一些热门平台和 APP (抖音、今日头条、小红书、知乎等)都会用到搜索引擎,信息检索成为我们日常生活和工作中不可或缺的一部分。无论是搜索引擎的即时响应,还是企业内部的数据分析,都离不开高效的索引技术。其中,倒排索引(Inverted Index)作为一种经典的索引方法,以其卓越的性能和广泛的应用,成为文档检索系统中的核心数据结构。
一、倒排索引的定义
倒排索引,也常被称为反向索引、置入档案或反向档案,是一种用于存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射方法。与传统的正向索引(即按照文档顺序存储单词)不同,倒排索引的核心思想是将文档中的每个词汇映射到包含该词汇的文档列表中,从而建立词汇与文档之间的关联关系。这种索引方法使得我们可以根据关键词快速定位到包含该关键词的所有文档,极大地提高了信息检索的效率。
二、倒排索引的核心算法
倒排索引的构建和查询过程涉及多个核心算法,以下是其中的几个关键部分:
1、分词与索引构建
倒排索引的构建始于对文档的分词处理。系统首先会将文档分割成一系列的词汇单元(通常称为词项),然后对每个词项进行索引构建。索引构建过程中,系统会为每个词项创建一个倒排列表,该列表包含了所有包含该词项的文档ID以及该词项在文档中的位置信息。
2、词典与倒排文件
倒排索引主要由两部分组成:词典(Dictionary)和倒排文件(Inverted File)。词典用于存储所有唯一的词项及其对应的倒排列表在倒排文件中的位置。倒排文件则存储了具体的倒排列表信息,包括文档ID、词项在文档中的位置等。通过词典和倒排文件的配合,系统可以快速定位到查询词项对应的文档列表。
3、压缩与优化算法
为了减小索引文件的体积并提高查询效率,倒排索引通常会采用多种压缩和优化算法。例如,可以使用Frame Of Reference(FOR)和RoaringBitmap(RBM)等算法对倒排列表进行压缩;使用Finite State Transducers(FST)等数据结构来优化词典的查询性能。这些算法和数据结构的运用,使得倒排索引在保持高效检索性能的同时,能够显著减小存储空间的需求。
