Planet 是一家全球领先的金融科技企业,在零售、酒店和旅游行业的支付与税务数字化服务领域深耕近四十年。公司业务广泛,覆盖支付处理、免税退税及行业软件等,致力于通过一体化的解决方案提升全球商户的运营效率与顾客体验。
为了应对日益增长的数据分析需求并优化成本效益,Planet 数据团队近期主导完成了一项重要的数据仓库升级,将系统从 Snowflake 迁移至开源的 Apache Doris。
这次迁移取得了显著的成果:
- 成本大幅降低:数据平台的月度成本从 2.5 万美元降至 5 千美元,成功节省了 80% 的开销。
- 性能显著提升:针对大型数据表的复杂分析场景,查询速度实现了高达 90 倍的提升。
- 实现真正的实时分析:新的架构支持了实时数据摄入与分析,为业务决策提供了更敏锐的洞察力。
通过这次向 Apache Doris 的迁移,Planet 的数据团队不仅成功构建了一个更高效、更经济的数据分析平台,也为未来业务的快速发展奠定了坚实的数据基础。
早期架构以及挑战
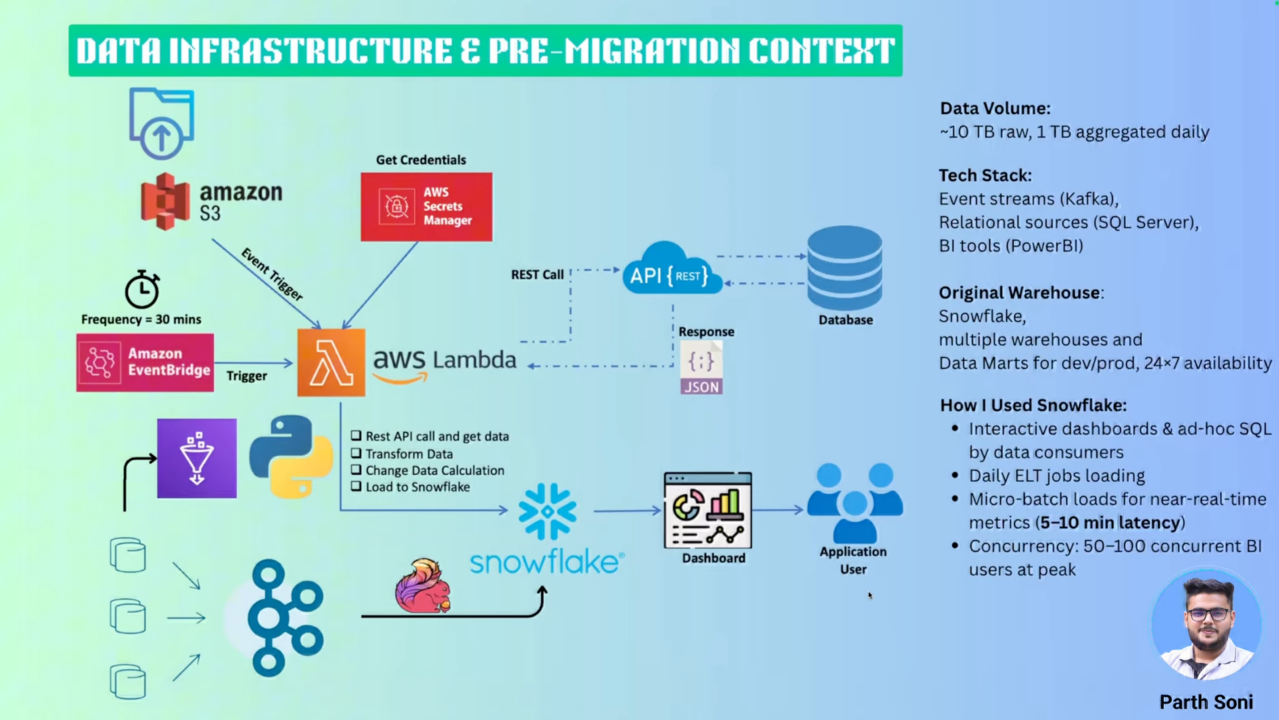
为了更好地理解迁移背景,让我们首先了解 Planet 公司原有的数据架构规模和复杂性。作为一家服务全球零售、酒店和旅游行业的金融科技企业,Planet 面临着海量数据处理的挑战,这也是促使其寻求更优解决方案的根本驱动力。
01 数据规模体量
Planet 的数据平台承载着巨大的处理压力,每天需要处理超过 30 亿条用户生成事件,这相当于每日处理 1 TB 的聚合数据和 10 TB 的原始数据。如此庞大的数据量对系统的实时性、稳定性和成本控制都提出了极高要求。
