
在前一篇文章 Litefuse 正式发布:Agent 可观测与效果评估, 比 Langfuse 成本低 88% 中,我们介绍了为什么 Agent 时代需要新的方法论 EDD(Evaluation Driven Development),通过 “观测-评估-优化” 闭环来应对大模型幻觉、路径规划走偏、工具调用失败、上下文腐化等 Agent 特有的不确定性问题,Litefuse 如何把 Trace 采集、可视化分析、数据集管理、实验运行与评估这一整套实践 EDD 方法论的能力产品化。
在过去一个月中,Litefuse SaaS 服务 litefuse.cloud 受到了很多 Agent 开发者欢迎,注册用户超过 200 人,Litefuse 被应用到 Agent 评估优化、大模型网关观测与成本分析、RAG Pipeline 调优等场景中。
今天,我们将 Litefuse 开源,并推出业界第一个极致轻量的单机单进程模式。如果你已经迫不及待想要尝试,运行下面一条命令,大约 25 秒就能完成 Litefuse 单机版下载、安装和部署。
curl -fsSL https://litefuse.ai/install.sh | sh
为什么要做单机版
相信大家在体验 Agent 可观测平台的时候都有类似的经历,在私有化环境中基本上所有产品都需要用 Docker 来启动,看起来很简单实际却很麻烦,如果没有现成的 Docker 环境要先下载安装 Docker,然后拉取对应产品的 Docker image 一般都是几个 GB,默认从 docker hub 下载就得按小时计,想办法配置好国内镜像站点然后再下载也得好几分钟,起来之后发现好家伙一堆容器,看着就很笨重。
这还只是第一次体验,后续的维护更是问题,数据都存在哪里,端口怎可开映射,等等一系列 Docker 和多进程的问题接踵而至。而如果你要把这个套系统部署在你的用户或者客户环境中,笨重的代价则更加明显,用户可能没有 Docker 环境、网络可能是隔离的没法拉取镜像等等。
有些场景中用户只需要一个单机就能跑的系统,却不得不与 Docker 和 5-6 个进程打交道,复杂度甚至比被观测的系统还高。
这就是 Litefuse 推出一个极致轻量的单进程模式的原因,在单机场景下,让用户用最简单的方式把 Agent 可观测与评估跑起来。
下面这个视频中,左边 Litefuse 单进程版本只用 curl 和 sh 命令、25 秒从零开始已完成部署(12 秒下载完 358MB 安装包、11 秒解压安装),而右边 Langfuse 基于 Docker 花了 2 分 18 秒,慢了 5.5 倍,这还是在提前准备好 Docker 环境、配置好国内镜像的前提下,否则会慢几十倍。
点击观看:litefuse_install_demo3.mp4
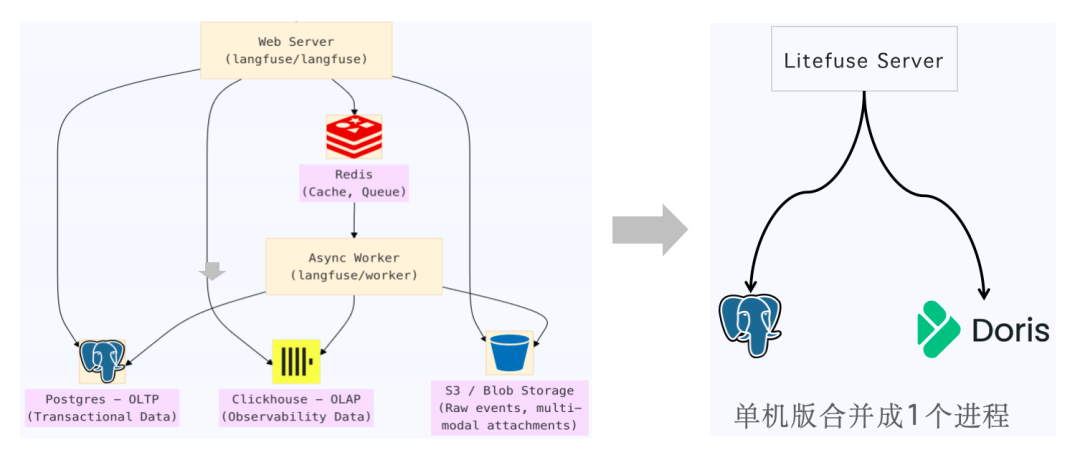
Litefuse 单进程版支持 macOS (Apple silicon) 和 Linux (x64) ,它的架构和特点如下:
一个二进制包,体积不到 400MB,里面包括了 Litefuse 本身的程序、Node.js 和 JVM 运行时环境,PGlite 嵌入式 Postgres,DorisLite 嵌入式 Doris 。
没有其他运行时依赖,只依赖内置的 Node.js 和 JVM 运行时,无需外部依赖,无需 Docker 环境。
运行起来只有一个进程,数据库 PGlite 和 DorisLite 以库的方式加载而不需要额外的进程。
为什么选择 Apache Doris 作为存储分析引擎
Agent 可观测的核心数据也是 Trace,那它与传统可观测到底有什么区别?本质的区别是几个量变引起了质变:
