
企业在数据驱动的道路上,始终面临一对核心矛盾:既需要低成本、可扩展的存储方案来承载海量结构化、半结构化乃至非结构化数据(这正是数据湖的强项),又渴望实时、低延迟的分析能力来支撑业务决策(这是分析型数据库的核心优势)。
然而现实是,单独的解决方案往往难以两全:以 Apache Paimon 为代表的数据湖技术,虽凭借开放格式、弹性扩展和低成本存储成为企业数据中台的基石,但在低延迟响应上存在天然短板;而以 Apache Doris 为代表的分析型数据库,虽能提供高效的查询性能,却缺乏数据湖的存储灵活性与开放性。
本文的核心观点是:“架起数据库与数据湖的桥梁” 并非趋势,而是破局的关键。小米通过将 Apache Doris(数据库)与 Apache Paimon(数据湖)深度融合,不仅解决了数据湖分析的性能瓶颈,更实现了 “1+1>2” 的协同效应。
数据库与数据湖的互补之力
“桥接数据库与数据湖”的核心价值,在于构建“存储灵活、计算高效、格式协同”的一体化架构——不仅是存储与计算能力的分工互补,更包含数据格式层面的深度协同,让两者的技术特性形成叠加效应。
1. 数据湖仓的分工定位
从基础能力来看,两者的分工已形成天然互补:
- Apache Paimon 作为数据湖,核心优势体现在存储层:其开放格式(兼容 Spark、Flink、Trino 等多引擎)、基于对象存储(S3、HDFS)的 PB 级弹性扩展能力,以及对事务、Schema 演进的原生支持,使其成为海量异构数据的“统一存储基座”,兼顾低成本与兼容性。
- Apache Doris 作为分析型数据库,核心优势体现在计算层:分布式并行引擎、向量化执行框架、以及针对复杂聚合场景的算子优化,使其能提供毫秒至秒级的低延迟查询响应,成为数据价值挖掘的“高效计算引擎”。
2. 数据格式的特性互补
更深层的协同点,在于数据格式的特性互补:
- 数据湖格式(如 Paimon)为适配多引擎读写与大规模存储场景,在设计上以通用性为优先,虽能满足跨引擎兼容需求,但在高频查询、复杂计算场景下,其通用格式的解析效率、IO 开销难以进一步优化;
