导读:近几年随着跨境电商行业的快速发展,Lifewit 业务达到近十倍的增长,原先的痛点已经严重影响到用户的数据使用体验。技术端需要随着业务的飞速发展不断升级迭代适应业务的增长。Lifewit 规划了从旧数据架构进化成目前基于 Apache Doris 构建的轻量级业财一体化数据平台,来系统化地解决旧架构存在的痛点,打通业务数据和财务数据,构建综合数据平台提供全业务链自助数据分析能力,支撑完善的数据报表体系和高效的数据分析。
业务背景
Lifewit 是一家专注于打造全球创新家居场景品牌的企业,通过自主研发、自主设计、品牌策划、技术驱动、垂直供应链、数字化人力资源形成一套“六位一体”化的特色经营体系。Lifewit 拥有自主的 B2C 品牌商城,深耕 Amazon 平台,同步入驻全球潜力电商平台,销售市场已覆盖全球上百个国家,服务上千万全球客户。
在我们业务场景中,数据大多来源于各个平台报表和各个业务系统产生的数据,旧架构直接基于关系型数据库构建报表数据,数据源系统多而复杂,还经常发生变化;复杂计算缺少分层建设导致拖垮从库;ETL 存在多种形态,没有统一建设和管理,排查问题比较艰难;源头数据的变化导致大量的下游表发生差异,需要及时重新计算;但发生变化的数据影响面分析困难,异常问题排查耗时人工成本高。这些都属于旧数据架构的一些痛点。
经过了近几年跨境电商行业的快速发展,我们的业务达到近十倍的增长,原先的痛点已经严重影响到用户的数据使用体验。技术端需要随着业务的飞速发展不断升级迭代适应业务的增长,所以我们今年规划了从旧数据架构进化成目前基于 Apache Doris 构建的公司轻量级业财一体化数据平台,来系统化的解决旧架构存在的痛点,打通业务数据和财务数据,构建综合数据平台提供全业务链自助数据分析能力,支撑完善的数据报表体系和高效的数据分析。
整体架构
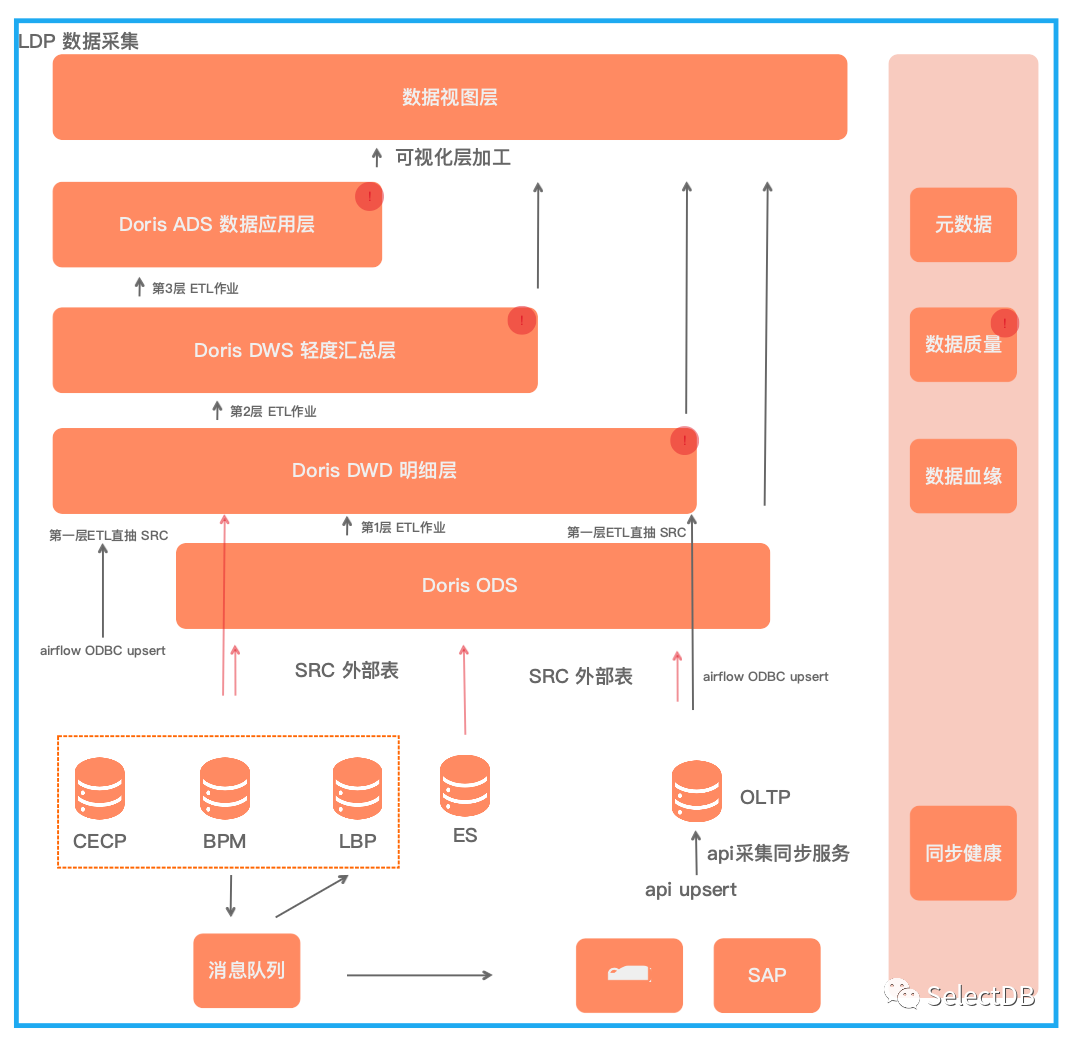
数据架构
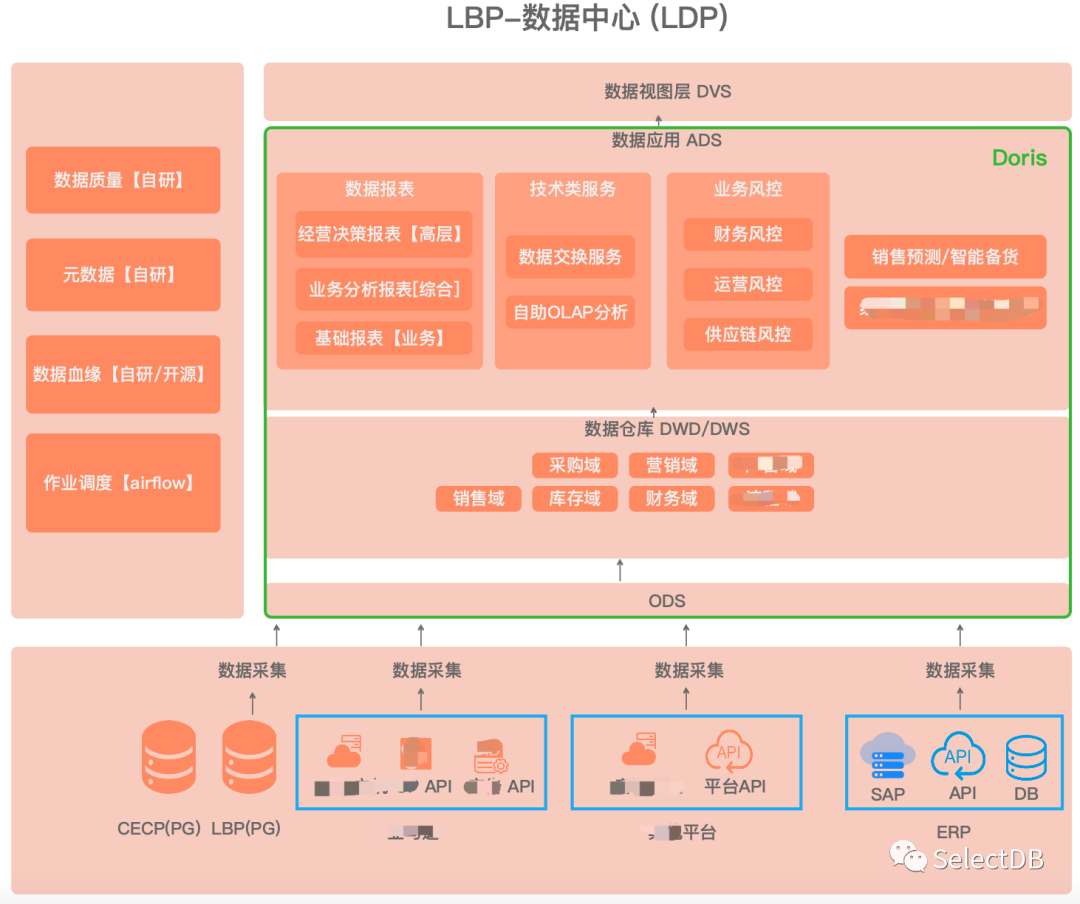
CECP: 老综合业务系统,核心模块是供应链和财务相关,逐步升级成 LBP
LBP:Lifewit 新业务平台,覆盖公司全业务链业务平台