4、查询处理
当用户输入查询关键词时,系统首先会在词典中查找该词项对应的倒排列表位置。然后,根据位置信息在倒排文件中读取相应的倒排列表,并根据查询需求对列表中的文档进行排序和过滤。最后,将处理结果返回给用户。查询处理过程中,系统还会利用词项频率(TF)、文档频率(DF)等统计信息来评估文档与查询的相关性,从而提供更准确的查询结果。
三、SelectDB 倒排索引的应用案例分享
通过 SelectDB 的倒排索引能力使得存储空间节约超 80% 、写入速度是 Elasticsearch 的 5 倍、查询性能是 Elasticsearch 的 2.3 倍
**导读:**为更好提供整体数据的分析、洞察、可视化、自动化、监测告警、智能巡查、安全巡查等服务,要求观测云具备对基础对象、网络性能、日志、应用性能、用户体验、可用性甚至 CI 进行观测的能力。这些能力要求观测云能够统一整合来自多个场景和多种结构的海量数据,并提供全面的日志检索分析能力,快速实现数据查询、筛选和分析。
为解决观测云在日志存储和分析场景所面临的挑战,飞轮科技与观测云进行了全面合作。通过 SelectDB 的倒排索引能力使得存储空间节约超 80% 、写入速度是 Elasticsearch 的 5 倍、查询性能是 Elasticsearch 的 2.3 倍。
GuanceDB 原有架构
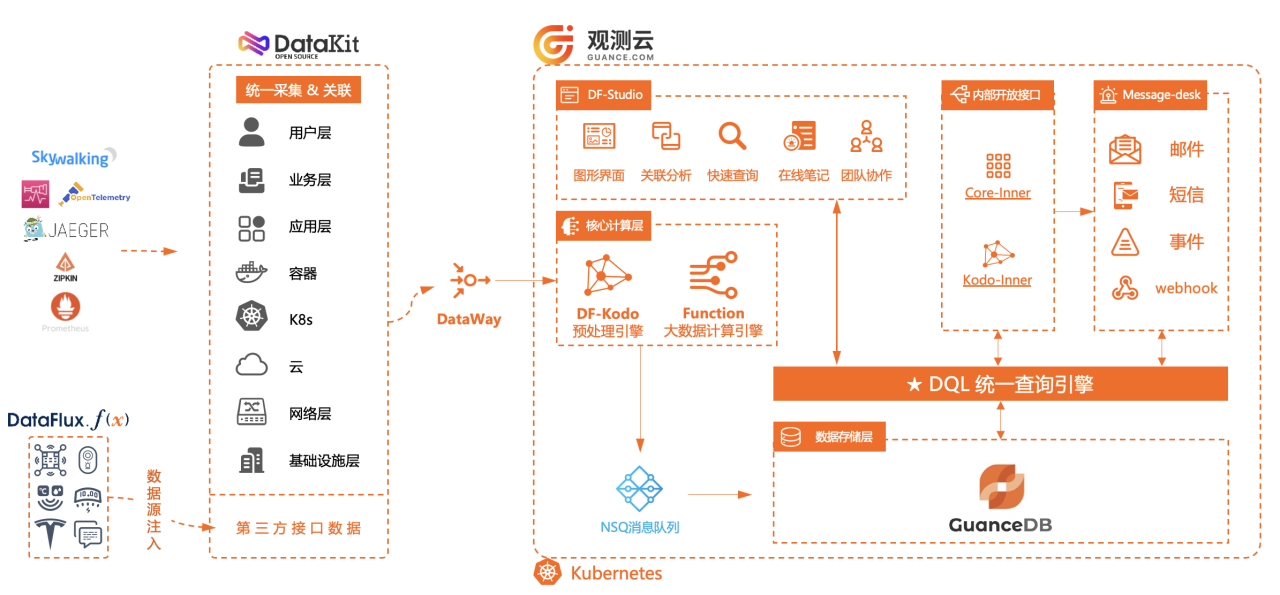
在全文倒排索引方面,希望以下问题被解决:
全文倒排索引能够显著提升检索性能并降低查询的资源开销,是实现高效日志分析的必备能力。在调研中,观测云也注意到了像 Loki 这样的无索引方案, 这类方案虽然简单,但当请求 QPS 稍高时,全盘扫描时磁盘 IO 和 CPU 资源开销争抢就会非常激烈,无法承载日志图表展示、聚类筛选分析、实时告警等业务需求。
