
Lakehouse 是由“Datalake ”(数据湖)和“Data Warehouse”(数据仓库)两个词组合而成的一个概念,它将数据湖与数据仓库的优势相结合,为用户提供一个统一的数据处理环境。Lakehouse本质上是一个带有附加事务层和高性能计算引擎的数据湖,旨在结合数据湖的灵活性和广泛数据格式支持,以及数据仓库在数据管理和分析方面的优势。
**数据湖、**数据仓库 和 Lakehouse 之间有什么区别
Lakehouse 是数据湖和数据仓库的组合(可能还有很多其他意见)。Lakehouse具有开放的数据管理架构,结合了数据湖的灵活性、成本效益和规模。与数据湖一样,它还具有数据湖表格式(Delta Lake、Apache Iceberg 和 Apache Hudi)提供的数据库功能。与数据湖相比,Lakehouse具有额外的数据治理。它包括集群计算框架和 SQL 查询引擎。更多功能丰富的 Lakehouse 还支持数据目录和最先进的编排。
Lakehouse 特性
"湖仓无界",即 Lakehouse,是数据领域的全新概念。Apache Doris 作为一款现代化的数据仓库,凭借其独特的架构,完美诠释了这一理念。而 Apache Doris 之所以能被称为 Lakehouse,主要得益于其两大特性:
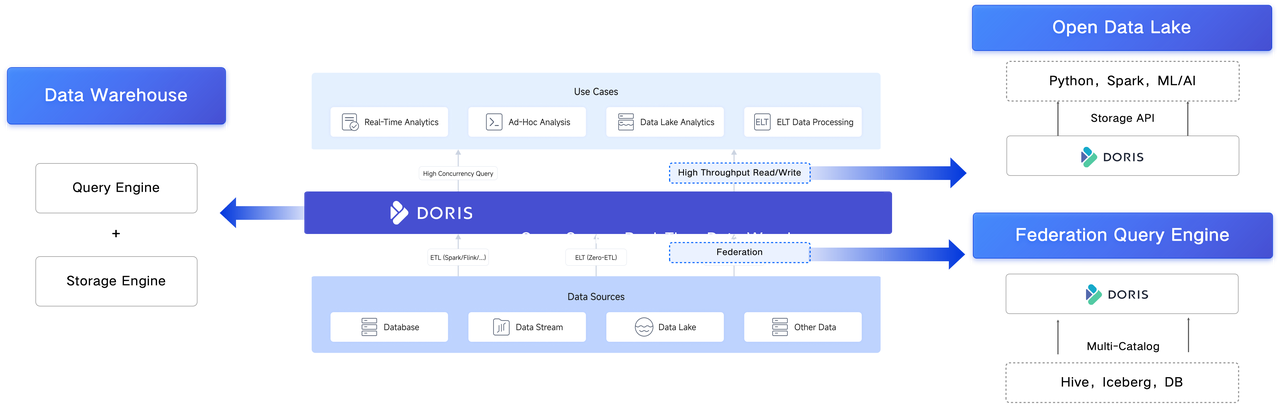
联邦查询能力:Apache Doris 通过扩展 Catalog 和存储插件,使用户无需将数据物理集中至统一的存储空间,在保持各数据源独立性的同时,仅借助 Apache Doris 即可实现多个异构数据源的统一分析,既可以直查外部表以及存储文件、也可以执行内表和外表以及外表相互之间的关联分析。此外。目前 Apache Doris 已经支持了 10 余种主流湖、仓、关系型数据库的连接器。
开放的数据湖特性:Apache Doris 引入高吞吐读写 API,也称之为 Data API 或 Storage API。打破了数据封闭性,使外部引擎能直接、高效地访问和存储 Doris 中的数据,无需受限于造成性能瓶颈的 JDBC/ODBC 协议。
