
摘要:针对大模型应用中专用向量库成本高、混合查询难的痛点,本文深入拆解 Apache Doris 4.1 原生向量检索的工程实践。从 IVF 算法降本、存储分层,到突破性能瓶颈的 ANN Index Only Scan,系统化解决 AI 时代的海量数据存算难题。在大幅压低内存开销的同时,跑出了 900 QPS 与 97% 召回率的亮眼成绩。
随着大语言模型(LLM)应用与 RAG(检索增强生成)逐步深入,开发者意识到:把向量存下来并搜出来并不难,难的是如何控制 TB 级数据的内存成本,以及如何让向量与现有的结构化业务数据无缝联动。
在这背景下, ANN 向量检索不再是新奇设计,而是与过滤、连接、聚合一样,成为数据系统的基础能力。那么,向量索引应当被部署到哪里?需要多少成本来实现?
当前,行业里主要存在三条实现路径。本文将从这三条路径出发,聊聊为什么 Apache Doris 及其商业化引擎 SelectDB 选择了原生集成这条路,以及它在工程层面到底做了哪些事情。
- 专用向量数据库(Milvus、Qdrant、Pinecone)从底层围绕 ANN 构建,针对纯向量检索深度优化。代价是它会成为现有数据栈之外的独立系统,应用层需要自行处理数据一致性、联合查询及跨系统运维。
- 关系型数据库扩展 (pgvector、MySQL HeatWave Vector)嵌入事务数据库内部,部署门槛低。但底层存储和索引并非为大规模向量负载设计,扩展性与并发能力很快会触及天花板。
- 分析型数据库原生支持(Elasticsearch Dense Vector、ClickHouse ANN、Apache Doris 向量索引)直接复用 OLAP 引擎已有的列式存储、分布式执行和向量化计算能力,天然适合向量与结构化过滤相结合的混合查询。工程难点在于将 ANN 与执行引擎深度融合,而非仅停留在功能可用的层面。
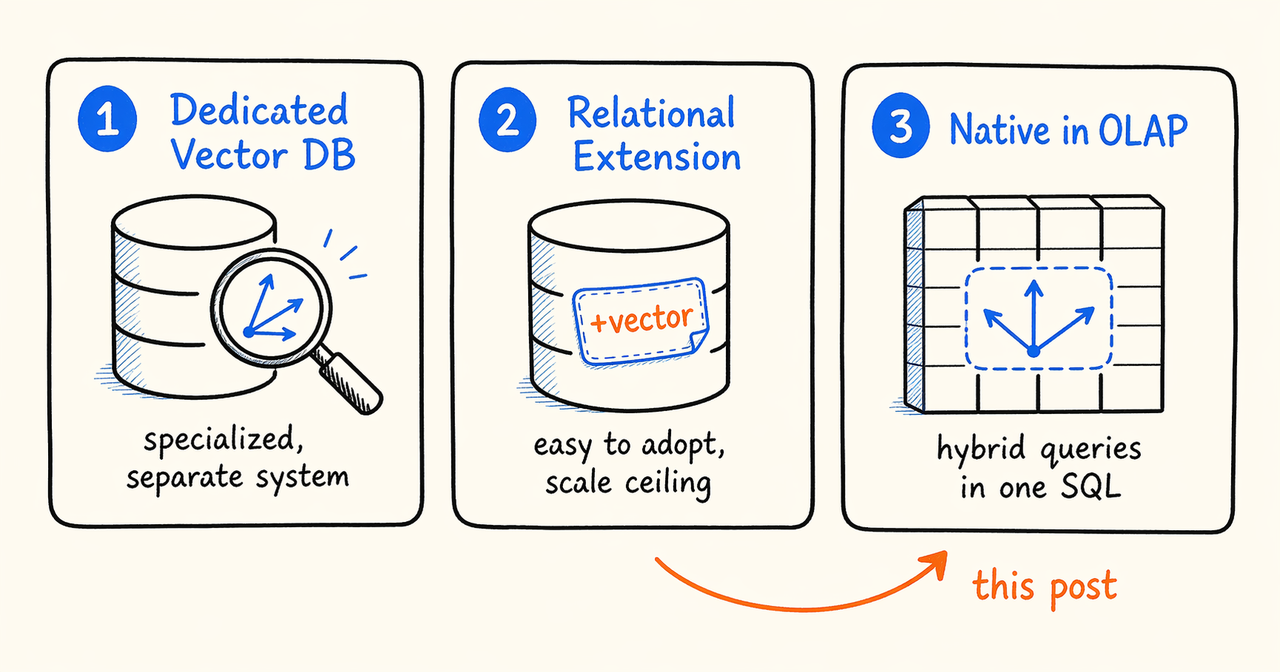
本文重点讨论的,正是 Apache Doris 4.1 在第三条路径上的工程实践。
成本是第一工程问题
IVF:比 HNSW 更低内存占用、查询更快