02 多元化数据摄入流程
Planet 的数据来源多样化,通过三种主要方式汇聚到 Snowflake:
- 实时流式处理:用户行为事件通过 Kafka 消息队列摄入,经过 Flink 进行流式 ETL 处理后写入 Snowflake,确保关键业务数据的实时性
- 事件驱动批处理:存储在 Amazon S3 上的数据文件通过事件触发机制,经由 Lambda 函数进行计算清洗后加载到 Snowflake
- 数据库变更捕获:利用 CDC(Change Data Capture)技术实时捕获事务性数据库的变更,保证数据的一致性和完整性
此外,系统还通过 API 集成各类外部数据源,并定期运行 ETL 作业进行数据的进一步整合与清洗。
03 Snowflake 应用场景与业务价值
在原有架构中,Snowflake 承担着核心分析层的重要角色,为业务用户和利益相关者提供对清洗整理后数据的高效访问能力。平台主要支持两类核心场景:
- 交互式仪表盘:为业务团队提供实时的数据可视化展示,支持关键指标监控和趋势分析
- 即席查询分析:满足数据分析师和业务用户的灵活查询需求,支持复杂的多维度数据探索
然而,随着业务规模的快速增长,Snowflake 在成本控制和查询性能方面的局限性日益凸显,这促使 Planet 数据团队开始寻求更具性价比的替代方案。
04 Snowflake 面临的挑战
在实际使用过程中,他们也面临许多挑战:
- 并发与成本管理: Snowflake 的按查询付费模式虽然灵活,但实际用起来问题不少。一到高峰期,并发用户超过100时,成本就蹭蹭往上涨;数据量持续增长后,性能和开支更是双双飙升。想靠多集群虚拟仓库扛住高并发?结果往往贵得离谱,成本控制变得特别棘手。
