
在数据库系统的核心层,查询优化器如同一位精明的策略家,不断分析数据特征并制定最优执行计划。Apache Doris 作为一款高性能的 MPP 分析型数据库,其优化器内置的 Data Trait 分析机制,通过挖掘数据内在的统计特征和语义约束,为查询优化提供了基础设施。让我们一起来探索这个强大的功能!
什么是 Data Trait?
设想一下,如果你能提前知道数据的 “性格特征”,是不是就能更聪明地处理它们?Data Trait 正是这样一种对查询数据和中间结果的 “性格描述”。在 Doris 中,它目前实现了四种关键特征:
- 唯一性(Uniqueness):数据的 “身份证” “在这个世界上,我是独一无二的!”—— 当某列数据这样 “宣称” 时,它就具有唯一性特征。数学上表示为:NDV(不同值的数量) = 表的总行数。
- 均匀性(Uniformity):数据的 “复制粘贴” “我们全都一样!”—— 当一列数据都是相同值时,它就展现出均匀性。具体指非空不同值数量不超过 1。 有趣事实:这种列就像军队的制服,整齐划一,优化器看到它们可以采取特殊处理策略。
- 等值集(Equal Set):数据的 “双胞胎” “我们形影不离,永远相同!”—— 当两列数据在所有行中都完美匹配时(包括 NULL 值),它们就构成等值集。 Doris 的等值集判断是 NULL 敏感的,NULL ≠ NULL 哦!
- 函数依赖(Functional Dependency):数据的 “因果关系” “只要知道 X,就必然知道 Y!”—— 当一组列(X)能唯一决定另一组列(Y)的值时,就存在函数依赖。 X 称为决定因素(Determinant),Y 称为被决定因素(Dependecy) 定义如下: ∀X, Y ⊆ R, X → Y ⇔ ∀t1, t2 ∈ R, t1 [X] = t2 [X] ⇒ t1 [Y] = t2 [Y] 其中,t [X] 表示元组 t 在属性集 X 上的投影。
Data Trait 的表示
唯一性
唯一性使用 UniqueDescription 描述, 想象一个公司的员工管理系统:
- 独立唯一性(slots):就像每个员工的工牌 ID(如 101、102),这些值在整个公司内是独一无二的
- 联合唯一性(slotSets):例如“部门+姓名”的组合,单独看部门可能重复(多个研发部员工),单独看姓名也可能重复(同名员工),但“研发部+张三”的组合在全公司是唯一的
均匀性
均匀性使用 UniformDescription 描述, 包括:
- 已知值的均匀列(有具体 value):
- 比如查询 WHERE department='研发部',这时 department 列在结果集中所有值都是“研发部”
- 类似 SELECT 1 as const_value 中的 const_value 列,所有行都是 1
- 未知值的均匀列(无具体 value):
- 例如 LIMIT 1 后的所有列,虽然知道它们值相同,但不确定具体是什么值
等值集
等值集采用并查集(一种高效的数据结构)来管理,就像家族关系网:
每个数据列最初都是独立的“个体”, 当发现两列值完全相同时(如存在谓词 a = b),它们就被划归到同一个家族,最终所有相等的列会形成一棵棵“家族树”,树中的成员彼此等价。
函数依赖
函数依赖关系使用有向图实现, 就像公司汇报关系:
- 节点:代表一组数据列(如员工 ID、部门 ID 等)
- 边( → ):表示决定关系,比如:
- 员工 ID → 员工姓名(知道 ID 就能确定姓名)
- 部门 ID+项目 ID → 项目经理(联合决定)
这个关系网具有传递性:如果 A→B 且 B→C,那么 A→C
Data Trait 是如何推导出来的?