- 而数据库(如 Doris)则拥有专为查询性能设计的 高效内部存储格式——例如基于列存的分层存储结构、自适应编码压缩算法(如字典编码、RLE 压缩)、原生索引(如前缀索引、 bloom filter)等,这些格式通过深度耦合计算引擎的执行逻辑,可最大限度减少数据扫描量与 IO 消耗,实现亚秒级查询响应。
3. 桥接架构的双向赋能
桥接架构下,数据湖仓可实现双向赋能:
- 海量冷数据、全量历史数据以 Paimon 格式存储于数据湖,保持低成本与多引擎兼容性;
- 高频访问的热数据、需复杂聚合的核心指标,则通过 Doris 的物化视图、本地缓存等机制,转换为 Doris 高效内部格式存储,借助其原生存储与计算的协同优化,实现极致查询性能。
这种模式既避免了单一数据湖格式在查询性能上的瓶颈,又解决了单一数据库格式在存储成本与扩展性上的局限。唯有通过“桥接”,才能让数据湖的通用存储优势与数据库的高效格式特性形成合力,实现“存储成本可控、查询性能最优”的理想状态。
Apache Doris & Paimon 在小米的实践与挑战
Apache Paimon 是一款优秀的开放数据湖格式,其流批一体的设计很好的满足了湖上数据的实时处理需求。
Doris 在 2.1 版本开始支持 Paimon Catalog,可以直接访问 Paimon 数据并加速 Paimon 数据分析。在 Paimon TPC-DS 1TB 测试集上,Doris 的总体查询性能是 Trino 的 5 倍。
从 2.1 版本到 3.0、3.1 版本,Doris 在持续针对 Paimon 格式进行功能更新和性能增强,包括但不限于以下功能:
- 通过元信息对 Paimon 数据进行分区、分桶裁剪和谓词下推,优化查询效率。
- 支持 Paimon Deletion Vector 读取,利用向量化 C++ 引擎加速 Paimon 更新数据的读取。
- 支持 Paimon 数据的本地文件缓存,充分利用本地高速磁盘提升热点数据的查询效率。
- 支持 Paimon 时间旅行、增量数据读取、Branch/Tag 数据读取,方便用户进行 Paimon 数据的多版本管理。