- 实时处理的延迟: 尽管系统设计以实现实时分析为目标,但由于微批加载以及 Snowflake 本身“准实时”处理机制的固有延迟,事件从发生到在系统中可见存在约 5 至 10 分钟的延迟,因此难以满足对实时性要求极为严格的业务场景。
- 供应商锁定与组织限制: 组织面临供应商锁定问题,包括合同限制和法律团队的合规担忧,这推动了对开源替代方案或自托管解决方案(例如在 AWS EC2 上)的兴趣。
如下两张图直观地展示了在使用 Snowflake 过程中,随着业务增长所面临的成本激增与查询延迟恶化的双重挑战:
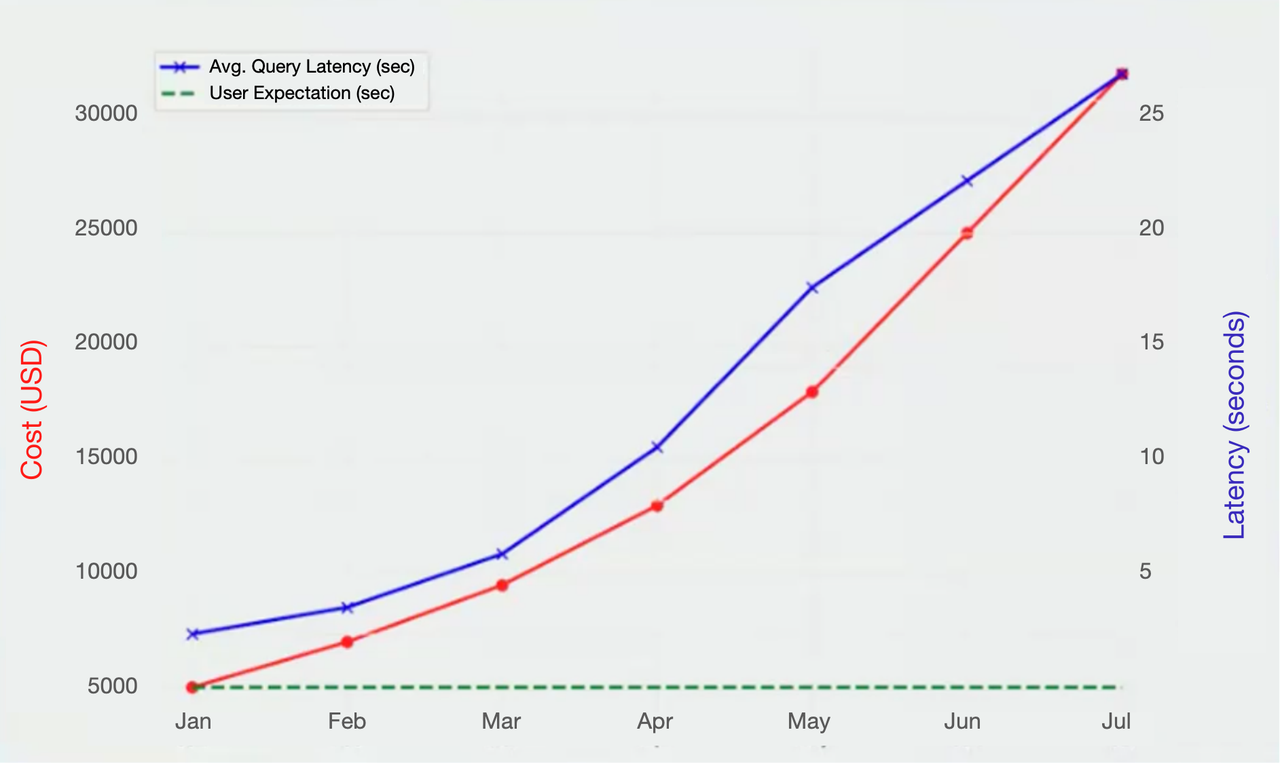
第一张折线图清晰呈现了从一月到七月期间,月度成本(红色曲线)和平均查询延迟(蓝色曲线)的持续攀升趋势:成本从 5,000 美元迅速上涨至 32,000 美元,而查询延迟也从 5 秒飙升至 26 秒,远超用户期望的 3 秒阈值(绿色虚线)。
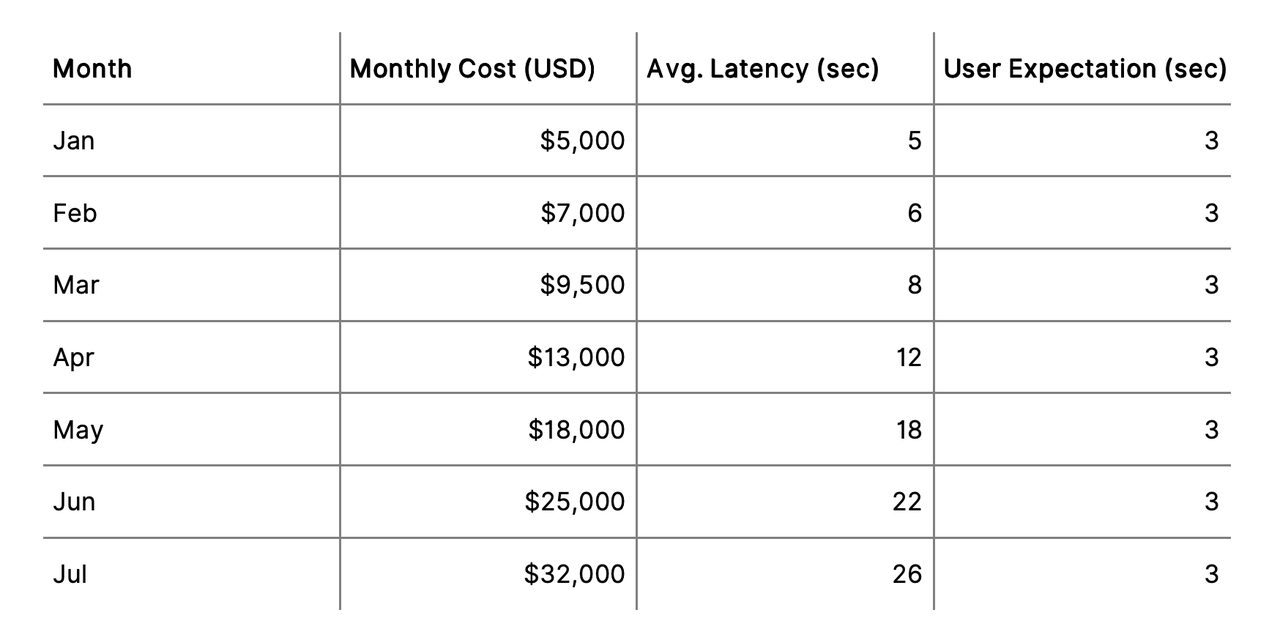
第二张表格则以具体数据支撑了这一趋势,详细列出了每月的成本、延迟及用户期望值,进一步凸显了系统性能与用户体验之间的显著差距。
这些数据共同揭示了当前架构在高并发和实时性需求下的瓶颈,也印证了前文所述的“成本失控”与“实时性不足”问题,为探索更灵活、可控的替代方案提供了有力依据。
为何选择 Apache Doris