- 逐层调查:从查询计划的最底层开始,每个处理节点(如扫描、过滤、连接等)都会根据自身特点生成对应的数据特征报告
- 懒加载机制:只有当优化器真正需要这些特征时才会进行计算,避免不必要的分析工作
- 特征合成:高层节点会综合下层节点的特征信息,并结合自身操作特点,生成新的特征描述。 同时,Data Trait 之间也可以相互推导:具有 unique 属性的 slot 能决定所有其他 slot;具有 uniform 属性的 slot 依赖于所有其他的 slot;相等的 slot 互相依赖;相等的 slot 具有相同的 Unique 属性和 Uniform 属性。
Data Trait 的推导过程示例
CREATE TABLE employees (
emp_id INT NOT NULL,
emp_name VARCHAR(100),
email VARCHAR(100),
dept_id INT,
salary DECIMAL(10,2),
hire_date DATE
) UNIQUE KEY(emp_id) DISTRIBUTED BY HASH(emp_id) PROPERTIES('replication_num'='1');
SELECT dept_id, COUNT(*) AS emp_count FROM employees
GROUP BY dept_id;
以上面的 SQL 为例,说明一下 DATA TRAIT 的推导过程,查询计划如下:
[Aggregate]
|
[Scan]
基表扫描层
当扫描 employees 表时,优化器发现:
- 唯一标识:emp_id 是 UNIQUE KEY,具有唯一性特征
- 函数依赖:由于 emp_id 是 UNIQUE KEY,它可以决定表中所有其他列的值(知道员工 ID 就能确定他的部门、姓名等信息)
聚合操作层
进行 GROUP BY 聚合时,数据特征发生了转变:
- 唯一性变化
- 新增的特性:dept_id 是分组键,具有唯一性特征;
- 丢失的特性:原本 emp_id 的唯一性不再有效,因为多行数据被折叠成了分组形式。
- 函数依赖变化
- 新增的关系:现在 dept_id 成为新的“决定因素”,可以确定该部门的员工数量 emp_count(就像知道部门编号就能查到该部门的人数统计)
- 丢失的关系:原先基于 emp_id 的所有函数依赖都失效了,因为员工级别的信息已被聚合操作折叠。
Data Trait 如何优化查询?魔法般的规则应用
下面通过完整示例演示 Data Trait 如何在实际查询优化中发挥作用。先从建表开始,逐步展示优化器如何利用数据特征进行优化。
准备测试环境
建表语句和插入数据 SQL 如下:
-- 员工表(包含唯一ID)
DROP TABLE IF EXISTS employees;
CREATE TABLE employees (
emp_id INT NOT NULL,
emp_name VARCHAR(100),
email VARCHAR(100),
dept_id INT,
salary DECIMAL(10,2),
hire_date DATE
) UNIQUE KEY(emp_id) DISTRIBUTED BY HASH(emp_id) PROPERTIES('replication_num'='1');
-- 部门表(包含唯一ID)
DROP TABLE IF EXISTS departments;
CREATE TABLE departments (
dept_id INT NOT NULL,
dept_name VARCHAR(100),
location VARCHAR(100)
) UNIQUE KEY(dept_id) DISTRIBUTED BY HASH(dept_id) PROPERTIES('replication_num'='1');
-- 订单表(包含唯一ID)
DROP TABLE IF EXISTS orders;
CREATE TABLE orders (
order_id INT NOT NULL,
customer_id INT,
order_date DATE,
amount DECIMAL(10,2)
) UNIQUE KEY(order_id) DISTRIBUTED BY HASH(order_id) PROPERTIES('replication_num'='1');
-- 插入测试数据
INSERT INTO departments SELECT number, concat('name',cast(number as string)), concat('location', cast(number as string)) from numbers("number"="30");
INSERT INTO employees SELECT number, concat('name',cast(number as string)), concat('email',cast(number as string)),number % 30, number, '2025-01-01' from numbers("number" = "100000000");
INSERT INTO orders VALUES
(1001, 5001, '2023-01-10', 999.99),
(1002, 5001, '2023-02-15', 1499.99),
(1003, 5002, '2023-01-20', 799.99),
(1004, 5003, '2023-03-05', 2499.99);
Data Trait 优化实战演示
根据连接键唯一性消除连接(ELIMINATE_JOIN_BY_UK)
场景:在进行 left join 时,右表的连接键是唯一的(允许存在多个 NULL 值),且查询只需要左表数据时...