- 支持基于 Paimon 的物化视图,包括分区级别的增量物化视图构建,以及本文后续将要介绍的基于快照级别的增量构建,同时支持强一致的物化视图透明改写能力,将湖和仓的能力深度结合。
- 支持 Paimon Rest Catalog(DLF),方便云上用户接入 Paimon 生态,实现统一元数据管理。
在本文中,我们将重点介绍小米如何基于 Doris + Paimon 构建统一湖仓平台,以及在项目开发过程中的功能贡献和优化思路。
01 化繁为简:基于 Doris + Paimon 的统一湖仓平台建设
作为一家业务覆盖汽车、IoT、手机、互联网服务等多个领域的大型企业,小米集团对 OLAP 系统和湖仓平台提出了如下关键需求:
- 多维度分析:支持高并发、低延迟的多维聚合分析(如用户行为、设备状态、运营监控等)。
- 多源接入:需要打通 Flink、Spark、Flink CDC 等流批框架的输入,覆盖离线、实时全链路数据处理场景。
- 统一数据访问:支持跨引擎、多格式的数据消费需求(如 Doris、Paimon、Iceberg 等)。
- 降低平台复杂度:减少技术栈分裂,统一数据建模与管控,提升数据平台运维效率。
当前架构的挑战与瓶颈
尽管已有较成熟的数据平台体系,但小米的 OLAP 湖仓架构长期存在如下“繁杂、割裂”的结构问题:
- 存储多源异构,数据重复堆叠
- 为满足不同业务对数据的不同时效性需求,需要按照分钟、小时、天级别的时效性要求,将数据存储在不同的数据系统中(Iceberg、Paimon、Druid、Doris),导致数据冗余、不一致等问题
- 湖仓割裂,缺乏统一接口
- 需要同时使用不同的引擎进行数据查询,(如 Presto、Druid、Doris、Spark 等)。各系统有独立的数据建模、运维和权限控制逻辑,平台治理成本高,入口不统一,使用方式不统一。
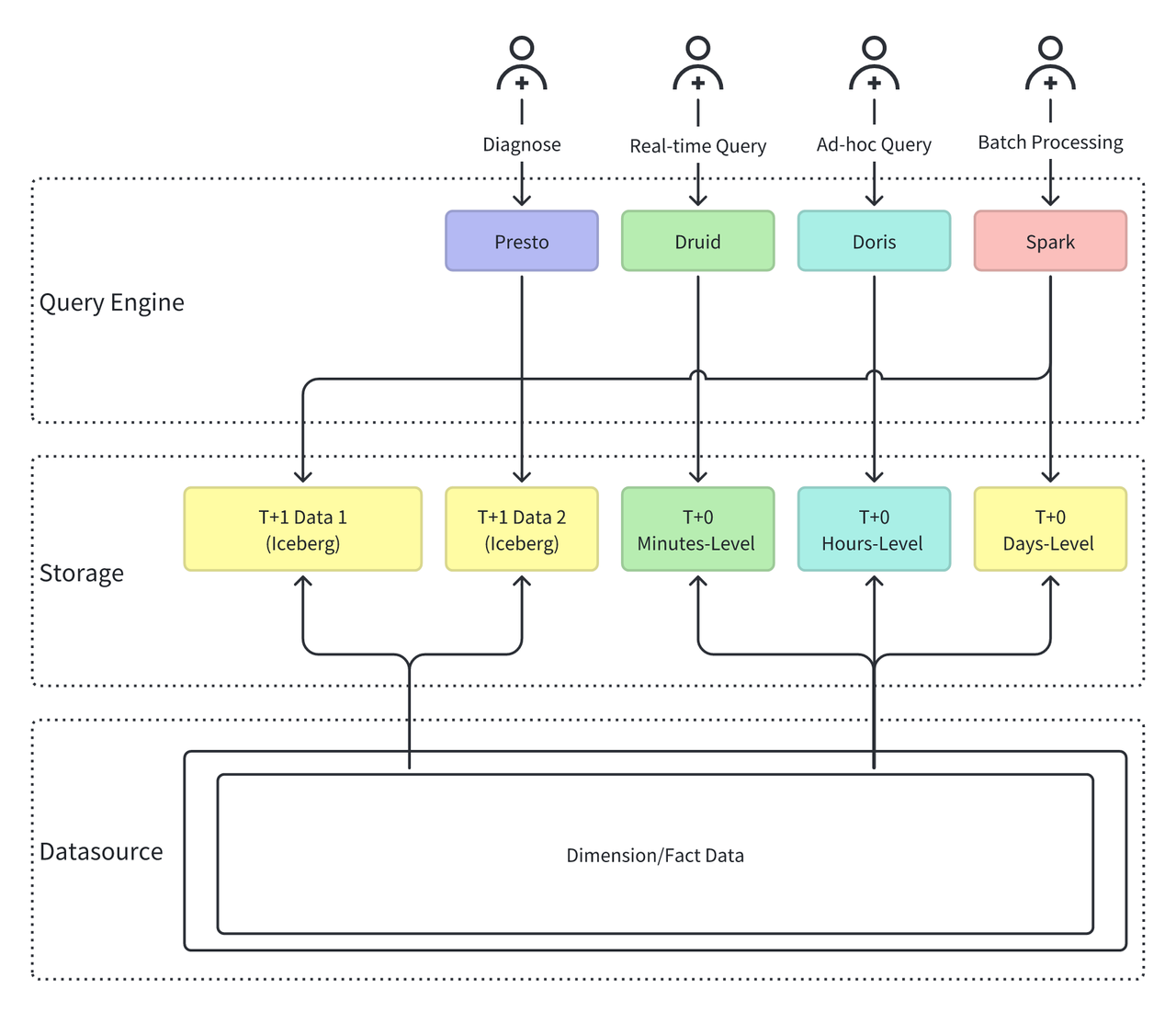
这些问题不仅增加了平台负担,也制约了 OLAP 架构在大规模实时应用场景下的稳定性和扩展性。
统一引擎 + 统一存储