LDP:Lifewit新数据平台,覆盖公司全业务链数据应用
数据调度:LDP采用 Airlfow 承接调度能力,Airflow 是一个使用 Python 语言编写的 Data Pipeline 调度和监控工作流的平台。Airflow 是通过 DAG(Directed acyclic graph 有向无环图)来管理任务流程的调度工具,支持自定义 Operator/Hook,还支持触发规则自定义,具备丰富的可扩展能力。
数据采集:LDP 目前实现主要是分钟级和小时级任务,支持两类采集,一类定时 API 增量采集,一类定时 OLTP 数据源增量采集,OLTP 增量采集直接构建在 Airflow,通过 Doris 连接 OLTP 从库数据源进行自定义规则采集。
数据仓库和数据应用都是基于 Doris构建,数据视图层基于开源版/商业版BI软件构建。
元数据:自研,支持 PG、MySQL、Doris 的元数据自动化采集和管理。
数据质量:自研,支持自定义 SQL 对数据仓库,数据应用层指标进行自定义监控和告警。
数据血缘:目前的开源数据血缘不太适合我们公司,还在调研 DBT 中,第二期重点考虑 DBT 生产化可行性。
测试集群概况
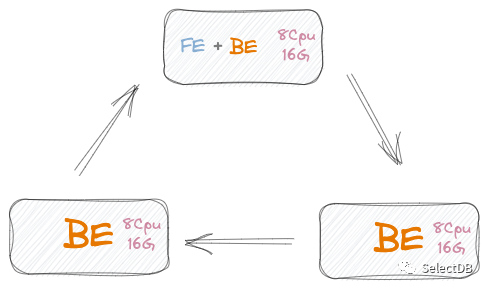
测试环境配置:
- 三台 8 核 16 G云服务器
- 三台 BE,一台 FE,其中一台 BE 混布
- Ubuntu 18.04,CPU 支持 avx2
目前我们还处于数据架构升级的初始阶段,仅接入了部分销售数据,测试集群规模如下,目前已接入业务的数据量在千万级别,后续持续会有更多旧数据业务以及新的业务线接入进来。

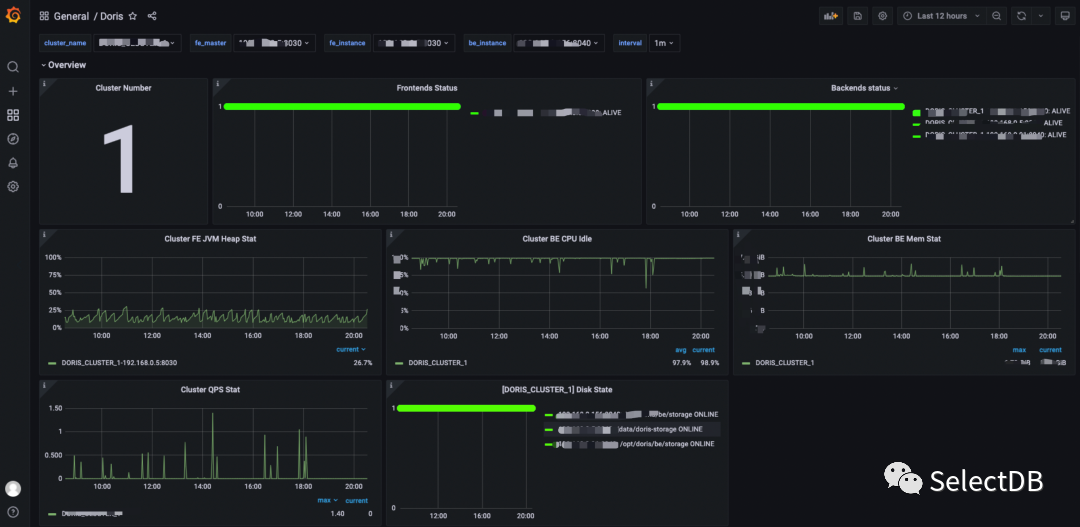
集群监控
基于 Grafana+Promethus 构建集群监控可视化,以下监控图是测试环境监控部分截图。
数据采集
采集方案
LDP 目前实现主要是分钟级和小时级任务,通过 Airflow+Doris 轻量级支持 2 类采集。
一类定时 API 增量采集,通过调用 ERP 等其他业务系统的 API 进行增量数据采集到 Doris ODS 层。