MB 长文本:Agent 依赖的 LLM 能生成长文本,特别是最新的模型支持百万 token 上下文,一次请求的输入和输出可能有 MB 级别的长文本,传统可观测中一般只有百字节或者 KB 级别的文本。长文本一方面检索 Trace 带来了很大挑战,用户反馈问题时很可能没有 Trace ID 只有一个截图,需要根据截图中的关键字到可观测系统中搜索对应的 Trace,文本越长传统的 LIKE 等字符串硬匹配就越慢。另一方面,长文本给查询时的内存消耗带来挑战,10000 行 MB 级别的长文本全部加载到内存就需要 10GB,Agent Trace 分析时涉及的数据行数还不止这么多。
跨度几天、GB 大小的超长 Trace:复杂的 Agent 任务可能会运行数小时甚至数天,由几百甚至几万个步骤组成,一个步骤产生一个 Span,由于上面的长文本原因可能高达 MB,一个 Trace 可能有几万个 Span 加起来高达几百 MB 甚至 GB。这个特点导致了分析 Agent 轨迹时,获取一个 Trace 的所有 Span 很慢,因为需要从很多文件中读取相关的 Span。
大量半结构化数据:传统的 Trace 中灵活的半结构化数据如 JSON 一般用于元数据,而 Agent Trace 中不仅元数据中有 JSON,主数据如 input output 中也有大量 JSON,这是因为 Agent 和大模型的输入输出大多都是 JSON 格式。这个变化导致了如果没有对半结构化 JSON 的 Native 支持和优化,Trace 分析将会很慢,因为读取和解析 JSON 是很消耗资源的。
数据量提升一个量级:由于单个 Span 变大、一个 Trace 中的 Span 变多,数据总量也有数量级的变化,这就带来存储成本的大幅增加。
过去几年我们在与 MiniMax、阶跃星辰等大模型公司构建可观测系统的过程中,不断探索和扩展 Doris 的能力边界,现在发现正好匹配上了 Agent 可观测的技术挑战。
1、成熟的倒排索引加速全文检索 10x
Apache Doris 早在 2023 年开始支持了倒排索引,被 MiniMax、阶跃星辰、字节、快手、腾讯、阿里、百度、网易等数百家公司大规模应用于生产环境。
功能方面不仅支持基础的关键词检索 MATCH,还支持多关键词检索 MATCH_ALL、短语检索 MATCH_PHRASE、前缀检索 MATCH_PHRASE_PREFIX、短语词距 SLOP、正则检索 MATCH_REGEXP、多字段检索 MULTI_MATCH 等。支持英文、中文、中英文混合 IK、UNICODE ICU 等多语言分词器。支持 BM25 相关性打分和排序,支持 SQL 和 Lucene 风格的两种检索方式。在性能方面,Doris 倒排索引支持 PB 级别存储、百 GB/s 实时写入、秒级检索。
经过多年生产环境的打磨和验证,Doris 倒排索引能够轻松应对 Agent 可观测中的长文本检索挑战。
2、延迟物化等解决降低长文本查询时内存占用
在 MiniMax、阶跃星辰等可观测场景中,已经遇到过 MB 甚至百 MB 的长文本,Doris 在存储、检索、查询等环节为长文本进行了大量优化。比如可观测场景中常见的 TOPN 查询,按照日志的时间排序取最新 N 条,Doris 的延迟物化技术在排序阶段只读取时间字段、获取最终 N 条数据时才读取完整的数据,避免了大量的 IO、CPU、内存资源消耗,查询响应快且稳定。
3、分桶、排序、索引机制将 Trace 聚簇存储解决超长 Trace 分析问题
Apache Doris 最初就为面向用户的实时分析设计了分区分桶、数据排序等机制,将数据按照 user id hash 分桶分散到不同的服务器,数据文件内部再按照 user id 排序,让一个用户的数据尽量存储在一个服务器、数据文件相邻的区域,用户查询时它的数据局部性很好、很快得到满足,而且全局的并发很高。