为应对上述挑战,小米构建了基于 Apache Doris + Apache Paimon 的统一湖仓一体化架构,作为未来 OLAP 平台的核心形态。
- 统一计算引擎:Apache Doris + Spark
- 采用 Doris + Spark 的计算引擎组合。Doris 负责实时数据和交互式数据分析,以及高并发查询场景。Spark 负责离线批处理场景。
- 统一数据湖存储:Apache Paimon
- 以 Apache Paimon 作为统一数据存储格式。Paimon 的设计非常适合流、批数据一体化存储。实现批流一体、湖仓一体的数据管理。
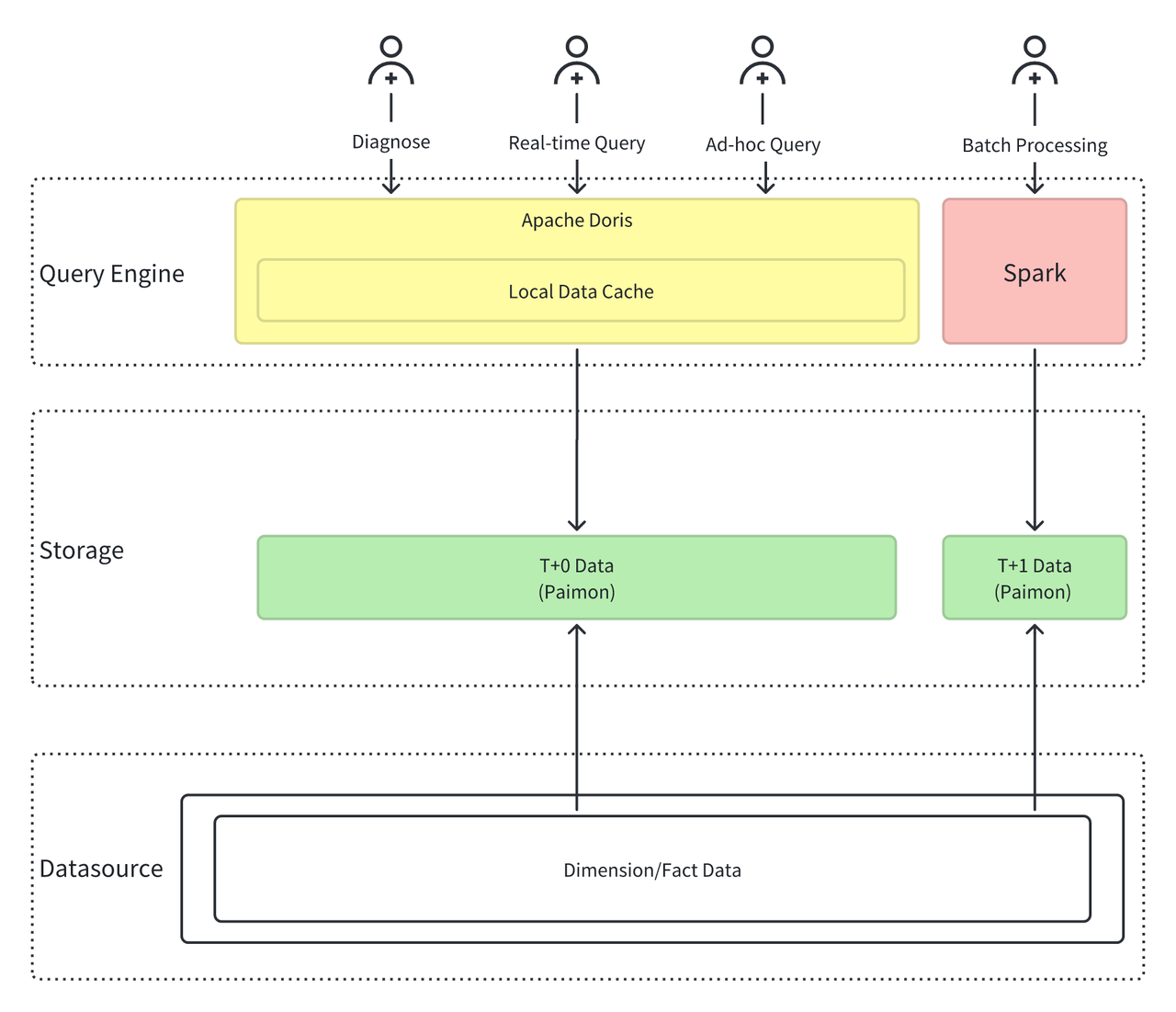
通过这一架构转型,极大地简化了系统架构:
- 计算引擎:Presto、Druid、Doris、Spark -> Doris、Spark
- 存储格式:Iceberg、Paimon、Doris、Druid -> Doris、Paimon
02 深度融合:基于 Doris + Paimon 查询加速实践
小米在引入 Apache Paimon 构建湖仓平台后,虽解决了海量数据的存储问题,却在实际业务中遭遇了三大关键瓶颈,直接影响了数据价值的释放:
- 聚合性能不足:Doris 在读取 Paimon 的 Merge-on-Read 表时,受限于 Paimon SDK(Java)单线程处理多文件的排序与合并,在高并发场景下完全无法满足业务对 “秒级响应” 的需求。
- 物化视图更新代价高昂:分区级增量更新机制粒度在某些场景下可以满足用户的增量更新需求。但对于非分区表,或者单分区数据量较大的表,依然有较高的更新成本。
- HDFS 读取延迟不稳定:HDFS 多副本读取时,默认 60 秒的超时阈值和网络抖动,导致查询延迟波动极大,业务方难以依赖数据结果快速做出决策。
这些问题并非单纯的技术瑕疵 —— 它们直接拖慢了业务决策速度,同时因资源浪费和低效运行增加了企业成本。
针对上述瓶颈,小米通过深度整合 Apache Doris 与 Apache Paimon 的特性,打造了三大 “桥接” 方案,实现了从 “问题” 到 “解决方案” 的精准突破。