一类定时 OLTP 数据源增量采集,OLTP 增量采集直接构建在 Airflow ,通过 Doris 连接 OLTP 从库数据源进行自定义规则采集,达到增量数据源源不断的进入 Doris ODS 层。
第二期支持实时采集 Binlog 入 Doris ODS 功能。
采集接入
ODBC 环境搭建
注意:所有 BE 都需如法安装,并保持相同配置
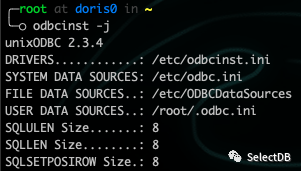
安装操作系统 ODBC 驱动:
apt install unixodbc
检查是否安装成功:
安装 MySQL ODBC 驱动:
选型:

下载地址:https://downloads.mysql.com/archives/c-odbc
放置 Lib 目录
注册 ODBC 驱动:
myodbc-installer -a -d -n "MySQL ODBC 8.0.11 Unicode Driver" -t "Driver=/usr/lib/mysql-odbc-8.0.11/libmyodbc8w.so"
myodbc-installer -a -d -n "MySQL ODBC 5.3.13 Unicode Driver" -t "Driver=/usr/lib/mysql-odbc-5.3.13/libmyodbc5w.so"
查看是否注册成功
myodbc-installer -d -l
MySQL ODBC 5.3.13 Unicode Driver
MySQL ODBC 8.0.11 Unicode Driver
- 验证 ODBC 连接 MySQL
编辑 /etc/odbc.ini 文件:
[mysql]
Description = Data source MySQL
Driver = MySQL ODBC 8.0.11 Unicode Driver
Server = 192.168.20.17
Host = 192.168.20.17
Database = test
Port = 23306
User = root
Password = sakdfwexkjsga134wesdgdsa4
执行
isql -v mysql