基于 SelectDB 的存储架构升级
在可观测性场景中,几乎所有的查询都涉及时间的筛选,同时大部分的聚合也需要按照时间窗口来进行,并且针对时间序列,还需要支持按单个序列在时间窗口前后进行 Rollup。在这些场景中,使用 SQL 来表达相同的语义就需要嵌套多层子查询,导致表达过程和编写都异常复杂。
因此我们尝试简化语法元素,在此基础上设计出了新的查询语言 DQL,并且增强了在可观测场景下的常见计算函数,通过 DQL 即可查询指标、日志、链路追踪、对象等所有的可观测数据。
从 GuanceDB 内部结构来看,本次升级我们使用 SelectDB 替换了 Elasticsearch/OpenSearch,原有的查询架构保持不变。
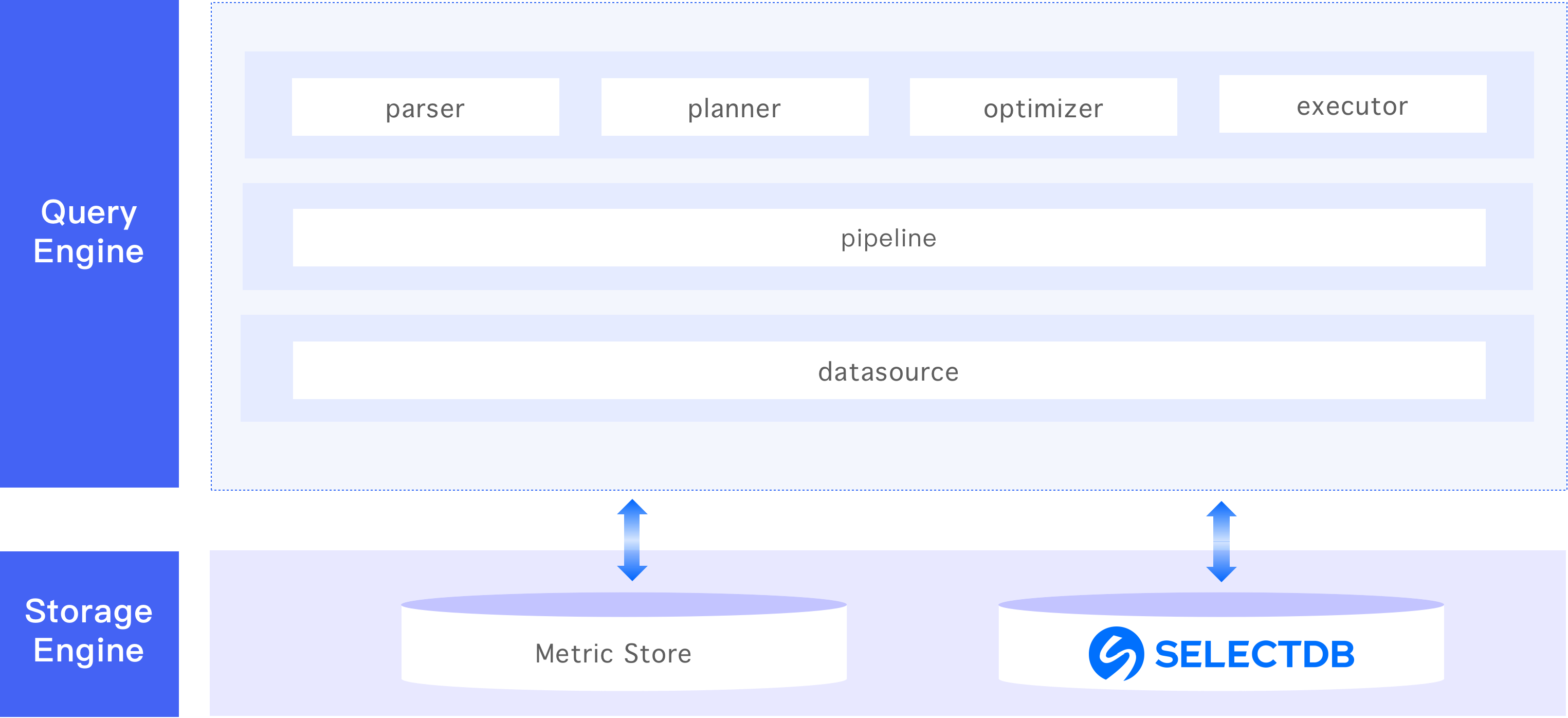
接下来我们介绍在引入 SelectDB 之后,DQL 查询是如何工作的:
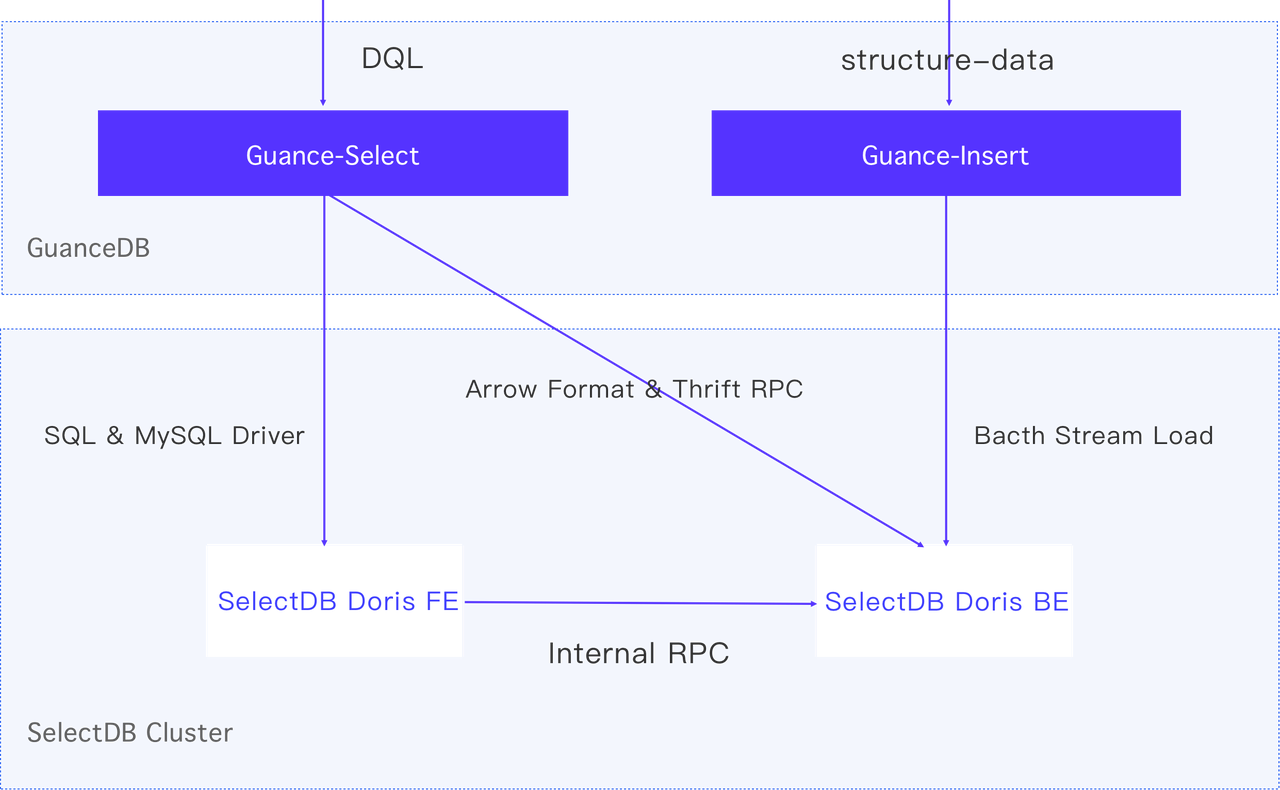
如上图所示,Guance-Insert 是数据写入组件,Guance-Select 是 DQL 查询引擎。
在 Guance-Insert 中,实现了分租户的数据攒批逻辑,均衡了写入吞吐量和写入延迟两大指标,尽量高效地将数据通过 Stream Load 接口写给 SelectDB Doris BE 组件。当海量日志产生时,该方式攒批速度很快,平均日志入库延迟在 2-3 秒;
在 Guance-Select 中, Guance-Select 会根据当前查询 SelectDB 的 SQL 支持情况,选择是否将查询下推给 FE 计算。通常情况下,常见的聚合查询都可以下推给 FE 计算,但当遇到 FE 不支持的 SQL 语义或函数时,我们就会选择 Fallback 到仅下推谓词到 BE,通过 Thrift RPC 接口获取 Arrow 格式的列存数据,再在 Guance-Select 中计算。由于此方案无法将计算逻辑下推 BE ,因此实际性能会略差于在 FE 中的查询。不过在大部分场景下,这种方案是可以满足需求的。