基于对 Apache Doris 和 ClickHouse 在性能、灵活性、数据集成和成本效益 等关键指标上的详细对比测试与概念验证 (POC)后,他们最终选定 Apache Doris。具体评估结果如下:
- 在总体成本方面: 尽管开源方案需承担一定运维开销,但 Apache Doris 在功能完备性与资源控制间实现了理想平衡,有效规避了 SaaS 平台常见的成本不可预测性,显著优化了长期 TCO。
- 在查询性能与低延迟方面: Apache Doris 凭借列式存储和向量化执行引擎提供亚秒级查询速度,为实时和即席分析场景提供快速可靠的分析能力,并且在负载下也能保持一致的性能。
- 在运维简便与灵活性方面:Apache Doris 在 AWS EC2 上易于部署和维护,支持自定义存储格式和用户定义函数,允许对架构和治理进行更精细的控制。
- 在实时分析与生态集成方面: Apache Doris 原生无缝集成 Kafka、Flink 和 Spark,构建了端到端的实时数据处理流水线,大幅提升了分析生态的协同效率。
- 在社区支持方面: 活跃的开源社区生态加速了问题响应与解决方案迭代,为技术落地提供了持续动力。
综上所述,以上对比清晰印证,Apache Doris 的综合表现不仅全面契合选型标准,更远超预期需求。基于其在成本可控性、性能稳定性及生态适配性上的突出优势,他们迅速决策将数据架构从 Snowflake 迁移至 Apache Doris,以应对高并发与实时性挑战。
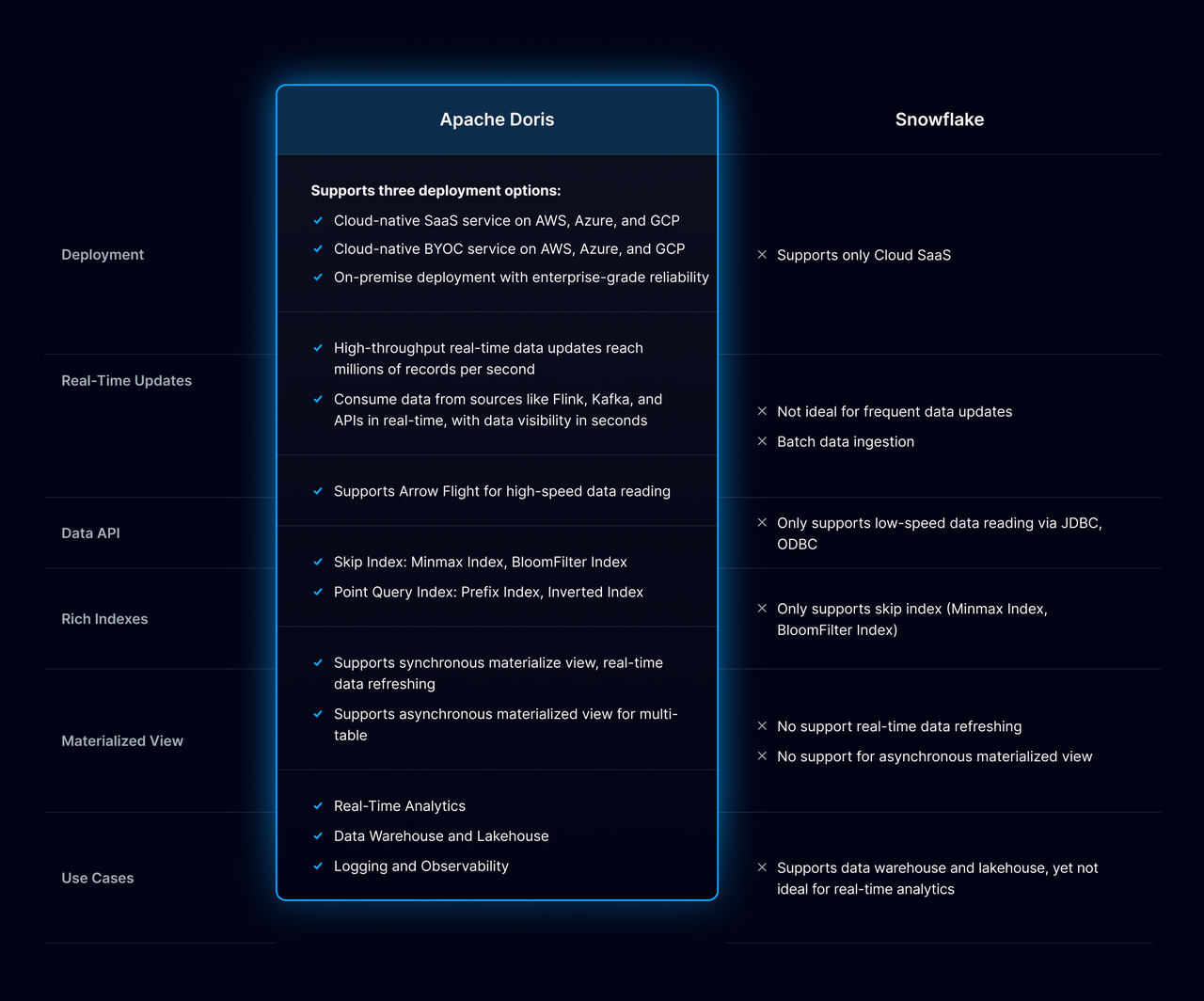
从 Snowflake 到 Apache Doris 架构演进