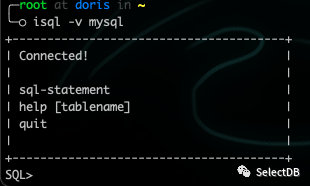
至此操作系统层通过 ODBC 是可连接到 MySQL。
ODBC 接入 Doris
编辑 be/conf/odbcinst.ini 增加以下配置:
[MySQL ODBC 8.0.11 Unicode Driver]
Description = ODBC for MySQL 8
Driver = /usr/lib/mysql-odbc-8.0.11/libmyodbc8w.so
FileUsage = 1
[MySQL ODBC 5.3.13 Unicode Driver]
Description = ODBC for MySQL 5
Driver = /usr/lib/mysql-odbc-5.3.13/libmyodbc5w.so
FileUsage = 1
ODBC 如何使用
创建 Resource:
create external resource test_resource properties(
"type"="odbc_catalog",
"odbc_type" = "mysql",
"host"="127.0.0.1",
"port"="23306",
"user"="root",
"password"="sakdfwexkjsga134wesdgdsa4",
"database"="test_db",
"driver"="MySQL ODBC 8.0.11 Unicode Driver"
);
创建外部表:
CREATE EXTERNAL TABLE `sku` (
`id` int(11) NULL COMMENT "",
`sku` varchar(64) NULL COMMENT "",
`name` varchar(128) NULL COMMENT "",
`type` varchar(128) NULL COMMENT "",
`creator_id` int(11) NULL COMMENT "",
`create_time` datetime NULL COMMENT "",
`updater_id` int(11) NULL COMMENT "",