向量检索的内存消耗并非仅来自向量本身。
以 100 万个 768 维 float32 向量为例,原始数据约 3 GB(1,000,000 × 768 × 4)。
而 ANN 索引还会额外占用大量内存。主流算法 HNSW(分层可导航小世界)采用分层图结构,能在对数级复杂度下实现高召回率,适合中小规模场景,但它的图结构必须常驻内存。在常用参数(M=16,efConstruction=200)下,索引内存约为原始数据的 2 倍。若扩展到 10 亿向量,内存占用将接近 1 TB。系统虽能运行,但如此高的部署成本,大多数团队难以接受。
当 HNSW 的内存成本变得不可接受,行业通常转向 IVF(Inverted File Index)。
IVF 的核心思想很直观:构建阶段先对所有向量做 K-Means 聚类,生成 nlist 个中心点,每个向量归到最近的簇,相当于把整个向量空间划分成很多"桶";查询阶段先找到最接近查询向量的几个桶(由 nprobe 控制),只在这些桶里计算距离,从而避免全局扫描。
代价是召回率会略有下降,但查询速度和内存占用都能大幅改善。更关键的是,IVF 不需要把完整的图结构常驻内存,这为后续的磁盘分层打下了基础。
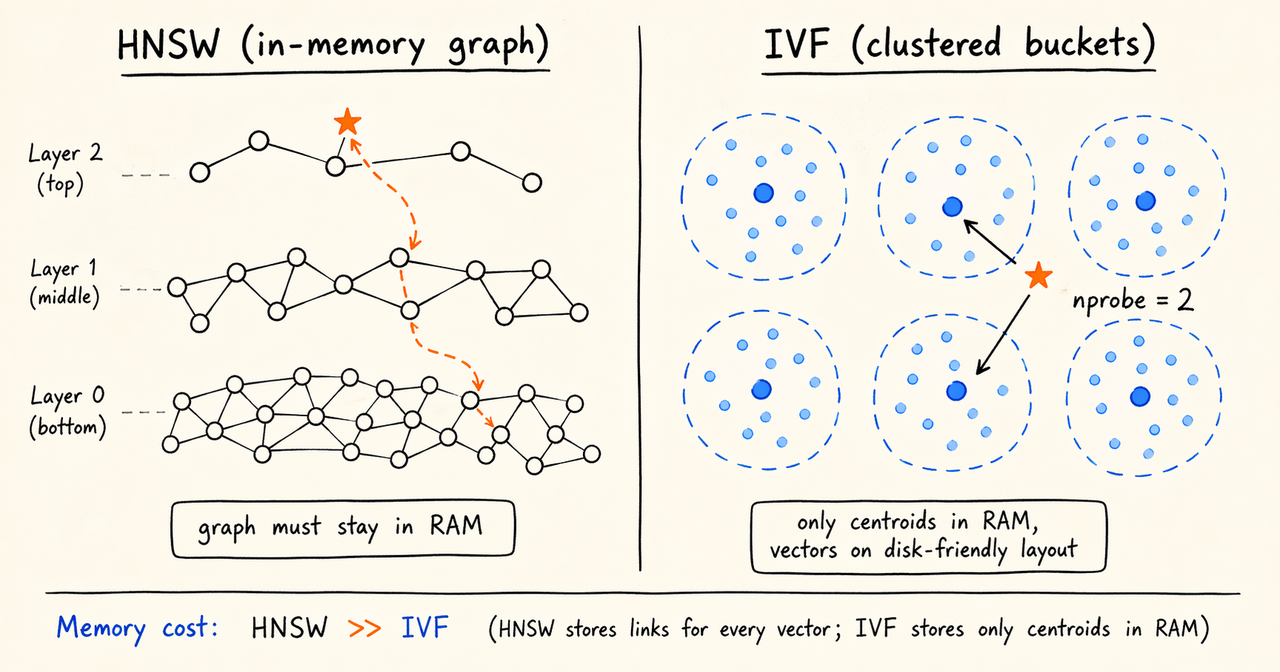
Apache Doris 在 4.0 版本引入了 HNSW,4.1 版本新增了 IVF,用于支撑更大规模的数据集。DDL 如下:
CREATE TABLE vecs (
id BIGINT NOT NULL,
embedding ARRAY<FLOAT> NOT NULL,
INDEX idx_emb (embedding) USING ANN PROPERTIES (
"index_type" = "ivf",
"metric_type" = "l2_distance",
"dim" = "768",
"nlist" = "1024"
)
) ENGINE=OLAP
DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 8
PROPERTIES ("replication_num" = "1");