魔法:直接去掉这个 Join!因为右表要么匹配一行,要么不匹配,不影响左表数据完整性。
示例如下:
-- 原始查询
SELECT COUNT(emp_id) FROM (
SELECT e.emp_id
FROM employees e
LEFT OUTER JOIN departments d ON e.dept_id = d.dept_id) t;
-- 优化后等效查询
SELECT COUNT(emp_id) FROM employees e;
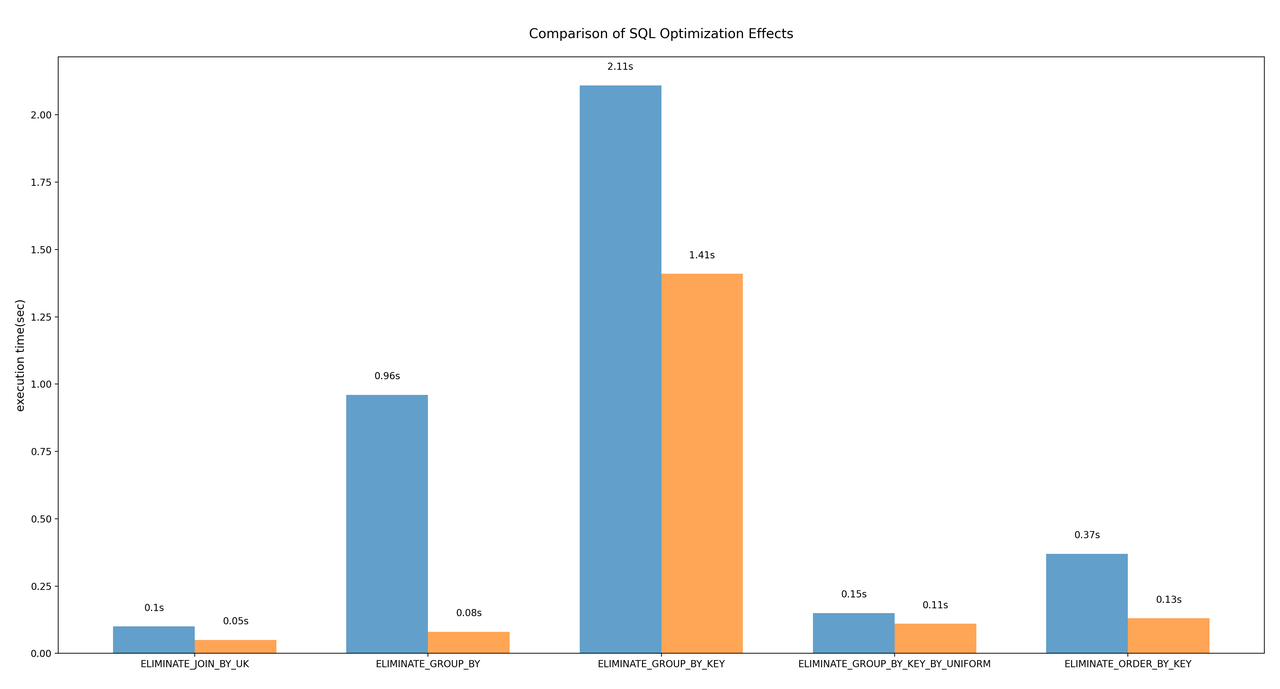
关闭 ELIMINATE_JOIN_BY_UK 优化时(使用 set disable_nereids_rules = 'ELIMINATE_JOIN_BY_UK'关闭优化),执行时间为 0.1sec, 在开启 ELIMINATE_JOIN_BY_UK 优化时,执行时间为 0.05sec,性能提升了 100%。
根据唯一性消除冗余聚合键(ELIMINATE_GROUP_BY)
场景: 当 Group By Key 列中存在具有 unique 并且非空属性的列时...