凭借这些特性,Apache Doris 既能作为强大的 SQL 查询引擎,也能作为开放、灵活的数据湖,实质上满足了 Lakehouse 的定义。
那么,Apache Doris 与其他纯粹的 Lakehouse 相比较,其优势在哪里? 其核心在于“避免过早复杂性”,这里我通过一个例子来说明。
对于许多业务团队而言,其业务数据量可能仅有几百 GB,甚至更少,且尚未引入如 HDFS 这类复杂的数据架构。对于这种情况,Apache Doris 只需简单的几个节点即可迅速投入使用,部署过程极为简便。随着系统和业务需求的逐步复杂化,比如需要集成机器学习引擎或查询 HDFS 上数据时,凭借 Apache Doris 灵活的架构设计及弹性,能够实现逐步的升级与演进,无需在最开始就搭建复杂的系统。
许多用户在使用某些 Lakehouse 产品时感到不便,其根源在于这些产品要求用户在数据量有限的情况下就搭建复杂的 HDFS 及多个组件,这无疑增加了不必要的复杂性,也即“过早复杂性”。相比之下,Apache Doris 则秉持着从简单到复杂的逐步演进原则,有效避免了这一问题。
如何构建 Lakehouse
在过去多个版本中,Apache Doris 持续加深与数据湖的融合,当前已演进出一套成熟的湖仓一体解决方案。
自 0.15 版本起,Apache Doris 引入 Hive 和 Iceberg 外部表,尝试在 Apache Iceberg 之上探索与数据湖的能力结合。
自 1.2 版本起,Apache Doris 正式引入 Multi-Catalog 功能,实现了多种数据源的自动元数据映射和数据访问、并对外部数据读取和查询执行等方面做了诸多性能优化,完全具备了构建极速易用 Lakehouse 架构的能力。