其中 nlist 是聚类桶数量,nprobe 是查询时扫描的桶数,且 nprobe 可以动态调整,同一套索引就能在召回率和延迟之间实时平衡。
IVF_ON_DISK:冷热分层存储降低成本
即使 IVF 大幅降低了索引开销,向量数据本身的体积仍然会线性增长。10 亿个 768 维 float32 向量约 3TB,仅向量数据就已经是 TB 级。
行业对此的标准答案是存储分层:热桶放内存、冷桶放磁盘、内存只保留导航结构。微软的 DiskANN(NeurIPS 2019)和 SPANN(NeurIPS 2021)都是这一方向的代表性工作。
Doris 4.1 的 IVF_ON_DISK 基本遵循 SPANN 的设计思路。内存中保存聚类中心和热数据缓存,磁盘中保存倒排列表和向量数据。查询时热数据直接命中缓存,冷数据按需从 SSD 读取,从而在普通商用机器上支持十亿级向量检索。
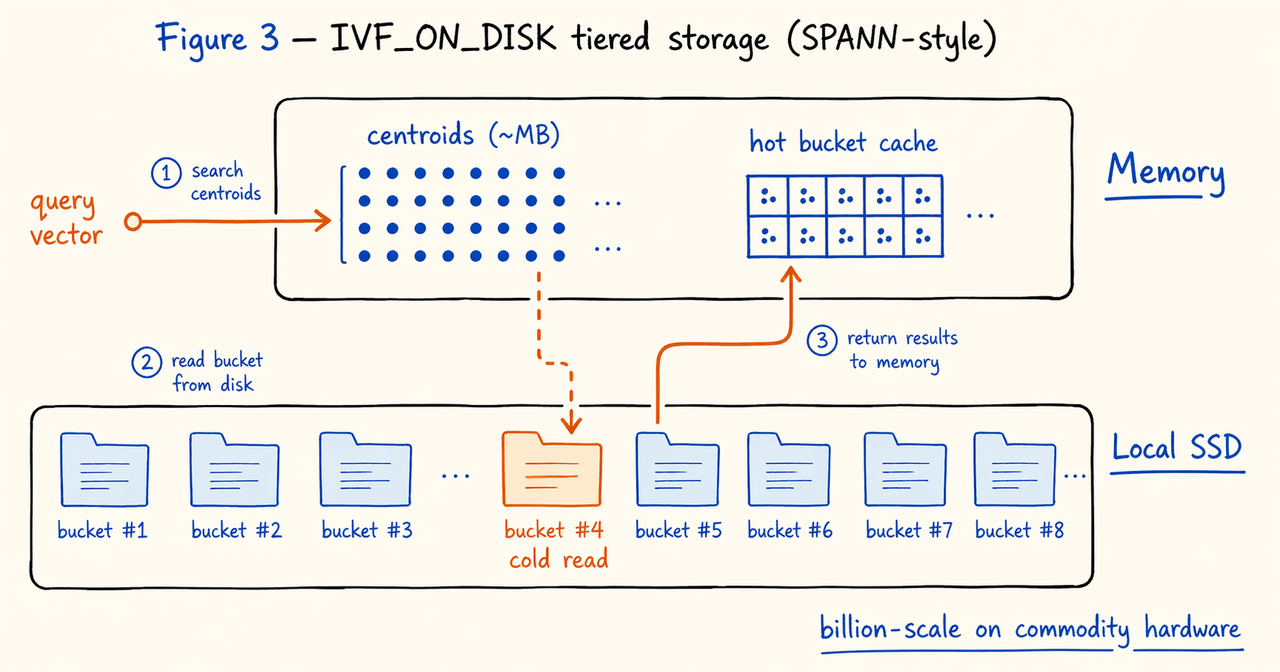
DDL 本质上与普通 IVF 相同,只是索引类型不同。其中nlist通常会随着数据集的增大而增大,以控制平均桶的大小。
CREATE TABLE vecs_large (
id BIGINT NOT NULL,
embedding ARRAY<FLOAT> NOT NULL,
INDEX idx_emb (embedding) USING ANN PROPERTIES (
"index_type" = "ivf_on_disk",
"metric_type" = "l2_distance",
"dim" = "768",
"nlist" = "4096"
)
) ENGINE=OLAP
DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 32
PROPERTIES ("replication_num" = "1");
听起来,磁盘索引似乎要比内存索引慢得多。实则并非如此,向量查询具有明显的局部性,相邻查询往往命中相同的簇,热点数据的缓存命中率很高,实际 I/O 远低于全量扫描。在合理的缓存策略下,IVF_ON_DISK 的 QPS 可以非常接近纯内存 IVF。
