降本增效,作为企业持续发展的核心驱动力,不仅关乎成本控制,更在于通过技术创新提升整体运营效率。企业竞争力越来越依赖于其高效运营和精准决策的能力,两种能力的提升又需要庞大的数据支撑。企业庞大的数据急需一个安全易用的载体来承接,就目前的市场使用占有率来看数据仓库是企业的最佳选择。
数据仓库作为企业数据管理的核心,承载着存储、整合、分析和查询企业数据的重要任务。然而,传统的数据仓库架构在扩展性、实时性和数据处理能力上逐渐暴露出局限性。随着大数据时代的到来,企业对数据的需求日益复杂多样,传统数据仓库已难以满足高效运营和精准决策的需求。因此,数据仓库架构的进化势在必行。
对于市面上五花八门的数据仓库以及数据处理工具,到底应该如何选择,下面的一个真实案例来告诉您:
腾讯音乐娱乐集团(以下简称“腾讯音乐”)是中国在线音乐娱乐服务开拓者,有着广泛的用户基础,总月活用户数超过 8 亿,通过“一站式”的音乐娱乐平台,用户可以在多场景间无缝切换并享受多元的音乐服务。他们希望通过技术和数据赋能,为用户带来更好的体验,为音乐人和合作伙伴在音乐制作、发行、销售等方面提供支持。
接下来将详细介绍腾讯音乐内容库如何基于 Apache Doris 构建查询高效、实时写入且统一的 OLAP 分析引擎,使 OLAP 作为底层基建加强大模型与之连接转化的效率、结果输出的准确率,最终提供更智能化的问答交互服务,也希望通过这篇文章为有相关业务需求的公司提供不同视角和思路。
数据服务早期的痛点与挑战:
SQL 查询平台 : 业务分析师根据需求进行 SQL 语句编写,对平台数据进行查询分析,每位业务人员都需要掌握 SQL,导致学习成本高、上手难度大。
固定看板(Dashboard) : 技术人员基于常规业务开发制作数据看板,虽然能够简化业务分析师查询的过程,但是看板制作成本高且灵活度低,当面对复杂的用户问题时,看板无法及时调整以满足需求变更。