方案一:用 Doris 计算引擎加速 Paimon 聚合能力
Doris 本身拥有强大的数据聚合计算能力,同时支持 Aggregate Key 聚合表模型,该模型在应用场景上和 Paimon 聚合表非常类似,因此可以作为 Paimon 聚合表很好的补充。
针对原先 Doris 读取 Paimon 聚合表性能不足的问题,小米采用了将文件合并与排序逻辑 “上移” 至 Doris 的查询引擎的方案,利用 Doris 的分布式并行计算与向量化执行能力,替代 Paimon SDK 的单线程处理模式。具体而言:
- 放弃 JNI 调用 Paimon Java SDK 的方式,改用 Doris 原生 Parquet Reader 直接读取 Paimon 数据文件;
- 借助 Doris 的 Hash 算子实现分布式聚合(无需排序步骤),充分发挥 C++ 引擎的性能优势。
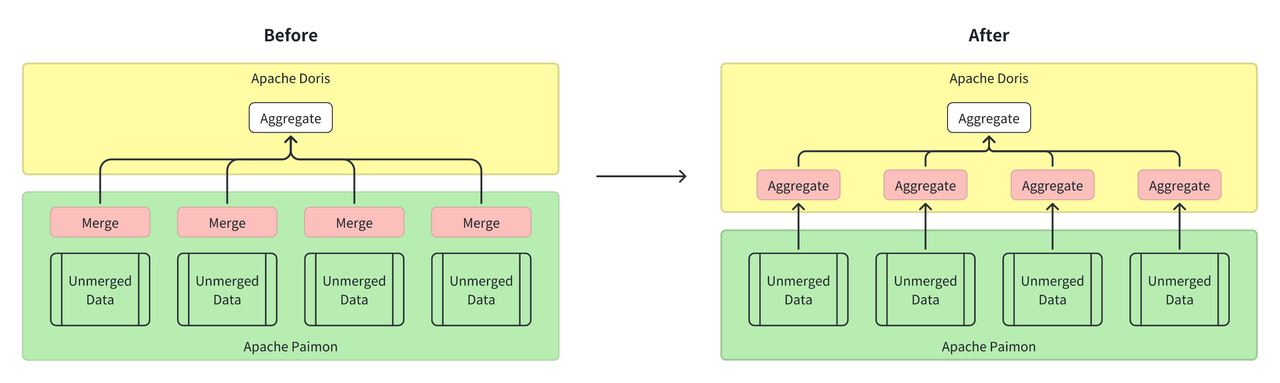
经过此方案改造,聚合表的查询时长从 40 秒缩短至 8 秒,性能提升近 5 倍。
方案二:快照级增量物化视图实现高效更新
Doris 支持 Paimon、Iceberg 等数据湖表格式的异步物化视图构建,并且支持分区级别的增量物化视图刷新与查询透明改写。物化视图作为数据库与数据湖的直接桥梁,对查询加速起到了至关重要的作用。
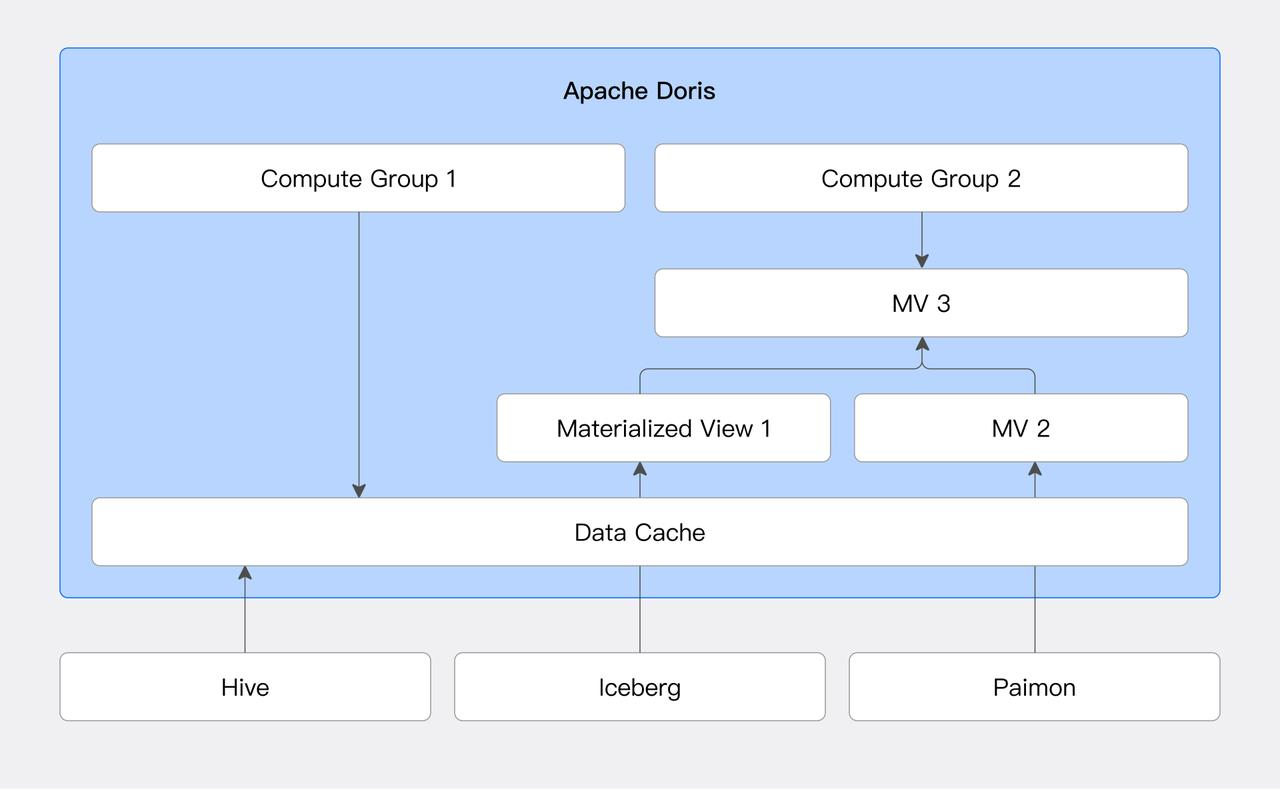
为了进一步提高物化视图的时效性,并降低物化视图的更新开销。小米进一步研发了基于快照级别的物化视图增量刷新能力,并且贡献到了 Apache Doris 社区。
首先,小米开发了 Paimon 表的快照级别的增量读取能力,如:
SELECT * FROM paimon_table@incr('startSnapshotId'='0', 'endSnapshotId'='5')
该功能可以仅读取指定 snapshot 区间的增量数据。
基于该功能,小米进一步开发了基于快照级别的增量物化视图功能:
在 Paimon 中创建一张聚合表