`update_time` datetime NULL COMMENT ""
) ENGINE=ODBC
COMMENT "TEST"
PROPERTIES (
"odbc_catalog_resource" = "test_resource",
"database" = "test_db",
"table" = "sku"
)
具体使用场景:
- 从外表定时增量采集到 Doris,主要是通过 AirFlow 定时任务执行 insert into select 语句方式采集
- 查询时直连外表(数据量小),业务表很多,无需采集数据即可方便直接查询,若外表数据过大,或查询批次太高不建议直连
数据仓库
分层设计
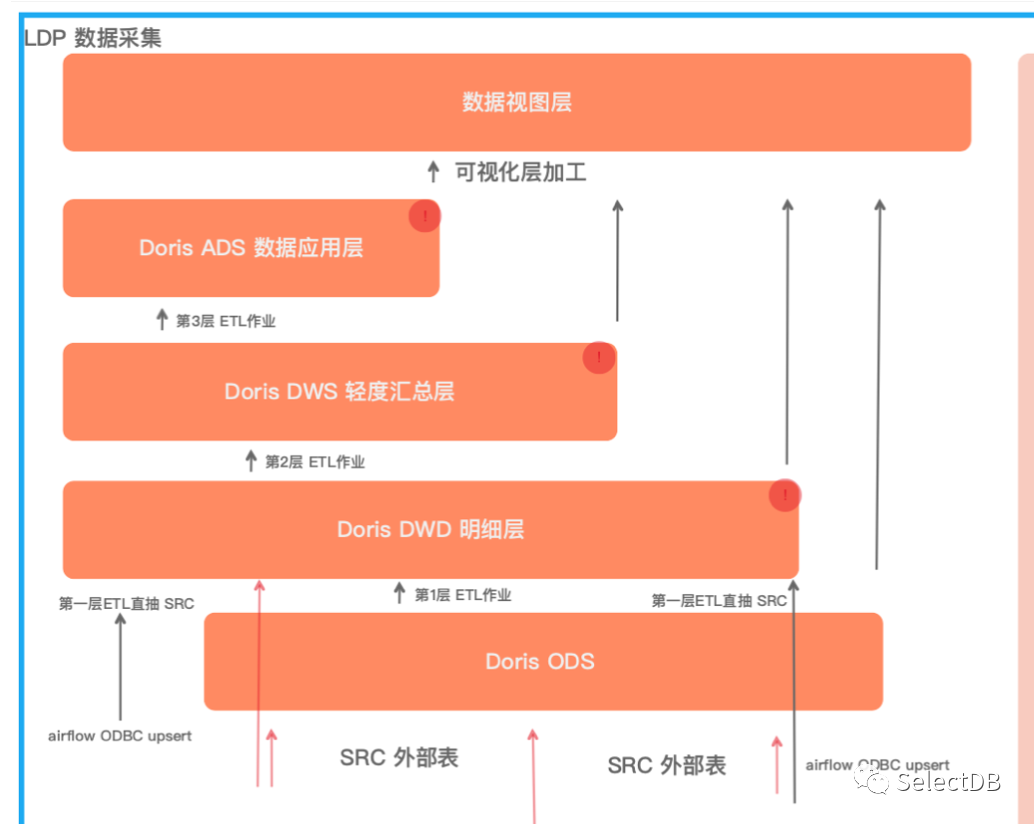
SRC:数据源,主要来自各业务系统和亚马逊报表,以 PG、MySQL、ES 为主,采用Doris ODBC 外部表实时直连从库,用于采集。
ODS:原始数据层,存放原始数据,主要是离线/实时写入的数据,与数据来源保持一致,还原数据过程。
DWD:数据明细层,根据需求从 SRC/ODS 层清洗数据存储到 Doris 中,采用 Uniq 模型。
DWS:轻度汇总层,从 DWD 轻度汇总数据,采用 Uniq 模型,构建命名规范、口径一致的统计指标,为上层提供公共指标。
ADS:数据应用层,和业务强相关的数据应用层,构建 ADS 是以需求为驱动,应用层主要是各个业务方或者部门基于 DWD 和 DWS 建立的数据集市。
DVS:数据视图层,BI 可视化对应的视图表,在 DVS 直接抽取和计算来自从 ADS、DWS 等层次的数据。
根据实际业务复杂性会存在跨层建设场景,不会严格按照每一层进行建设。
从外表采集数据到 DWD 层:
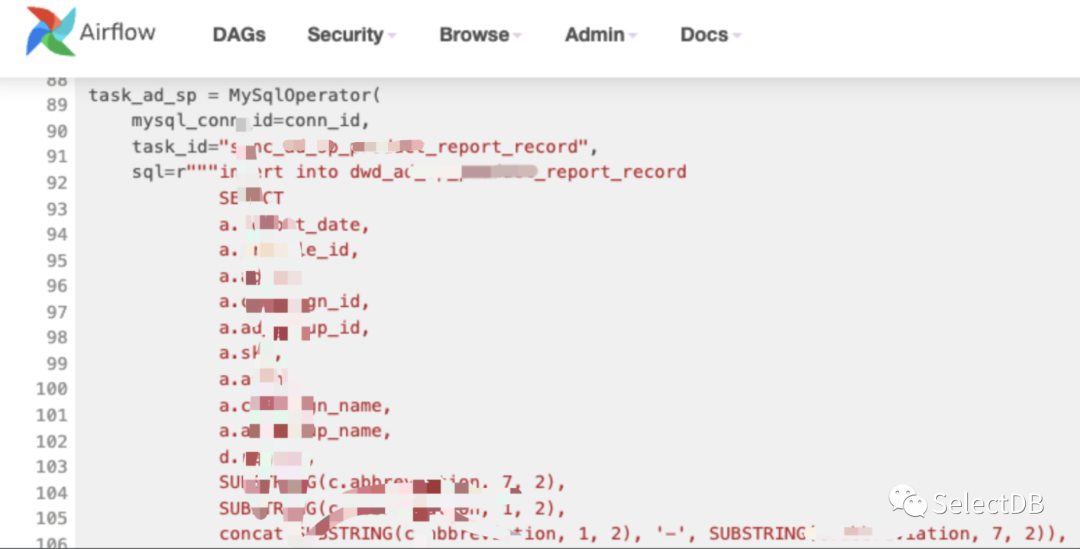
根据业务规则生成 DWS 层数据:

通过 Airflow 编写简单的 Python 代码进行任务调度编排:
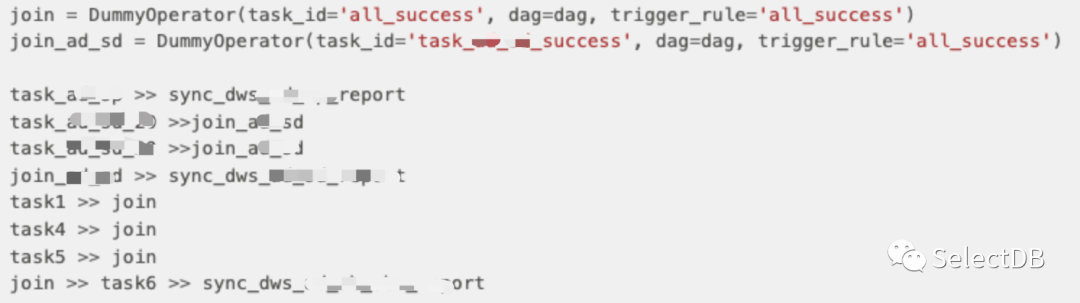
Airflow 作业销售数据报表作业 DAG:
维度 Join 好处