定制分析工具: 基于特定的业务需求,技术人员需要定制化开发产品分析工具,整体开发成本过高,且单一的开发工具不具备通用性,随着工具数量增加,操作介面变得散乱,从而降低业务效率。
人工跑数: 当以上三个场景都无法满足业务需求时,业务分析师需要向技术人员提需求进行人工跑数,沟通成本过高、整体解决效率低下。
数据仓库架构的进化
在平台构建的过程中,OLAP 引擎作为整体架构的基建对 SQL 语句处理、数据存储分析、上游应用层的查询响应等有着至关重要的作用,我们希望通过架构升级以加强大模型到 OLAP 引擎的转化效率与结果输出准确性。
数据仓库架构1.0
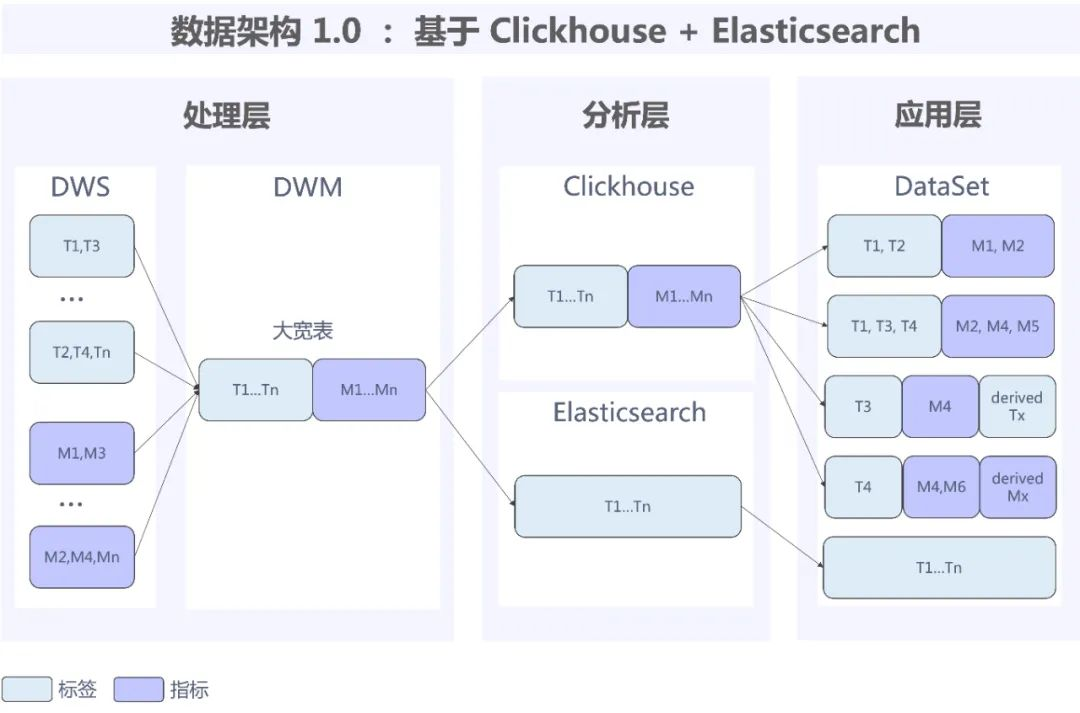
在实际业务使用中,早期架构的数据处理方式存在大宽表带来的数据延迟与存储浪费、多套组件导致架构冗余带来指标维度重复定义、学习与运维成本高等问题,具体如下:
1、数据延迟: 处理层不支持部分列表更新,DWS 层数据写入产生延迟后会造成大宽表的延迟,进而导致数据时效性下降。
2、运维成本高: 在处理层大宽表中维度数据量平均占一张大宽表的 50%,且在大部份情况下变化缓慢,这意味着每一张宽表的开发会将维度数据叠加,造成存储资源的浪费、维护成本增加;在分析层中存在多引擎使用的问题,查询 SQL 语句需要同时适配 Clickhouse 与 Elasticsearch 两个组件,增加人力成本,且两套组件也会加大运维难度,运维成本进一步升高。
3、架构冗余: 在应用层进行指标与维度定义时,导致相同数据会进行多次定义使各种指标、维度定义口径不一致,造成权限不可控,例如上图所示的 T1 (标签)与 M1 (维度)在应用层中,被不同数据集多次定义。