CREATE TABLE paimon_aggregate_table ( dt bigint, k1 bigint k2 string, v1 int, v2 double ) USING paimon PARTITIONED BY (dt) TBLPROPERTIES ( 'bucket' = '2', 'bucket-key' = 'k1,k2', 'fields.v1.aggregate-function' = 'sum', 'fields.v2.aggregate-function' = 'max', 'merge-engine' = 'aggregation', 'primary-key' = 'dt,k1,k2' );在 Doris 中创建对应的物化视图
CREATE MATERIALIZED VIEW paimon_aggregate_table_mv BUILD DEFERRED REFRESH INCREMENTAL PARTITION BY (dt) DISTRIBUTED BY RANDOM BUCKETS 2 AS SELECT dt, k1, SUM(a1) AS a1 FROM paimon_aggregate_table GROUP BY dt, k1;
Doris 的异步物化视图框架会在后台定时执行如下语句:
INSERT INTO paimon_aggregate_table_mv
SELECT dt, k1, SUM(a1) AS a1
paimon_aggregate_table@INCR('startSnapshotId'='1', 'endSnapshotId'='2')
GROUP BY dt, k1;
利用快照读取功能和 Doris 聚合功能,准实时的更新物化视图,避免全量计算。
通过此方案,更新成本显著降低,数据时效性大幅提升,且得益于 Doris 优化的 SQL 透明改写能力,用户无需修改 SQL 即可自动享受物化视图的加速效果。
方案三:HDFS 读取长尾优化与缓存机制
针对 HDFS 读取延时不稳定的问题,小米采用了如下两方面措施:
1. HDFS 快速超时与重试