传统基于 Hadoop 生态构建数据仓库,在进行建模的时候,广泛的采用的是大宽表,将指标列和维度列放在同一张表上。这会带来一个问题:当维度修改的时候,需要对数据任务进行重跑对数据进行回溯,重新聚合计算,这样的话回溯时间越长需要消耗时间越久。
我们使用 Doris 做存储和分析,由于 Doris 具备多表 Join 性能良好,采用星型关联表来建模,可以支持维度的动态修改,降低数据重跑回溯的成本。
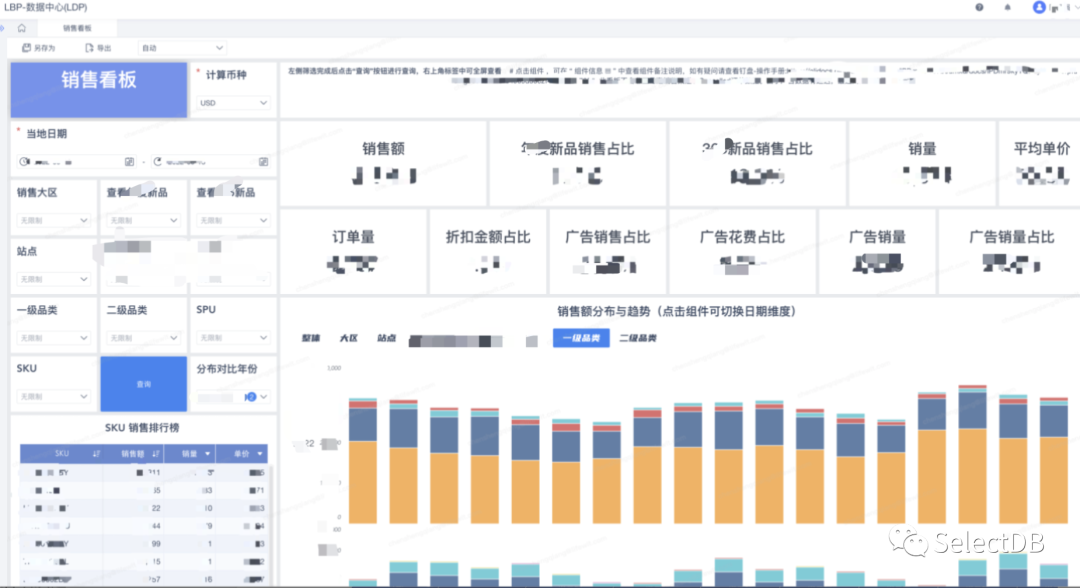
数据可视化
数据可视化属于 LDP 数据视图层,截图属于销售看板应用,数据来自 DWS/ADS 层销售数据。构建了销售数据的多维度的自助分析能力,主要使用用户是运营中心。销售数据属于我们第一期的建设范围,其他业务陆续接入。

数据质量
数据质量
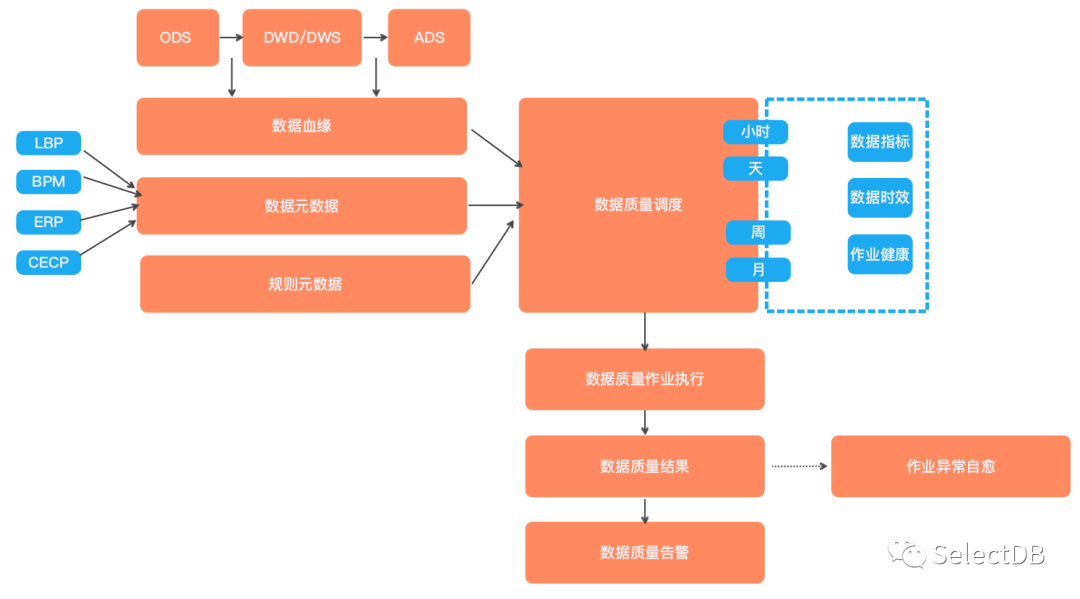
新数据架构建了基础的作业流和复杂的作业流,随着业务任务量增加,作业的故障问题对于用户来说容忍度会越来越低,如何监控生产作业的稳定性,避免经常在发生用户投诉后才发现任务异常,对于数据平台来说极为重要的环节。
我们数据架构的作业健康分 2 类,作业质量(即 DAG/TASK 的质量),数据质量(即数据指标,数据时效等数据类质量)。
DAG 质量和 TASK 质量就需要定时监控 DAG 和 TASK 元数据(存储在 MySQL 数据库内),监控 DAG 和 TASK 增量运行健康情况,定义监控规则是监控 TASK 还是 DAG,具体的监控细节是捕获到何种异常进行对应的分级告警。解决作业失败发现不及时导致发生重大故障问题,解决数据堆积导致最终结果交付延迟问题。
数据质量,涵盖数据指标,数据时效等,以及反向要求数据底层需具备一定时限的自愈机制,降低数据质量异常频率。通过数据质量定时作业检查配置好的质量规则,通过监控数据质量结果,达到统一告警的机制。我们 LDP 架构的刚上线,服务的数据应用不多,系统化的数据质量还未完全铺开。第一期主要先针对具体数据应用常见问题构建分模块的数据质量应用进行监控告警或自愈。第二期进行数据质量系统化建设。
元数据