魔法:可以直接把 Group By 删除
--原始查询
SELECT COUNT(c2) FROM
(SELECT emp_id c1, sum(salary) c2 from employees GROUP BY emp_id, emp_name) t;
-- 优化后等效查询
SELECT COUNT(c2) FROM
(SELECT emp_id c1, salary c2 from employees) t;
在关闭 ELIMINATE_GROUP_BY 优化时,执行时间为 0.96sec, 在开启 ELIMINATE_GROUP_BY 优化时, SQL 的执行时间是 0.08sec, 性能提升了 1100%。
消除存在依赖关系的聚合键(ELIMINATE_GROUP_BY_KEY)
场景:Group By 多列,并且这些列中具有函数依赖关系
魔法:使用函数依赖中被决定的 slot 可以在 Group By Key 列中被消除。
示例如下:
--案例1: 根据函数提供的函数依赖消除
-- email -> SUBSTR(email, 1, INSTR(email, '@')-1)
-- 原始查询
SELECT count(email) FROM (SELECT email
FROM employees
GROUP BY email, SUBSTR(email, INSTR(email, 'l')+1)) t;
-- 优化后等效查询
SELECT count(email) FROM (SELECT email
FROM employees
GROUP BY email) t;
--案例2: 根据等值集提供的函数依赖消除
-- 原始查询
SELECT COUNT(*)
FROM employees e
INNER JOIN departments d ON e.dept_id = d.dept_id
GROUP BY e.dept_id, d.dept_id;
-- 优化后等效查询
SELECT COUNT(*)
FROM employees e
INNER JOIN departments d ON e.dept_id = d.dept_id
GROUP BY e.dept_id;
以案例 1 为例,在关闭 ELIMINATE_GROUP_BY_KEY 优化时,执行时间为 2.11s, 在开启 ELIMINATE_GROUP_BY_KEY 优化时,SQL 的执行时间为 1.41sec, 性能提升了 50%。
消除均一列的聚合键(ELIMINATE_GROUP_BY_KEY_BY_UNIFORM)
场景:Group By 的列所有值都相同...
魔法:直接去掉 Group By,因为所有行都属于同一组。
示例如下:
-- 原始查询
SELECT hire_date, max(salary) FROM employees WHERE hire_date='2025-01-01' GROUP BY dept_id,hire_date;
-- 优化后等效查询
SELECT '2025-01-01', max(salary) FROM employees WHERE hire_date='2025-01-01' GROUP BY dept_id;
在关闭 ELIMINATE_GROUP_BY_KEY_BY_UNIFORM 优化时,执行时间为 0.15sec,在开启 ELIMINATE_GROUP_BY_KEY_BY_UNIFORM 优化时,SQL 的执行时间是 0.11sec,性能提升了 36%。
消除无意义排序(ELIMINATE_ORDER_BY_KEY)
场景:按唯一键排序, 或者排序键中包含具有函数依赖时。
魔法:去掉这个 Order By,因为数据已经自然有序, 去掉函数依赖中被决定的 Key。
示例如下:
-- 案例1:唯一性推导的函数依赖简化
SELECT sum(c1) FROM
(SELECT emp_id c1, emp_name c2
FROM employees
ORDER BY emp_id,emp_name,email,dept_id,salary,hire_date
LIMIT 1000000) t;
-- 优化后等效查询
SELECT sum(c1) FROM
(SELECT emp_id c1, emp_name c2
FROM employees
ORDER BY emp_id
LIMIT 1000000) t;
-- 案例2:表达式推导的函数依赖简化
SELECT hire_date, EXTRACT(YEAR FROM hire_date), EXTRACT(MONTH FROM hire_date)
FROM employees
ORDER BY hire_date, EXTRACT(YEAR FROM hire_date), EXTRACT(MONTH FROM hire_date);
-- 优化后等效查询