在 2.1 版本中,Apache Doris 湖仓一体架构得到全面加强,不仅增强了主流数据湖格式(Hudi、Iceberg、Paimon 等)的读取和写入能力,还引入了多 SQL 方言兼容、可从原有系统无缝切换至 Apache Doris。在数据科学及大规模数据读取场景上,Doris 集成了 Arrow Flight 高速读取接口,使得数据传输效率实现 100 倍的提升。
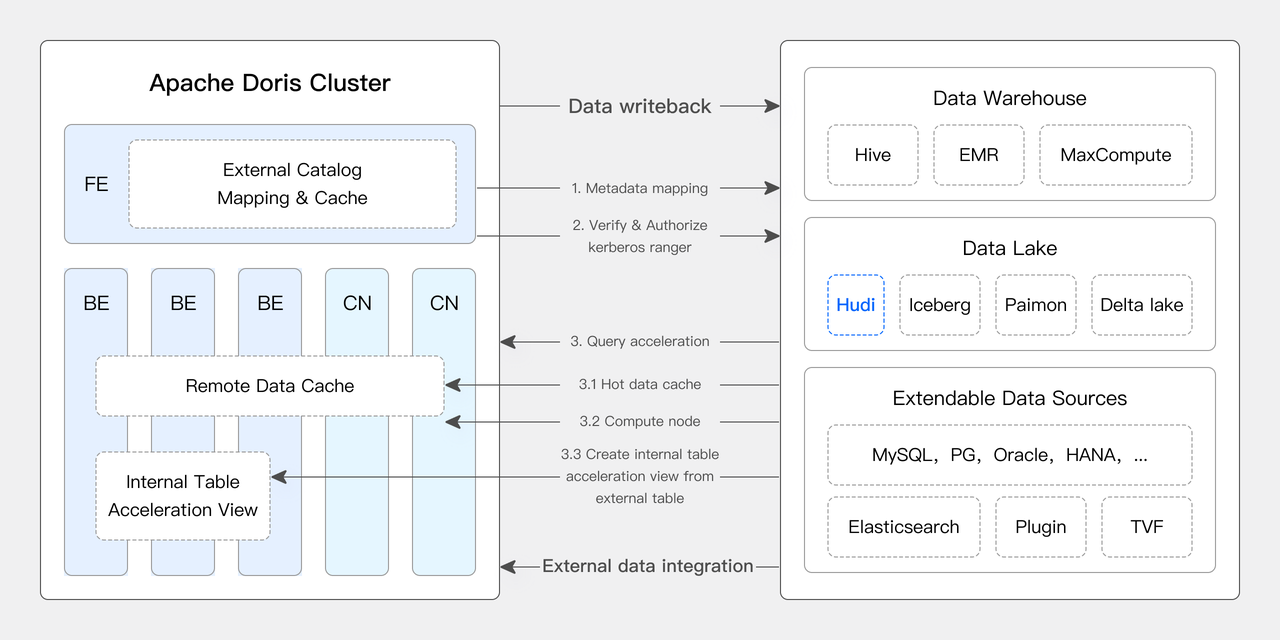
从 3.X 版本开始,Apache Doris 除了支持计算存储一体模式外,还支持计算存储分离模式进行集群部署。借助将计算和存储层解耦的云原生架构,用户可以在多个计算集群之间实现查询负载的物理隔离,以及读写负载的隔离。
使用 Doris 和 Hudi 构建 Lakehouse 指南:
01 环境准备
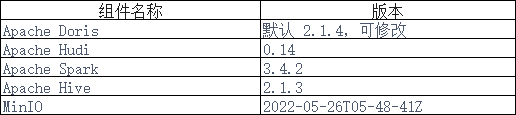
本文示例采用 Docker Compose 部署,组件及版本号如下:
02 环境部署
1、创建 Docker 网络
sudo docker network create -d bridge hudi-net
2、启动所有组件
注:启动前,可将 start-hudi-compose.sh 中的 DORIS_PACKAGE 和 DORIS_DOWNLOAD_URL 修改成需要的 Doris 版本。建议使用 2.1.4 或更高版本。
sudo ./start-hudi-compose.sh
3、启动后,可以使用如下脚本,登陆 Spark 命令行或 Doris 命令行:
--Doris
sudo./login-spark.sh
--Spark
sudo./login-doris.sh
03 数据准备
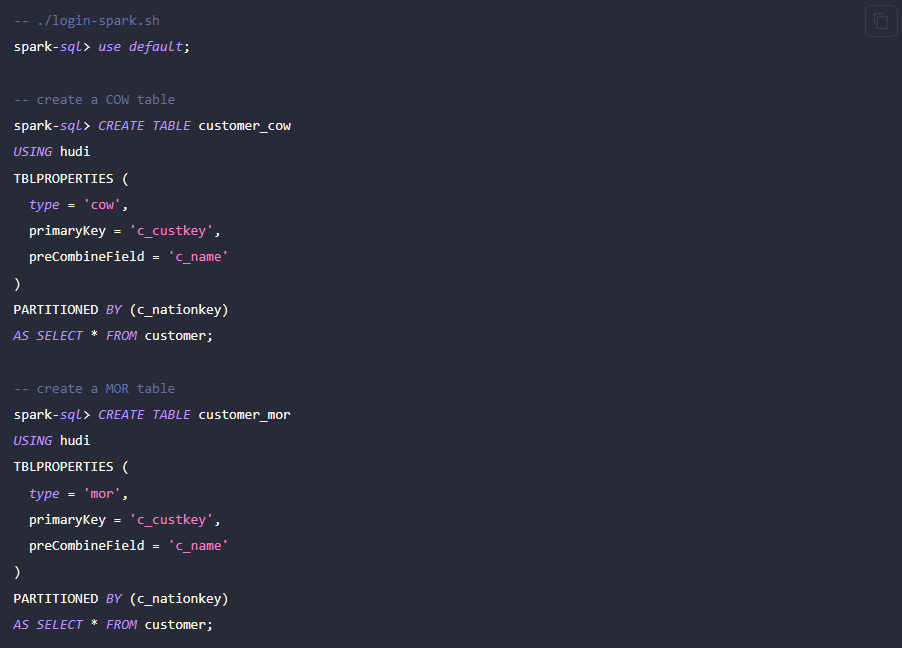
接下来先通过 Spark 生成 Hudi 的数据。如下方代码所示,集群中已经包含一张名为 customer 的 Hive 表,可以通过这张 Hive 表,创建一个 Hudi 表:
04 数据查询
如下所示,Doris 集群中已经创建了名为 hudi 的 Catalog(可通过 SHOW CATALOGS 查看)。以下为该 Catalog 的创建语句:
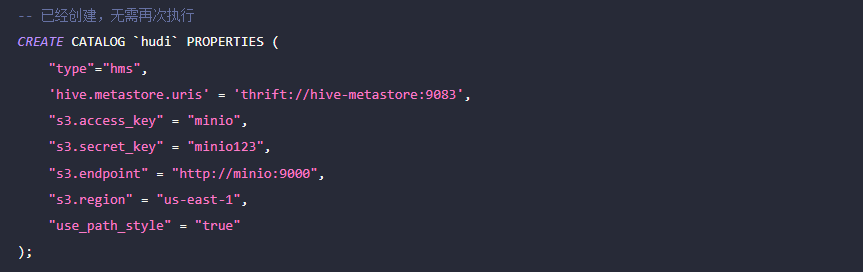
1、手动刷新该 Catalog,对创建的 Hudi 表进行同步:
-- ./login-doris.sh
doris> REFRESH CATALOG hudi;
2、使用 Spark 操作 Hudi 中的数据,都可以在 Doris 中实时可见,不需要再次刷新 Catalog。我们通过 Spark 分别给 COW 和 MOR 表插入一行数据:
spark-sql> insert into customer_cow values (100, "Customer#000000100", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 25);
spark-sql> insert into customer_mor values (100, "Customer#000000100", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 25);
3、通过 Doris 可以直接查询到最新插入的数据:
doris> use hudi.default;
doris> select * from customer_cow where c_custkey = 100;
doris> select * from customer_mor where c_custkey = 100;
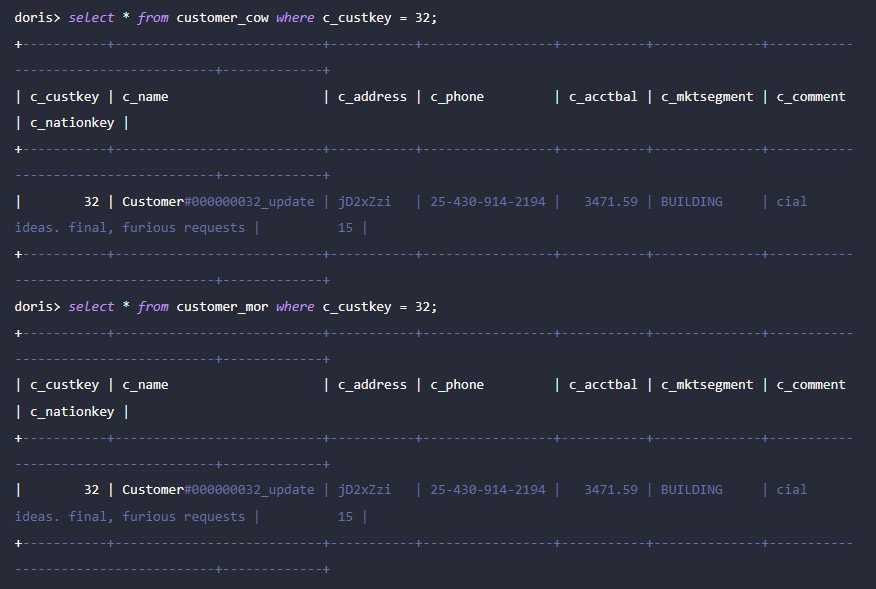
4、再通过 Spark 插入 c_custkey=32 已经存在的数据,即覆盖已有数据:
spark-sql> insert into customer_cow values (32, "Customer#000000032_update", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 15);