作业质量和数据质量的管理,离不开元数据和数据血缘的建设,广义的 LDP 数据血缘涵盖任务血缘(Airflow 的 DAG ),作业血缘(Airflow 的 DAG 内部的 TASK ),数据血缘(和 Airflow 无关,在整个数据平台,数据生产形成的数据血缘链路),只有掌握了数据流的具体流向才能识别单点故障对整个数据平台的影响,而不是遇到问题只是单点解决问题,无法找到波及面,更不用说如何及时的修复波及面。
第一期的数据平台我们任务不多,没有做到完整的数据血缘采集,只实现了元数据管理。对接入数据平台的所有库,表,字段,计算逻辑,依赖关系进行统一管理。
通过依赖关系的维护,以及具体应用的指标监控,来识别异常指标波及面进行人工的异常分析和作业重跑。
第二期进行完整的数据血缘采集,实现完整的通用的数据自愈和故障影响面自动分析功能。
数据自愈
第一期的数据自愈主要是针对具体应用需求进行开发,本次生产作业是在两层之间增加一个数据健康检查任务,由于报表数据和业务数据经常发生变动,导致 DWD、DWS 的数据和 SRC 层数据发生偏差,需要寻找有偏差的数据,并通过 Airflow 重跑任务,当前采用 Delete + Insert 方式。
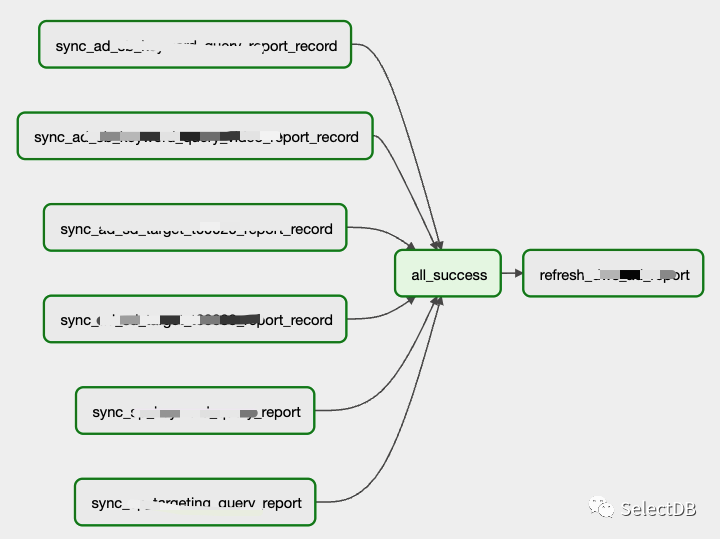
旅行者
健康检查时间段有限制,不可能无条件检查历史数据,于是需要一个方案进行更久以前的各层数据比对、汇总和告警。
- 健康检查例行过去 30 天的数据,数据对不上将触发重跑
- 30 天以外的数据用新任务负责低频检查和告警
目前数据质量还是针对具体业务实现具体的告警规则,下一阶段实现通用的数据质量管理体系。
实践总结
数据质量
- MySQL ODBC 版本选择问题:
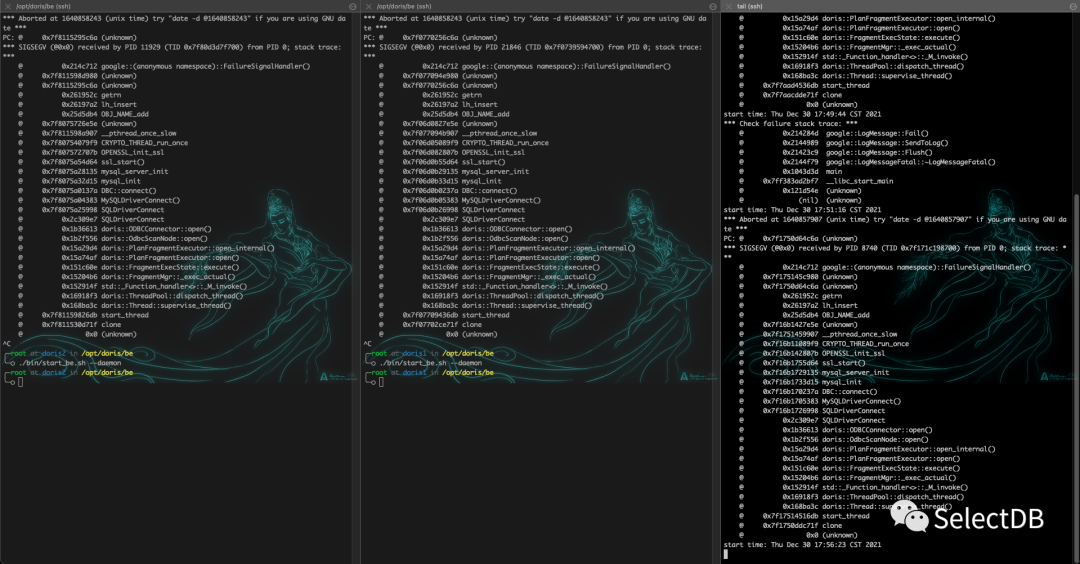
具体选型见 ODBC 环境搭建环节,版本选择不对可能导致 BE 挂掉。
- -235 问题:
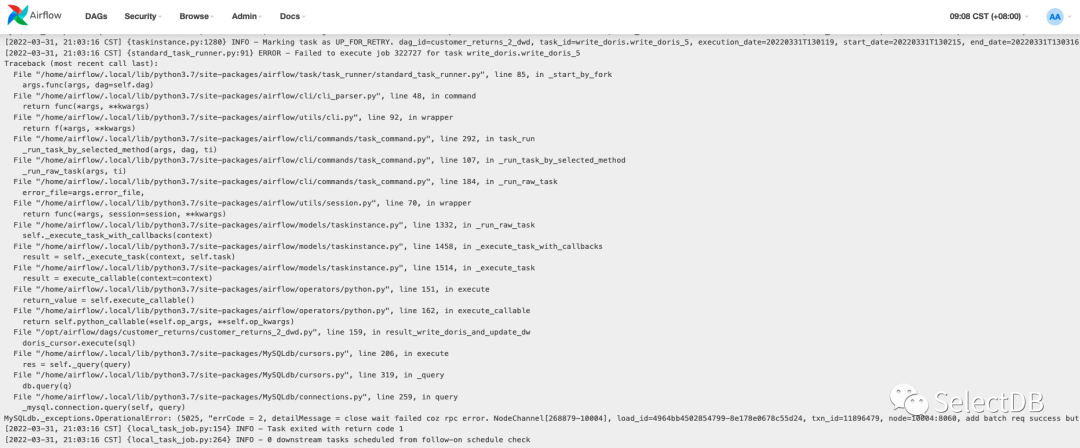

解决方案:
curl -X POST http://{be_ip}:
{be_http_port}/api/update_config?min_compaction_failure_interval_sec=30&persist=true