SELECT hire_date, EXTRACT(YEAR FROM hire_date), EXTRACT(MONTH FROM hire_date)
FROM employees
ORDER BY hire_date;
-- 案例3: 多列表达式依赖简化
SELECT emp_name
FROM employees
ORDER BY emp_name, email, CONCAT(emp_name, ' ', email);
-- 优化后等效查询
SELECT emp_name
FROM employees
ORDER BY emp_name, email;
-- 案例4: 根据均匀性消除
SELECT emp_name
FROM employees
WHERE emp_id = 101
ORDER BY emp_id;
--优化后等效查询
SELECT emp_name
FROM employees
WHERE emp_id = 101;
以案例 1 为例,在关闭 ELIMINATE_ORDER_BY_KEY 优化时,SQL 的执行时间是 0.37sec, 在开启 ELIMINATE_ORDER_BY_KEY 优化时,SQL 的执行时间是 0.13sec,性能提升了 185%。
优化效果对比
五个优化规则的效果对比如下图所示,蓝色代表关闭优化规则的 SQL 执行时间,橙色代表开启优化规则的 SQL 执行时间。
最佳实践
建议做法:为所有唯一键列添加明确的 UNIQUE 约束
无论列是否为主键,只要具有唯一性特征(包括业务唯一键、组合唯一键和外键关联列),都应通过 UNIQUE 约束明确定义。
CREATE TABLE orders (
order_id INT,
order_code VARCHAR(20));
ALTER TABLE orders ADD CONSTRAINT orders_uk UNIQUE (order_id);
优化收益:帮助优化器识别唯一性特征,实现 Join 消除、Group By 简化等优化。
建议做法:合理使用 NOT NULL 约束
对业务上不允许为空的列添加 NOT NULL,因为上面提到的一些优化规则,是要求 slot 唯一且非空或者均匀且非空才能应用, 添加 NOT NULL 可以避免 NULL 值对优化的干扰。
CREATE TABLE products (
product_id INT NOT NULL,
product_name VARCHAR(100) NOT NULL);
避免做法:过度使用 SELECT *
-- 应避免的写法
explain logical plan
SELECT *
FROM employees e
LEFT OUTER JOIN departments d ON e.dept_id = d.dept_id;
-- 推荐写法
explain logical plan
SELECT e.*
FROM employees e
LEFT OUTER JOIN departments d ON e.dept_id = d.dept_id;
问题原因:例如,优化规则 ELIMINATE_JOIN_BY_UK 能够应用的条件之一是投影列中只出现 LEFT OUTER JOIN 左表的列, 所以当您只需要左表数据时,SELECT * 的使用会阻碍优化器应用优化规则。
避免做法:避免冗余的分组键和排序键
-- 冗余分组列(即使用者知道product_id决定product_name,但是数据库系统未识别此依赖,此时product_name为冗余,可以删除)
SELECT product_id, product_name
FROM products
GROUP BY product_id, product_name;
通过主动避免冗余的分组键和排序键,即使某些函数依赖无法被系统自动识别,您仍然可以提高查询执行效率, 减少资源消耗, 保持代码简洁性。
总结和展望
Data Trait 通过四大核心特征(唯一性、均匀性、等值集、函数依赖)为查询优化器提供了深度的数据认知能力:
- 数据特征识别:精确捕捉数据的本质属性,如主键唯一性、常量列均匀性等
- 查询语义理解:解析 SQL 操作背后的真实数据关系,识别冗余操作
- 优化决策支持:为查询重写、计划选择等优化提供理论依据
Data Trait 的设计采用了高度模块化的架构,为未来的功能扩展预留了充分空间。特别是在 Uniform 特征的扩展方面,计划引入更精细化的取值分布描述能力。当前 Uniform 主要记录列值完全均匀(单一值)的情况,下一步将扩展为支持记录有限离散值的场景。例如当查询包含 WHERE status IN ('active','pending')这样的 IN 谓词过滤时,优化器可以精确获知 status 列在此查询上下文中只有 2 个可能的取值。这种扩展后的 Uniform 特征将为优化器带来更丰富的决策依据。