在迁移过程中,Planet 数据团队制定了一套分阶段、系统化的实施方案,以确保稳定性与性能优化,同时充分利用 Apache Doris 对 MySQL 协议的兼容性。由于 Doris 原生支持 MySQL 语法,团队无需学习新方言,显著降低了 SQL 转换和开发的学习成本。
第一阶段:评估与规划 团队对现有查询模式和分析复杂度进行了全面分析,将 Snowflake 数据类型精准映射到 Doris 等效类型,并重新设计了分区键、分布列和主键以优化数据导入效率。在此基础上,借助 Python 脚本与 Jinja 模板实现模式转换自动化,并通过 Airflow 编排批量数据工作流,确保迁移范围与业务需求完全对齐。
第二阶段:数据导出与加载
数据首先以 Parquet 格式从 Snowflake 导出并暂存于 S3,随后通过基于标准 MySQL 语法的 LOAD DATA INFILE 命令批量导入 Apache Doris。严格的数据质量(QA)与审计流程保障了迁移的完整性与准确性。在 ETL/ELT 管道重构中,团队结合 Doris Kafka Connector(Routine Load)、Flink Doris Connector 与 Spark 微批处理,实现了大规模数据回填及与现有流式管道的无缝集成。
第三阶段:验证与测试 最后,团队在真实业务负载下对 Apache Doris 与 Snowflake 进行了并行验证和性能对比。结果显示,Doris 在高并发场景下保持查询延迟稳定低于 3 秒,具备显著的实时分析与成本优势。同时,语法兼容性也经受住了考验——所有查询和存储过程均通过 MySQL 语法完成重构,避免了额外的学习负担。