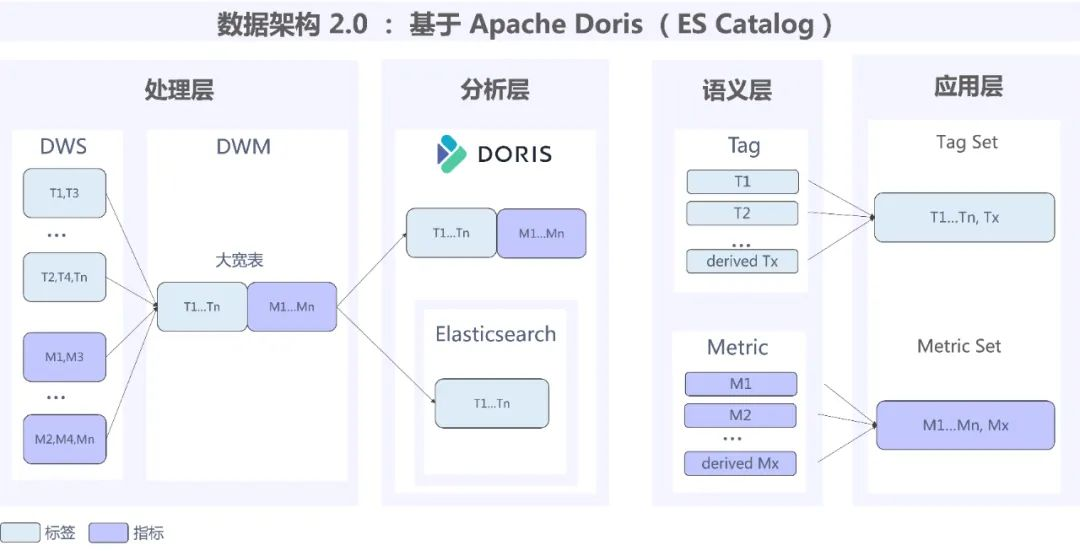
数据仓库架构 2.0
基于以上问题,我们开始对架构进行改造升级,并在众多 OLAP 引擎中选择了 Apache Doris 来替换原有组件,主要因为 Apache Doris 具备以下核心优势:
实时导入: Apache Doris 能够支持海量业务数据的高吞吐实时写入,时效性可以做到秒级完成导入。
引擎统一: 支持 Multi-Catalog 功能,能够通过 Elasticsearch Catalog 外表查询,实现查询出口统一,查询层架构实现链路极简,维护成本也大幅降低。
查询分析性能: Apache Doris 是 MPP 架构,支持大表分布式 Join,其倒排索引、物化视图、行列混存等功能使查询分析性能更加高效极速。
数据仓库架构 3.0
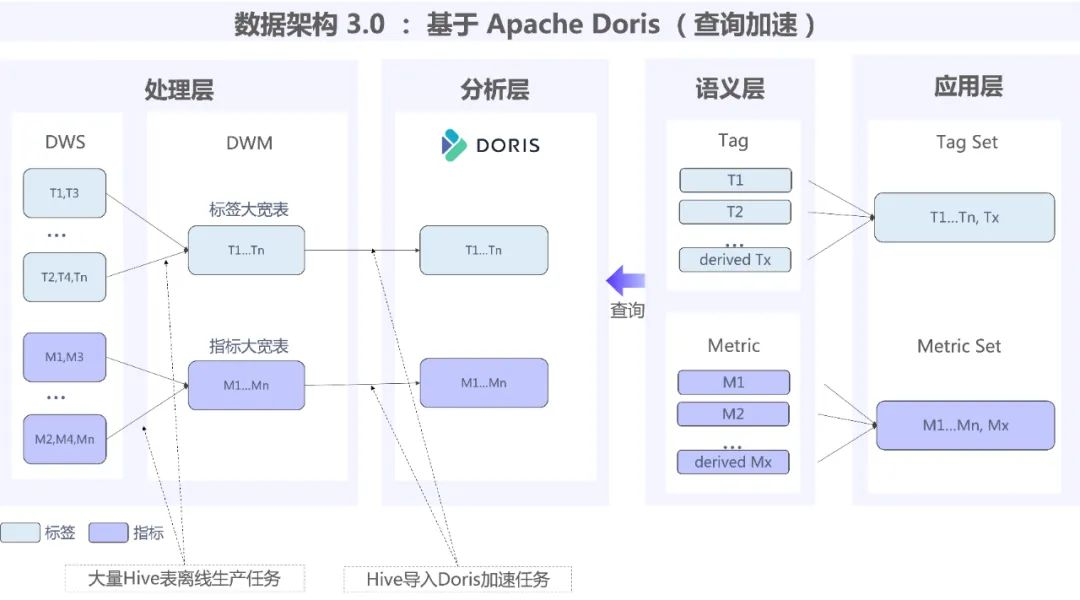
为了进一步提升架构性能,数据架构 3.0 主要将处理层中大宽表进行拆分,同时将分析层统一使用 Apache Doris 作为查询分析引擎。
数据仓库架构 4.0
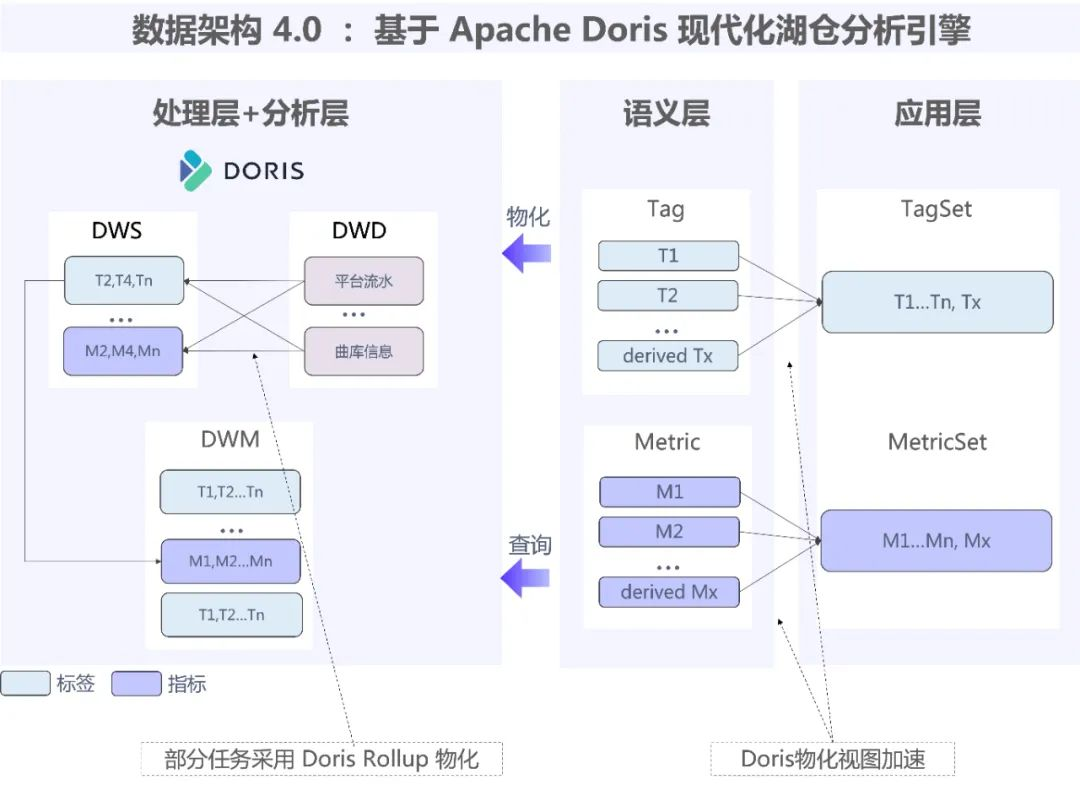
4.0主要是对处理层、分析层、语义层架构进一步优化,使查询性能显著提升:
分析层 + 处理层:数仓 DWD 层数据采用 Rollup 功能使事实表与维度表实时关联并创建多个视图进入 DWS 中。通过这种方式,分析层与处理层中的各类指标数据无需再重复定义,能够基于 Apache Doris 全部写入新建的 Rollup 视图中并利用GROUP BY将维度传入视图进行查询加速,直接对外暴露所需数据。