量化手段:压缩向量本身进一步降低成本
存储分层核心是以磁盘容量换取内存预算,总资源使用有效减少,但向量本身依旧很大。因此,需要通过向量量化进一步压缩向量本身。
常见的做法有两种:
- 标量量化 SQ(Scalar Quantization),把 float32 转成 int8 或 int4,压缩率分别约 4 倍和 8 倍,实现简单;
- 乘积量化 PQ(Product Quantization),将向量切成多个子向量分别聚类编码,最终只存编码 ID,压缩率非常高且可调节,这也是 PQ 常见于大模型向量检索系统中的主要原因。
Doris 4.1 支持以上所有类型,并允许将他们构建于 IVF_ON_DISK 之上 。本文主要展示 PQ,配置示例如下:
CREATE TABLE vecs_pq (
id BIGINT NOT NULL,
embedding ARRAY<FLOAT> NOT NULL,
INDEX idx_emb (embedding) USING ANN PROPERTIES (
"index_type" = "ivf_on_disk",
"metric_type" = "l2_distance",
"dim" = "768",
"nlist" = "4096",
"quantizer" = "pq",
"pq_m" = "64",
"pq_nbits" = "8"
)
) ENGINE=OLAP
DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 32
PROPERTIES ("replication_num" = "1");
对于 768 维向量,原始大小 3072 字节,PQ 压缩后约 64 字节,压缩比接近 48 倍。

查询性能更不可忽视
存储分层和量化技术解决了空间与成本问题,但在实际生产环境中,查询性能往往更不可忽视。在实现了低成本存储之后,如何进一步优化检索速度、提升系统吞吐,是另一个需要攻克的瓶颈。
ANN Index Only Scan:900 QPS、97% 召回率