对应到 Agent 可观测领域,这套机制正好可以用于优化基于超长 Trace。将 trace 数据按照 trace id hash 分桶分散到不同的服务器,数据文件内部再按照 trace id 排序,并对 trace id 建立前缀索引。Agent 轨迹分析时,获取一个超长 Trace 的所有数据,不用在很多分散的服务器和文件中读取数据,而是很快找到对应 hash 的服务器,在数据文件中定位到 trace id 的范围,通过范围 scan 就能快速拿到结果。
4、VARIANT 数据类型 Native 支持和优化半结构化 JSON 数据存储分析
Apache Doris 为半结构化 JSON 数据设计了一个专用的数据类型 VARIANT。VARIANT 在写入时自动识别 JSON 数据中的字段名和类型,将它们拆分成子列,采用列式存储。这种机制一方面提升压缩率降低存储空间,另一方面查询时只需读取相关字段的子列,大幅降低读取的数据量,而且不需要耗时的 JSON 解析过程,查询速度通常能提升 10 倍。
对于 Agent 可观测中 input output 字段大量的 JSON 数据,VARIANT 的效果更加明显,因为 input output 比 metadata 更长,采用行存还是列存的差别更大。
5、存算分离架构、列式存储降低存储空间和成本 75% ~ 80% 以上
Apache Doris 在过去几年做了很多优化来降低存储空间和成本。列式存储、ZSTD 压缩可以降低存储空间,同样的数据使用更少的存储空间。存算分离架构不需要在本地磁盘存储多个副本,而是将数据存储在对象存储中,只需要存储 1 份而不是 2-3 份,存储空间降低 50% 以上,同时由于对象存储成本仅为本地磁盘的 25% ~ 50%,整体成本则降低 75% 到 88%。同时,存算分离架构也会降低数据写入的成本,因为数据只写 1 份,不需要多个副本同时消耗计算和 IO 资源。
值得注意的是,Langfuse 背后的 Clickhouse 开源版本是不支持存算分离架构的,用户需要用本地磁盘多副本来保证可靠性,代价是多份的存储成本。而 Apache Doris 开源就支持存算分离架构,用户可以免费享受到 75% 到 88% 的成本降低。
现在就加入社区
基于上面的一些原因,Litefuse 基于 Langfuse 和 Apache Doris 构建,在 Langfuse 丰富的功能基础之上,利用 Doris 优化存储成本和分析性能,并推出极简的单进程模式简化架构和维护成本。
Litefuse 已经在 GitHub 开源,采用非常宽松的 MIT 协议,如果觉得这个项目有价值,欢迎给我们一个 Star:
在你自己的 macOS (Apple Silicon) 或 Linux (x64) 服务器上,一行命令、约 25 秒即可跑起来:
curl -fsSL https://litefuse.ai/install.sh | sh
如果你不想自己部署,也可以直接使用云端服务:
- SaaS:https://litefuse.cloud ,提供免费额度,注册即用;
- 阿里云 SelectDB https://www.aliyun.com/product/selectdb:可开启独享的 Litefuse 实例 https://help.aliyun.com/zh/selectdb/enable-datalens-ai。
Litefuse 开源只是一个新的起点,接下来 Litefuse 一方面会继续在架构层面发力进一步提升性能和降低成本,另一方面会在 Agent 评估层面增强产品能力,帮助开发者更高效评估和迭代 Agent。
Agent 的发展日新月异,未来肯定还会面临新的挑战和机遇,欢迎加入 Litefuse 社区,和我们以及其他 Agent 开发者一起交流和共建 Agent 可观测与评估,打造可靠、可持续优化的 AI Agent。