语义层:利用 Apache Doris 物化视图对指标与维度自定义口径,通过语义物化层进行查询加速,并将指标与维度通过 SUM 加工开发衍生标签与维度数据。
应用层:利用 Apache Doris 2.0 版本的倒排索引功能,对现有的索引结构进行丰富,满足了对知识库进行模糊查询、等值查询和范围查询等场景中的能力,进一步加速指标、维度查询响应速度。
数据仓库架构升级效益总结:
数仓架构基于 Apache Doris 迭代升级,最终实现导入实时、引擎统一、查询高效的现代化湖仓 OLAP 引擎,简化架构链路的同时,有效解决大宽表中指标重复定义所带来的问题。
在引入 Apache Doris 后,数据架构围绕降本增效的目标,不仅在写查方面的性能得到大幅度提升,并且有效减少架构成本与资源开销,具体的收益如下:
1、极速查询分析: 通过 Apache Doris 的 Rollup、物化视图、倒排索引功能,由原来的分钟级查询时间达到现如今秒级毫秒级;
2、导入性能提升: 导入优化完成后,原本 3000+ 维度、指标数据的导入时间需要超过一天,现如今能够在 8 小时内完成导入,导入时间缩短至原来的 1/3,实现快速导入需求;更重要的是,Apache Doris 在保证数据快写入的同时,使数据能够不丢不重、准确写入;
3、链路极简与统一: Apache Doris 将查询与分析出口引擎统一,去除 Elasticsearch 集群使架构链路极简;
4、存储成本降低: 通过大宽表拆分的方式,使存储成本降低 30%,开发成本降低 40% 。
如果对于您公司的业务以及状况遇到了类似的情况,您可以考虑来找我们(SelectDB 是基于 Apache Doris 构建的商业化公司)帮您解决!另外想要了解更多的相关解决方案,你可以点击查看更多案例!