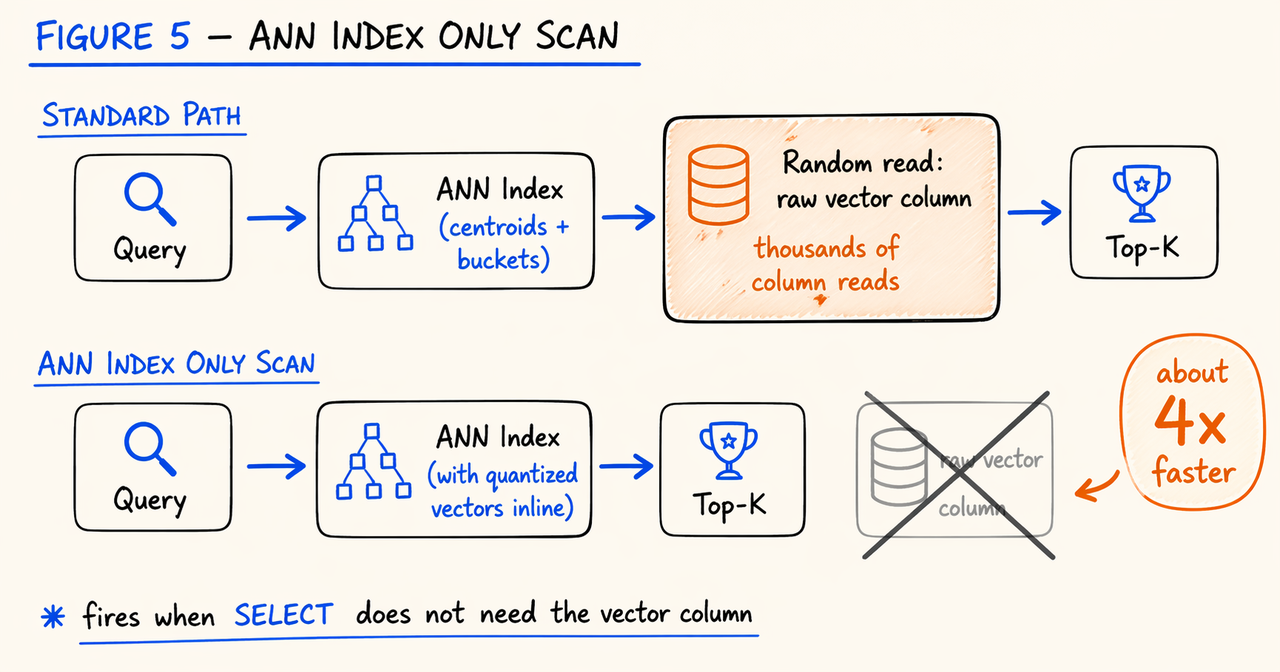
ANN 查询真正的性能瓶颈,往往不在选桶和排序,而在于读取原始向量列。在列式数据库中,这本质上是随机 I/O。
Doris 4.1 对此的优化思路类似关系数据库的覆盖索引,如果查询只需要 ID 和距离值,就不必回表读取原始向量,直接利用索引中的向量或量化向量完成距离计算即可。
这就是 Doris 4.1 引入的 ANN Index Only Scan。在官方测试中(100 万向量、768 维、TopK-10 近邻查询),这一优化最终达到 900 QPS、97% 召回率,整体性能相比 Standard Path 提升约 4 倍。
混合检索:向量检索与其他检索结合
解决了底层存储和单列检索的成本与性能问题后,应用层面临的最大挑战往往是复杂的真实查询场景。纯向量检索在实际生产中很少单独出现。大多数场景会在向量相似度之上叠加其他检索维度,主要有两种模式:
- 结构化过滤联合查询。向量相似度与类别、价格、时间、权限等布尔或范围条件结合使用。典型场景包括电商的相似商品推荐、内容平台的关联推荐,以及 RAG 中按租户或时间窗口切片检索。
- 多路召回融合排序。向量召回与 BM25 文本搜索、行为召回、规则召回等通道联合排序。典型场景包括搜索引擎的混合检索,以及 RAG 管道中的检索质量优化。
结构化过滤联合查询
专用向量数据库在处理这类查询时通常有两种做法,但都不理想:后过滤(先向量召回再过滤)可能导致过滤后结果数量不够(如果过滤器通过率为 30%,实际返回的只有K × 30%行);前过滤(先过滤再向量检索)会让 ANN 索引结构失效,退化为暴力扫描,延迟也会随候选集大小线性增长。
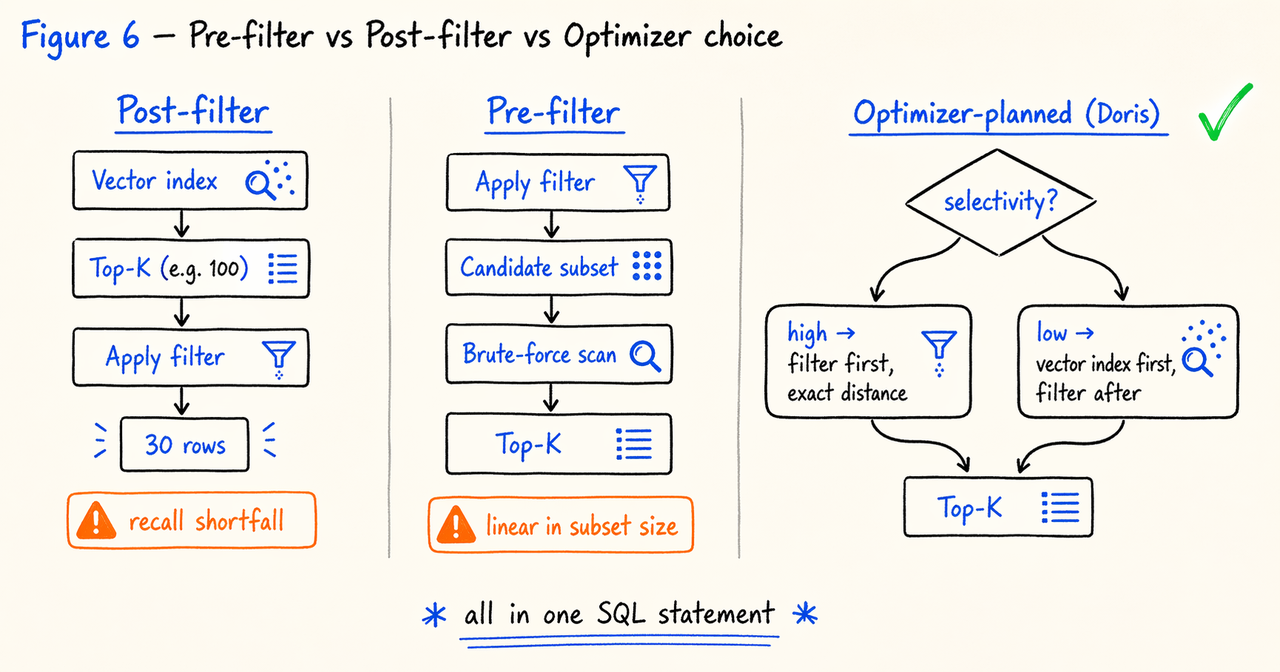
这正是 Apache Doris 原生向量索引的价值所在。查询优化器能够根据谓词选择性、索引可用性和代价估算,自动在预过滤与后过滤之间做出决策,应用层无需提前选择策略。
以一个商品表为例,表中同时存储商品元数据和视觉 Embedding。查询目标:在"运动鞋"类别中,找到 20 个有库存、价格在 50~200 元之间、且与参考商品视觉最相似的商品。