通过分阶段迁移,团队成功规避了供应商锁定风险,解决了 Snowflake 的高成本与延迟问题。Apache Doris 凭借 MySQL 协议兼容性、卓越的实时处理能力以及开源灵活性,不仅显著降低了学习曲线和运维开销,更为业务提供了可扩展、高性价比的数据分析基础,标志着架构向高效自主的顺利转型。
新数据架构
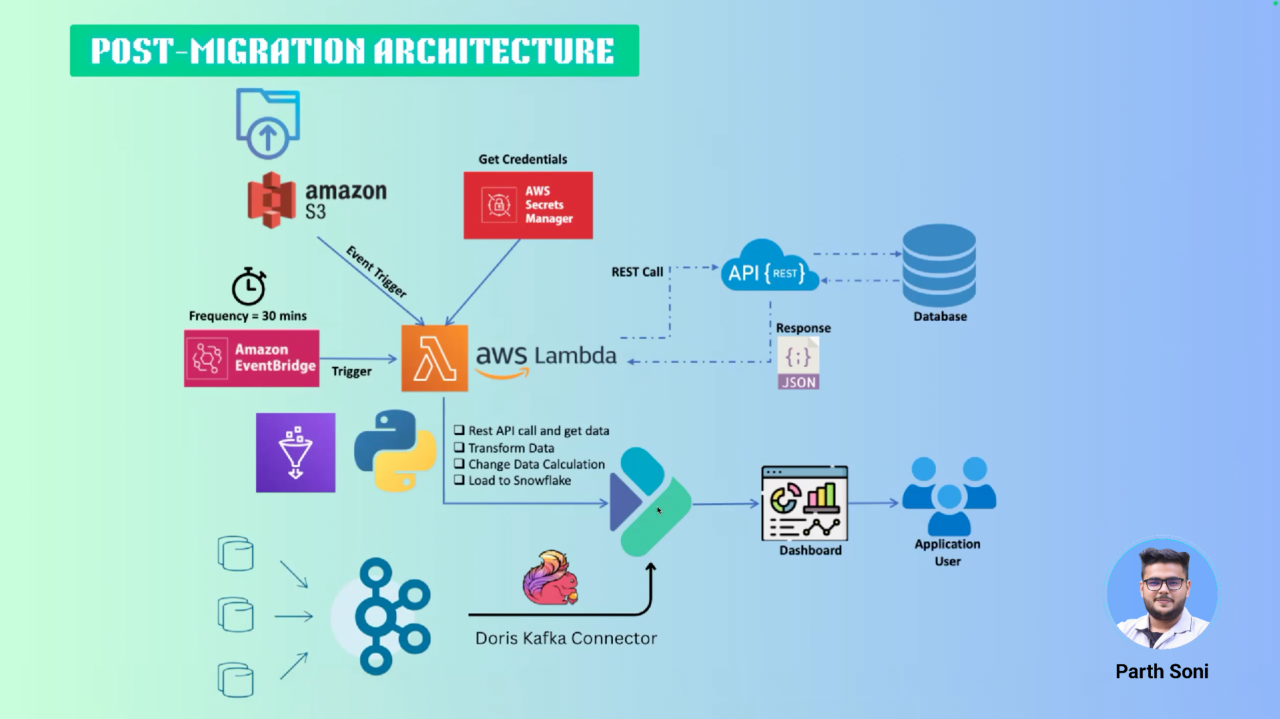
至此,Snowflake 已完全被 Apache Doris 取代,成为主要的分析仓库。数据架构的其余部分保持不变。目前,Doris 已在生产环境中稳定可靠地运行。Planet 数据团队 也正在通过 POC 探索 Doris 在日志分析方面的能力。
Apache Doris 实战总结
基于真实业务场景的深度验证,Apache Doris 在核心分析场景中展现出显著的性能优势:
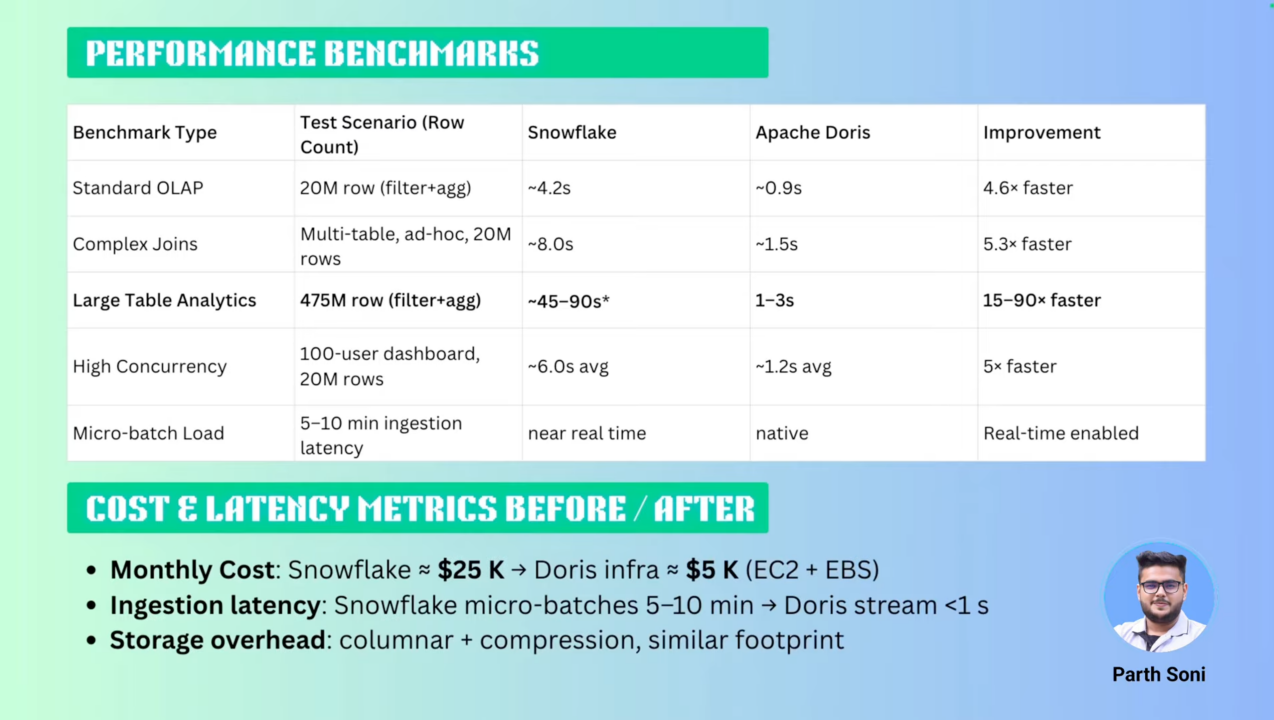
- 标准 OLAP 查询:针对 2000 万行数据的过滤聚合(filter+agg)测试,Apache Doris 仅需 0.9 秒 完成响应,相较 Snowflake 的 4.2 秒 提升 4.6 倍,充分验证其列式存储与向量化执行引擎的高效性。
- 复杂多表 JOIN:在涉及多表关联的即席查询(2000 万行数据量)中,Apache Doris 以 1.5 秒 的平均耗时超越 Snowflake 的 8 秒,性能提升达 5.3 倍,凸显分布式计算架构对复杂查询的优化能力。
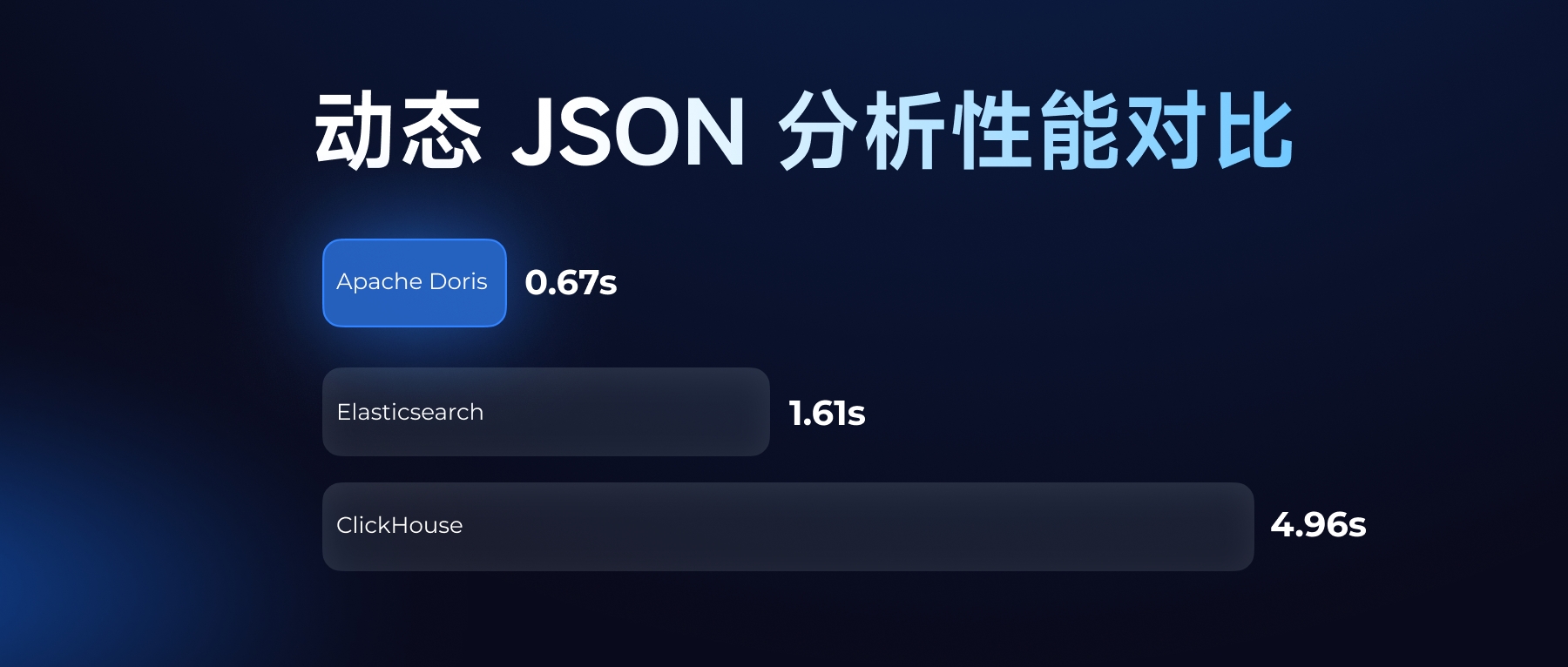
