到大规模离线批处理的全场景数据分析需求。无论是互联网、金融、零售等行业的实时报表、用户行为分析,还是政务、医疗领域的文档检索、大规模数据批处理,新版本 Doris 都将为用户提供更高效、更可靠的数据分析体验。
目前,Apache Doris 新版本已开放下载,详细特性文档与升级指南可访问官方网站(https://doris.apache.org)查看,欢迎社区用户体验与反馈!
致谢
在此,再次向所有参与版本研发、测试和需求反馈的贡献者们表示最衷心的感谢:
Pxl,walter,Gabriel,Mingyu Chen(Rayner),Mryange,morrySnow,zhangdong,lihangyu,zhangstar333,hui lai,Calvin Kirs,deardeng,Dongyang Li,Kaijie Chen,Xinyi Zou,minghong,meiyi,James/Jibing-Li,seawinde,abmdocrt,Yongqiang YANG,Sun Chenyang,wangbo,starocean999,Socrates/苏小刚,Gavin Chou,924060929,HappenLee,yiguolei,daidai,Lei Zhang,zhengyu,zy-kkk,zclllyybb/zclllhhjj,bobhan1,amory,zhiqiang,Jerry Hu,Xin Liao,Siyang Tang,LiBinfeng,Tiewei Fang,Luwei,huanghaibin,Qi Chen,TengJianPing,谢健,Lightman,zhannngchen,koarz,xy720,kkop,HHoflittlefish777,xzj7019,Ashin Gau,lw112,plat1ko,shuke,yagagagaga,shee,zgxme,qiye,zfr95,slothever,Xujian Duan,Yulei-Yang,Jack,Kang,Lijia Liu,linrrarity,Petrichor,Thearas,Uniqueyou,dwdwqfwe,Refrain,catpineapple,smiletan,wudi,caiconghui,camby,zhangyuan,jakevin,Chester,Mingxi,Rijesh Kunhi Parambattu,admiring_xm,zxealous,XLPE,chunping,sparrow,xueweizhang,Adonis Ling,Jiwen liu,KassieZ,Liu Zhenlong,MoanasDaddyXu,Peyz,神技圈子,133tosakarin,FreeOnePlus,Ryan19929,Yixuan Wang,htyoung,smallx,Butao Zhang,Ceng,GentleCold,GoGoWen,HonestManXin,Liqf,Luzhijing,Shuo Wang,Wen Zhenghu,Xr Ling,Zhiguo Wu,Zijie Lu,feifeifeimoon,heguanhui,toms,wudongliang,yangshijie,yongjinhou,yulihua,zhangm365,Amos Bird,AndersZ,Ganlin Zhao,Jeffrey,John Zhang,M1saka,SWEI,XueYuhai,Yao-MR,York Cao,caoliang-web,echo-dundun,huanghg1994,lide,lzy,nivane,nsivarajan,py023,vlt,wlong,zhaorongsheng,AlexYue,Arjun Anandkumar,Arnout Engelen,Benjaminwei,DayuanX,DogDu,DuRipeng,Emmanuel Ferdman,Fangyuan Deng,Guangdong Liu,HB,He xueyu,Hongkun Xu,Hu Yanjun,JinYang,KeeProMise,Muhammet Sakarya,Nya~,On-Work-Song,Shane,Stalary,StarryVerse,TsukiokaKogane,Udit Chaudhary,Xin Li,XnY-wei,Xu Chen,XuJianxu,XuPengfei,Yijia Su,ZhenchaoXu,cat-with-cat,elon-X,gnehil,hongyu guo,ivin,jw-sun,koi,liuzhenwei,msridhar78,noixcn,nsn_huang,peterylh,shouchengShen,spaces-x,wangchuang,wangjing,wangqt,wubiao,xuchenhao,xyf,yanmingfu,yi wang,z404289981,zjj,zzwwhh,İsmail Tosun,赵硕