SELECT
id,
name,
price,
l2_distance(embedding, [0.12, 0.08, ..., 0.31]) AS distance
FROM products
WHERE category = 'sneakers'
AND in_stock = TRUE
AND price BETWEEN 50 AND 200
ORDER BY l2_distance(embedding, [0.12, 0.08, ..., 0.31])
LIMIT 20;
执行时,优化器根据选择性自动选择路径:若结构化条件过滤后候选集远小于 nprobe × 平均桶大小,则先过滤再在子集上计算精确距离;若过滤选择性低,则先走向量索引,再对结果施加过滤。
整个流程封装在一条 SQL 中,应用层既不需要硬编码预/后过滤策略,也不需要维护跨系统的数据同步。
多路召回融合排序
多路召回融合面临的问题与过滤不同:核心难点不在于逻辑放在哪里,而在于如何合并度量单位完全不同的分数。
最典型的场景是文本搜索与向量检索的融合。用户输入查询时,系统既要返回关键词匹配结果(倒排索引 + BM25),也要返回语义相关但可能不含关键词的结果(向量索引 + 距离)。两个通道的分数尺度完全不同,BM25 与 L2 距离之间不存在可直接加权的基础。
业界常用的方案是 RRF(Reciprocal Rank Fusion)。RRF 不对原始分数做归一化,而是只取每个结果在各通道中的排名,将倒数 1 / (k + rank) 求和作为最终得分。无需分数归一化、对离群值鲁棒、且易于扩展新的召回源,因此在近年的混合检索实践中被广泛采用。
在 Apache Doris 中,整个融合流程可以用一条 SQL 完成。以下示例在 HackerNews 数据集上,用 RRF 融合 BM25 文本搜索与 ANN 向量检索:
WITH
text_raw AS (
SELECT id, score() AS bm25
FROM hackernews
WHERE (`text` MATCH_PHRASE 'hybrid search'