- 超大规模数据处理:面对 4.75 亿行数据的高压力场景,Apache Doris 通过智能分区剪枝与并行计算,在 1-3 秒 内完成结果返回,而 Snowflake 需耗费 45-90 秒,性能差距最高达 90 倍。
- 高并发稳定性:在模拟 100 用户同时查询 2000 万行数据的仪表盘场景下,Apache Doris 保持 1.2 秒 的稳定响应,较 Snowflake 的 6 秒 平均延迟提升 5 倍,印证其分布式事务与资源调度机制的有效性。
- 实时数据摄入:Apache Doris 原生支持流式加载(Stream Load),实现 1-2 秒级 数据可见性,彻底解决 Snowflake 微批处理导致的 5-10 分钟 摄入延迟痛点,满足业务对实时分析的严苛需求。
01 成本与效率双优成果
在实测过程中,团队负责人 Parth 和成员都对 Doris 的表现感到惊讶:“它的查询速度几乎是 Snowflake 的数倍,而总成本却只需要原来的五分之一。这几乎难以置信。”
- 成本压缩 80%:6 月份迁移前,Snowflake 的月度成本约为 $25,000;迁移至部署在 AWS EC2 + EBS 基础设施上的 Apache Doris 后,总月度成本仅约 $5,000,实现了 5 倍的成本节约。
- 存储效率持平:得益于列存压缩技术,Apache Doris 存储空间占用与 Snowflake 相当,消除容量扩展顾虑;
- 全链路加速:从数据摄入到查询响应,Apache Doris 以原生 MySQL 兼容性简化开发适配,同时通过高吞吐、低延迟特性构建了端到端实时分析能力。