当前的查询架构是综合 FE 和 BE 能力的混合计算架构,DQL 即可以利用 SelectDB 已经充分优化的查询能力,也可以让语法拓展不受 SelectDB 本身 SQL 能力的限制。
架构升级的收益:倒排索引满足日志场景全文检索需求
倒排索引能够显著提升全文检索的性能并降低查询的资源开销,是实现高效日志分析的必备能力。SelectDB 支持倒排索引,以下是我们从 Elasticsearch 迁移到 SelectDB 过程中关键能力的介绍:
支持字符串全文检索,包括可同时匹配多个关键字 MATCH_ALL、匹配任意一个关键字 MATCH_ANY 、匹配短语词组 MATCH_PHRASE 的查询方式。我们对日志文本内容创建倒排索引时使用 MATCH_PHRASE 进行查询,能够完整覆盖原来在 Elasticsearch 上的功能;
支持英文、中文及 Unicode 多语言分词,中文分词还支持自定义词库、自定义停用词。我们将原先在 Elasticsearch 上使用的中文词库和停用词配置到 SelectDB 上,完成了用户体验平滑迁移。
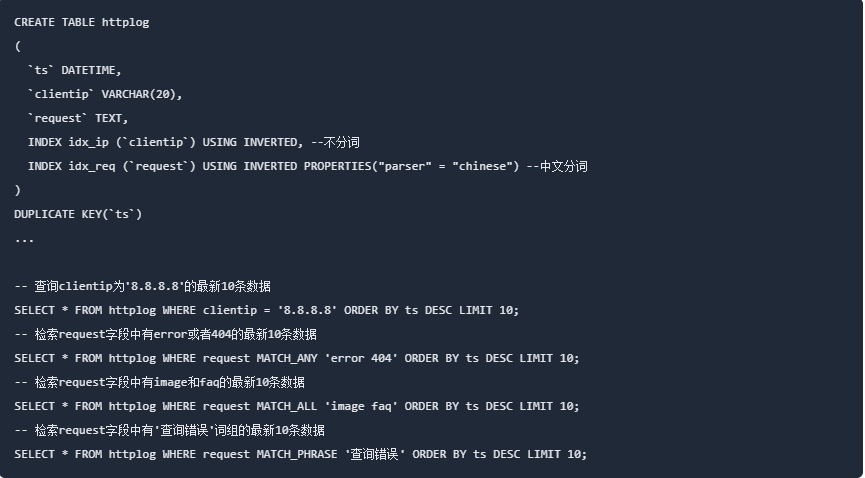
除了在功能上能够满足日志全文检索的需求,SelectDB 倒排索引还支持在线按需增减索引。Elasticsearch 索引在创建时是固定的,后续无法新增索引字段,这就需要提前规划哪些字段需要建立索引,后续如需变更索引则需要重写,变更成本非常高。SelectDB 支持在运行过程中按需增加索引,新写入的数据索引立即生效。同时 SelectDB 可以控制对哪些分区创建索引,使用起来非常灵活。