- HDFS 在读取数据时,会利用多副本机制,当一个副本的读取时间超过阈值后,会切换到另一个副本尝试读取。超市阈值由参数
dfs.client.socket-timeout控制,默认是 60 秒。这导致首次读取的超时时间过长,在 HDFS 抖动或负载较高的情况下,会导致查询延迟显著增加。我们通过将该阈值降低到 100 毫秒,让读取情况进行快速的超时重试,显著降低了查询长尾,P99 性能提升 1 倍,总体性能提升 10%。

2. Doris 数据缓存
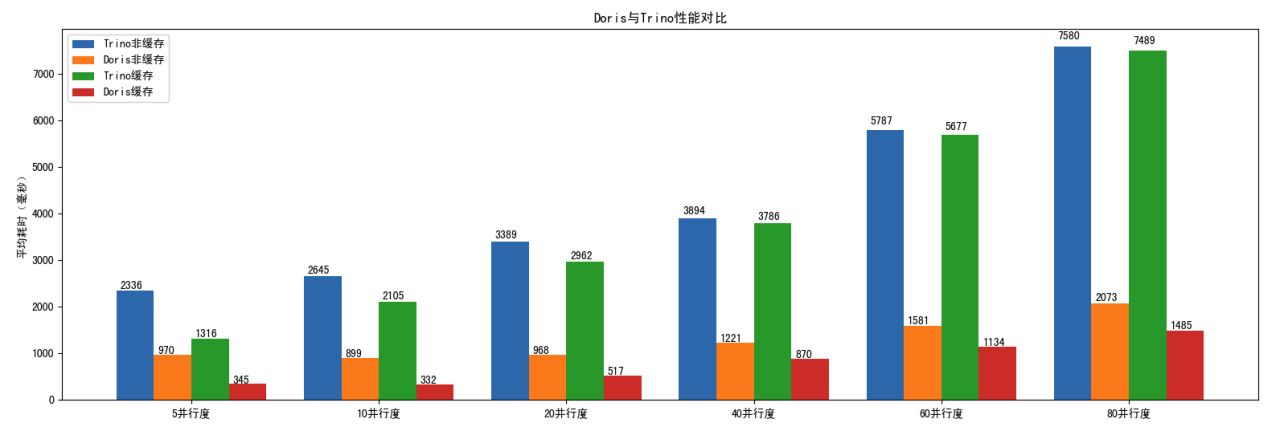
- 针对高并发查询场景,单纯的降低 HDFS 的重试超时时间,无法彻底的解决 HDFS 查询延迟高的问题。因此,我们利用 Doris 的数据缓存能力,将热点数据缓存在本地高速磁盘上,完美解决了高并发场景的查询延迟问题。在开启缓存的情况下,从 5 并发到 80 并发,查询延迟可以降低 25% 到 300%。 同时,得益于数据剪枝能力、高性能的算子,Doris 的整体查询并发能力是 Presto 的 5 倍。
总结与展望
小米在 Apache Doris 和 Paimon 上的深度融合实践,是典型的数据库与数据湖的互补增效的体现。在这些实践下,小米在湖仓数据分析场景下获得了可观的业务收益:
- 查询平均延迟从 60 秒降至 10 秒,性能提升 6 倍;
- 高并发场景下(5 并发提高至 80 并发),查询延迟降低 25% 到 300%;
- 整体查询并发能力达到 Presto 的 5 倍,有效减少了计算资源。
目前,这些能力已经全部回馈到了 Apache Doris 社区。
在未来,小米将继续探索和拓展 Apache Doris 在数据湖仓上的能力和场景,包括:
- 使用 Doris 全流量替换 Presto 集群实现降本增效。
- 进一步加强针对 Paimon、Iceberg 湖格式增量物化视图的能力。
- Doris 湖仓架构容器化以满足更灵活的部署方式。
- 基于 Doris 的 Compute Group 虚拟计算组能力实现多业务间的资源隔离,提高资源利用率,降低维护成本。