02 经验教训与最佳实践
Planet 数据团队也慷慨分享了他从 Snowflake 迁移到 Apache Doris 过程中总结的经验:
- 数据倾斜 (Data skew): 最初的性能瓶颈源自数据分布不均。通过从单列分布切换到多列分布,并平衡分片 (tablet) 大小,查询性能得到显著提升。
- 资源调优: 合理配置 BE 内存限制、JVM 堆大小和 RPC 线程数,对避免内存溢出 (OOM) 至关重要。
尽管这些问题在早期带来挑战,但从性能到成本的收益都证明了努力是值得的。
Planet 数据团队还分享了一些最佳实践:
- 对高基数维度使用 BITMAP 和 Bloom 过滤器。
- 定义合理的分片行数。
- 设置副本数大于等于 3 以实现高可用性。
- 借助物化视图 (Materialized Views) 优化常见聚合。
结束语
通过这次从 Snowflake 到 Apache Doris 的迁移实践,Planet 公司不仅在技术上实现了显著的飞跃——查询性能大幅提升、数据摄入真正做到了实时化,更在成本控制上取得了巨大成功,将月度数据平台开销降低了 80%。
Planet 的实践证明,面对日益增长的数据量和严苛的实时分析需求,企业应当持续评估现有架构的成本效益与可扩展性,并勇于探索和应用新技术。Apache Doris 在此次迁移中充分展现了其作为顶级开源分析引擎在性能、成本和实时性方面的巨大潜力。
对于其他同样希望在成本与性能之间找到最佳平衡点、构建高性能、低成本实时数据分析能力的企业而言,Planet 的这次成功转型无疑是一次极具价值和借鉴意义的实践案例。