spark-sql> insert into customer_mor values (32, "Customer#000000032_update", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 15);
5、通过 Doris 可以查询更新后的数据:
05 Incremental Read
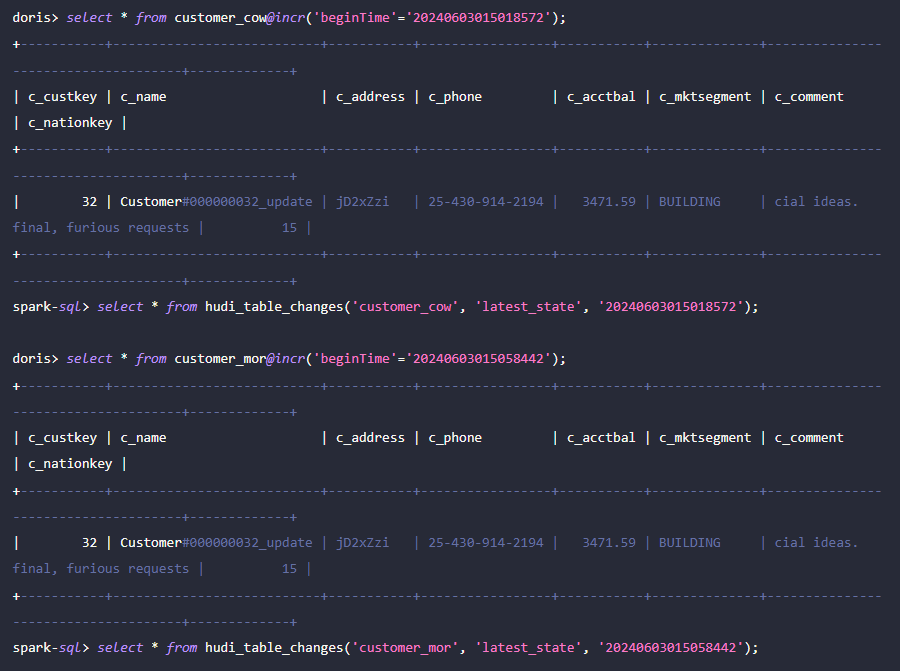
Incremental Read 是 Hudi 提供的功能特性之一,通过 Incremental Read,用户可以获取指定时间范围的增量数据,从而实现对数据的增量处理。对此,Doris 可对插入 c_custkey=100 后的变更数据进行查询。如下所示,我们插入了一条 c_custkey=32 的数据:
06 TimeTravel
Doris 支持查询指定快照版本的 Hudi 数据,从而实现对数据的 Time Travel 功能。首先,可以通过 Spark 查询两张 Hudi 表的提交历史:
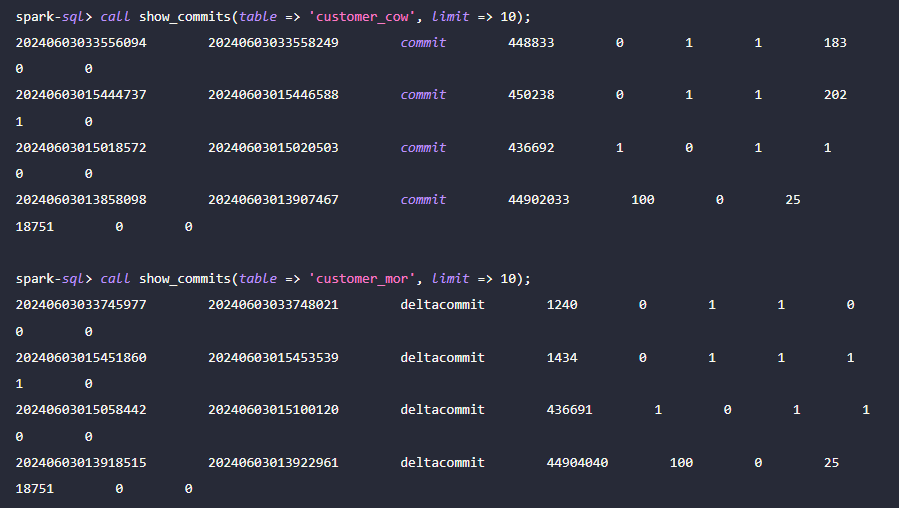
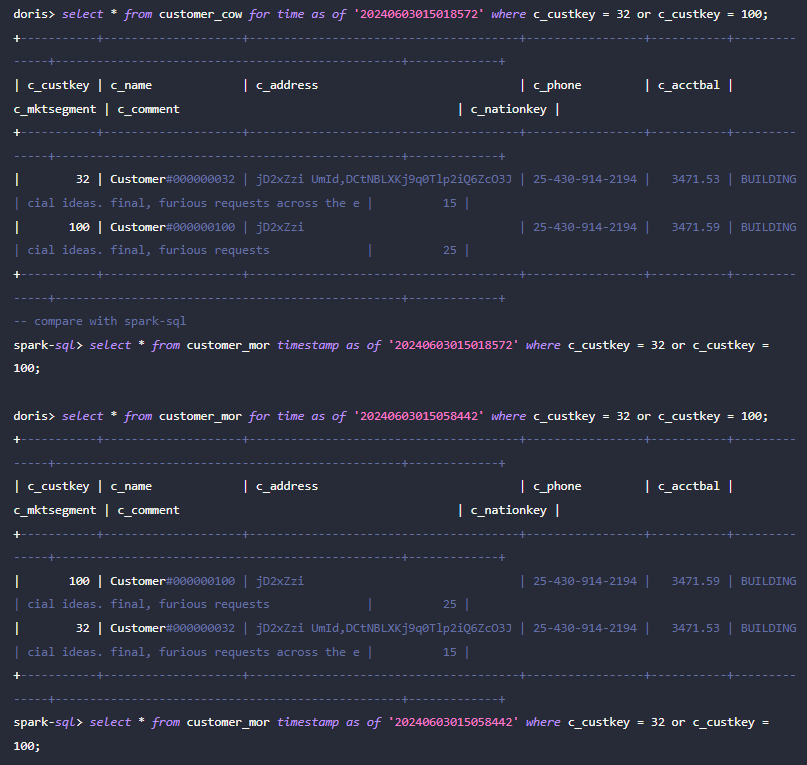
接着,可通过 Doris 执行 c_custkey=32 ,查询数据插入之前的数据快照。如下可看到 c_custkey=32 的数据还未更新:
注:Time Travel 语法暂时不支持新优化器,需要先执行 set enable_nereids_planner=false;关闭新优化器,该问题将会在后续版本中修复。
更多构建 Lakehouse 方法可以来咨询我们,我们是一家基于开源分析型数据库 Apache Doris 的商业化公司,由 Apache Doris 原创团队于2022年1月创建,公司总部位于北京,面向全球提供实时数据仓库的产品与解决方案,满足各类场景的实时数据分析需求。飞轮科技的创始团队来自于原百度智能云初创人员和 Apache Doris 项目核心成员。