在 Cumulative Compaction 过程中,当选中的 Tablet 没能成功地进行版本合并,则会等待一段时间后才会再次有可能被选中。等待的这段时间就是这个配置的值,默认 5s 在插入速率过大,而批次量过小时容易产生,此时需要调大配置,减少插入速率,增加单次插入量。
新架构的收益
- 采用基于 Apache Doris 的数据平台方案减轻了传统大数据搭建的服务器成本和运维人力成本。
- 数据平台方案整个链路和传统 Hadoop 数仓链路相比大大缩短,链路越短,数据稳定性维护越简单。
- 磁盘占用量大幅度降低。旧数据架构存在大量索引和分区等优化策略,导致某些表的索引比业务数据还大,使用 Doris 后存储所占用的资源大幅降低。
- 数据分层结构清晰。根据三种不同特性的数据模型设计不同层次的表结构。Uniq 作为 DWD 或者 ODS 层,Uniq/Agg 作为 DWS 层,Agg 作为 ADS 层。
- 查询速度提升。BI 查询聚合好的 ADS 层数据,发挥 Agg 模型最大效能。
- ODBC 模式的采集方式减少ETL流程,降低复杂度,提高开发效率。
- 物化视图自动刷新。PG 的物化视图和源表数据分离,源表数据变动需要手动重刷容易出错。Doris 自动刷新和查询透明机制,直查源表自动匹配最优物化视图。
- 由于良好的多表 Join 性能,采用星型关联表来建模,可以支持维度动态修改,降低回溯成本。
后续演进
随着 LDP 数据平台服务的数据应用越来越多,后续对整个 LDP 数据平台架构需要更丰富的功能,更实时,稳定,安全的数据交付能力,更便捷的平台管理能力。
LDP数据平台第二期优先功能范围:
- 数据血缘和数据自愈实现,任意表延迟多层自动修复
- 更实时采集 Binlog,支撑实时数仓建设
- 通用数据质量,支持任意数据源,任意指标的自定义监控和告警
目前基于 Apache Doris 的 LDP 数据平台在乐活科技的第一个数据应用得到用户的广泛认可, 用户更加期待后续数据应用可以快速产出和赋能业务。感谢 Apache Doris 社区给予的支持,使我们能够快速构建轻量级 LDP数据平台的基建设施,祝愿 Apache Doris 社区发展越来越好!