OR `title` MATCH_PHRASE 'hybrid search')
AND dead = 0 AND deleted = 0
ORDER BY score() DESC
LIMIT 1000
),
vec_raw AS (
SELECT id, l2_distance_approximate(`vector`, [0.12, 0.08, ...]) AS dist
FROM hackernews
ORDER BY dist ASC
LIMIT 1000
),
text_rank AS (
SELECT id, ROW_NUMBER() OVER (ORDER BY bm25 DESC) AS r_text FROM text_raw
),
vec_rank AS (
SELECT id, ROW_NUMBER() OVER (ORDER BY dist ASC) AS r_vec FROM vec_raw
),
fused AS (
SELECT id, SUM(1.0 / (60 + rank)) AS rrf_score
FROM (
SELECT id, r_text AS rank FROM text_rank
UNION ALL
SELECT id, r_vec AS rank FROM vec_rank
) t
GROUP BY id
ORDER BY rrf_score DESC
LIMIT 20
)
SELECT f.id, h.title, h.text, f.rrf_score
FROM fused f
JOIN hackernews h ON h.id = f.id
ORDER BY f.rrf_score DESC;
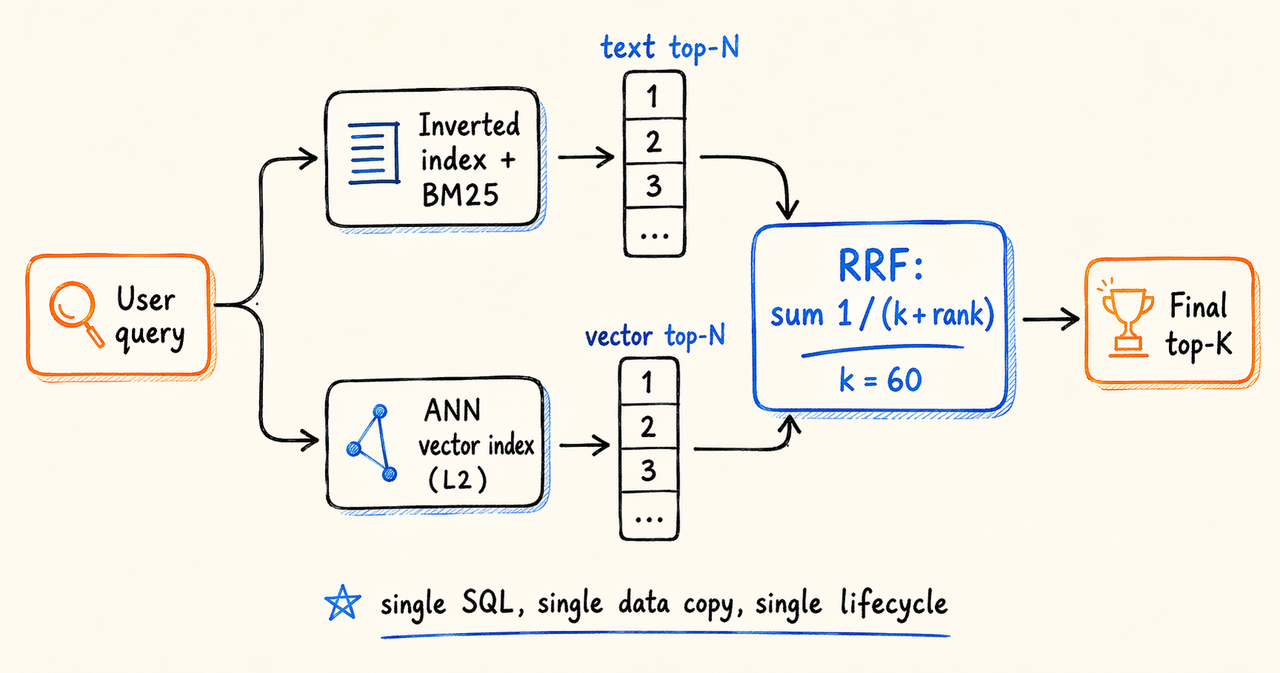
执行路径分为四步:倒排索引与 ANN 索引并行执行 BM25 和 L2 距离召回,各取 Top-N;对两组结果按原始分数局部排序并分配排名;将每个候选在各通道的排名贡献
1 / (k + rank)求和,得出最终得分;仅对最终 Top-K 结果回表读取展示字段,避免中间步骤扫描宽列。
将融合放在 SQL 层的价值不在算法本身,RF 在任何地方都能实现。真正的收益在于,两个检索通道共享同一份数据、同一套事务可见性和同一套生命周期管理。需要扩展第三路召回(按类别、时间或用户画像加权)时,只需新增一个 CTE,无需引入额外系统。
公开基准与选型参考
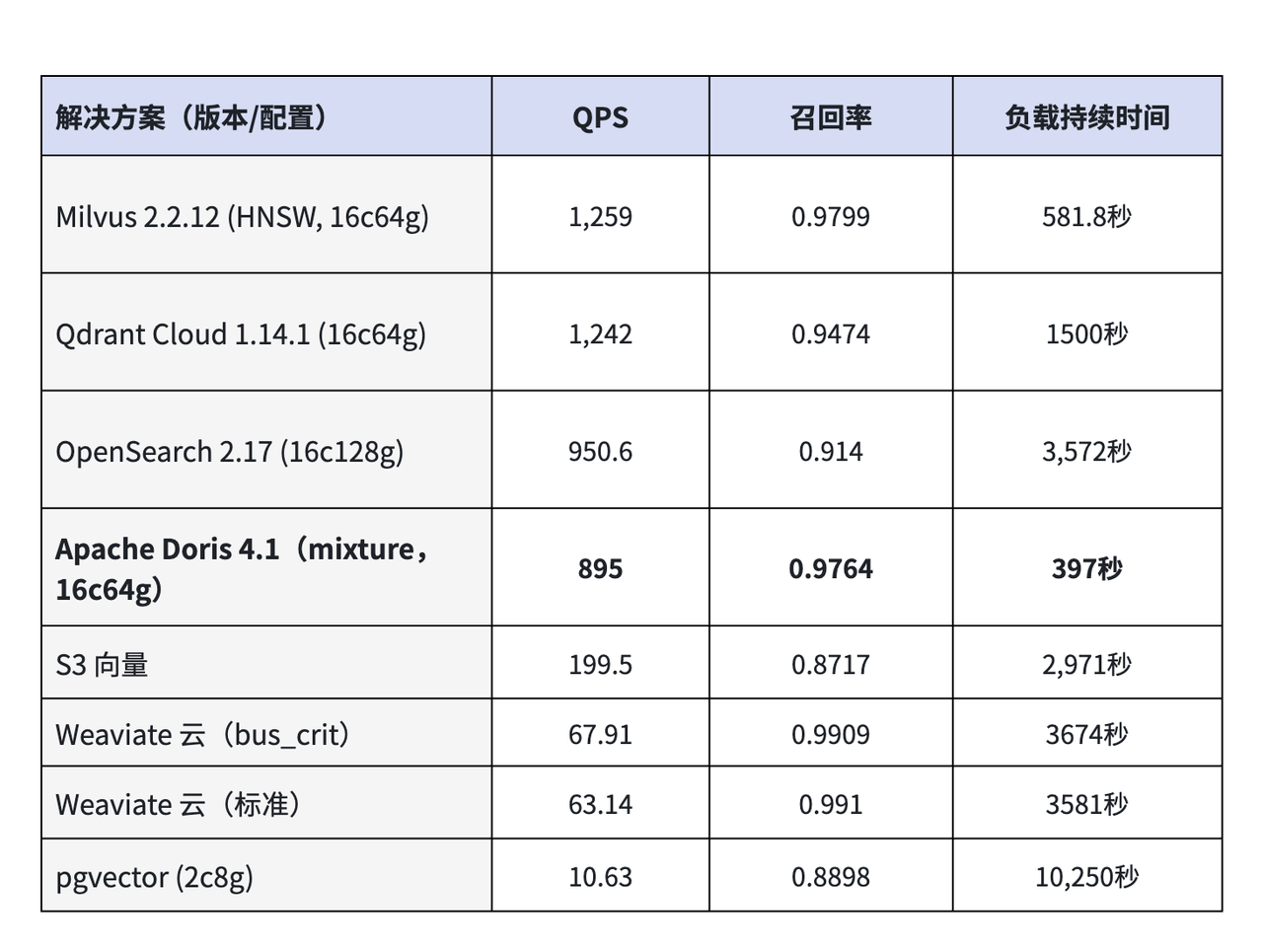
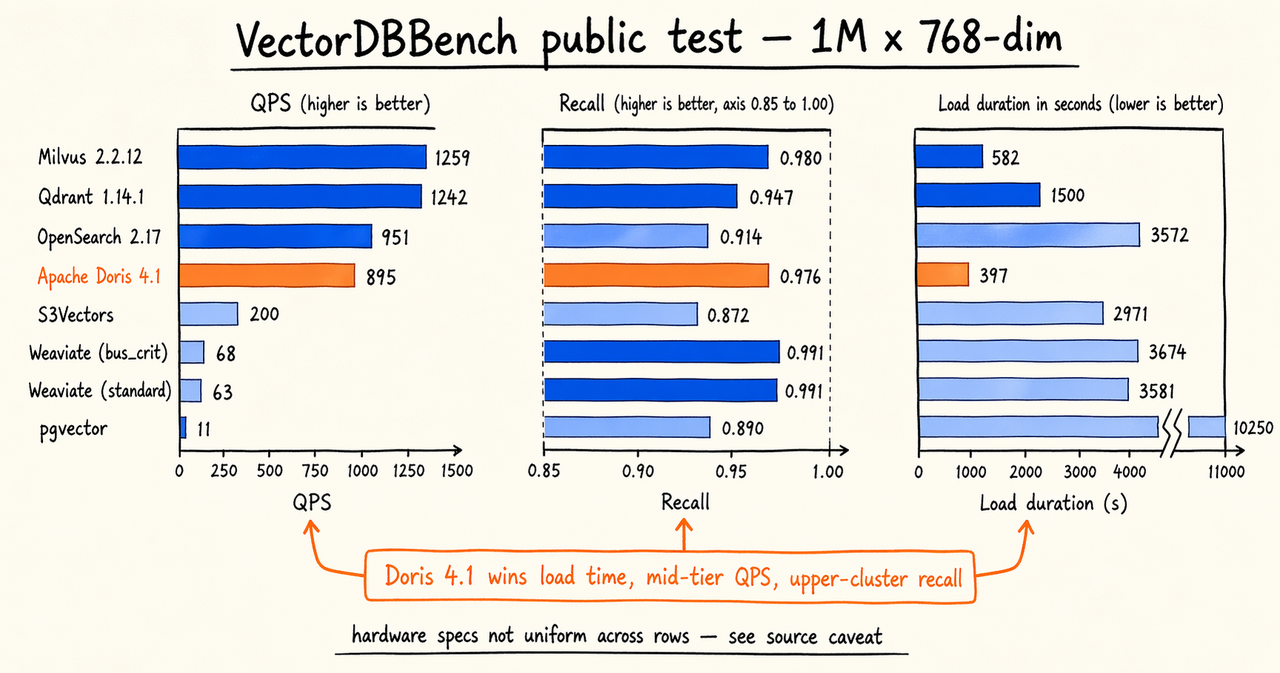
根据 VectorDBBench(100 万 × 768 维,2026 年 1 月)的公开测试数据,主流向量检索系统的表现如下(按 QPS 排序)。
注:各系统的硬件规格并不统一。OpenSearch 运行在 16c128g,pgvector 运行在 2c8g,Weaviate Cloud 和 S3Vectors 为托管服务、由平台选定规格。行与行之间的对比需考虑这一差异。
对比总结:
- 加载时长(索引构建): Doris 4.1(397 秒)在本表中最快,比 Milvus HNSW(581.8 秒)快约 30%,比 pgvector(10250 秒)快一个数量级以上。这一指标对批量冷启动、Embedding 模型变更后的索引重建以及历史数据回填尤为关键。
- QPS(查询吞吐): Milvus 和 Qdrant 领先,超过 1200。Doris 4.1(895)与 OpenSearch(950.6)处于同一梯队。
- 召回率:Weaviate Cloud 两种配置(0.9910 / 0.9909)领先;Milvus、Doris、Qdrant 处于第二梯队,均高于 0.94,满足绝大多数生产级要求。
从数据中可以发现,高 QPS 往往伴随较低召回率,高召回率往往伴随较低 QPS。Doris 4.1 以构建速度领先、QPS 和召回率均处于中高水平,提供了另一种极佳的权衡组合。
不过,基准测试数据只有在匹配实际工作负载时才有意义。比如,频繁重建索引场景应重点关注加载时长;对 p99 延迟或召回率下限有硬性要求则需在目标运行点上做针对性压测....
结合以上三个维度,可以做如下粗略映射:
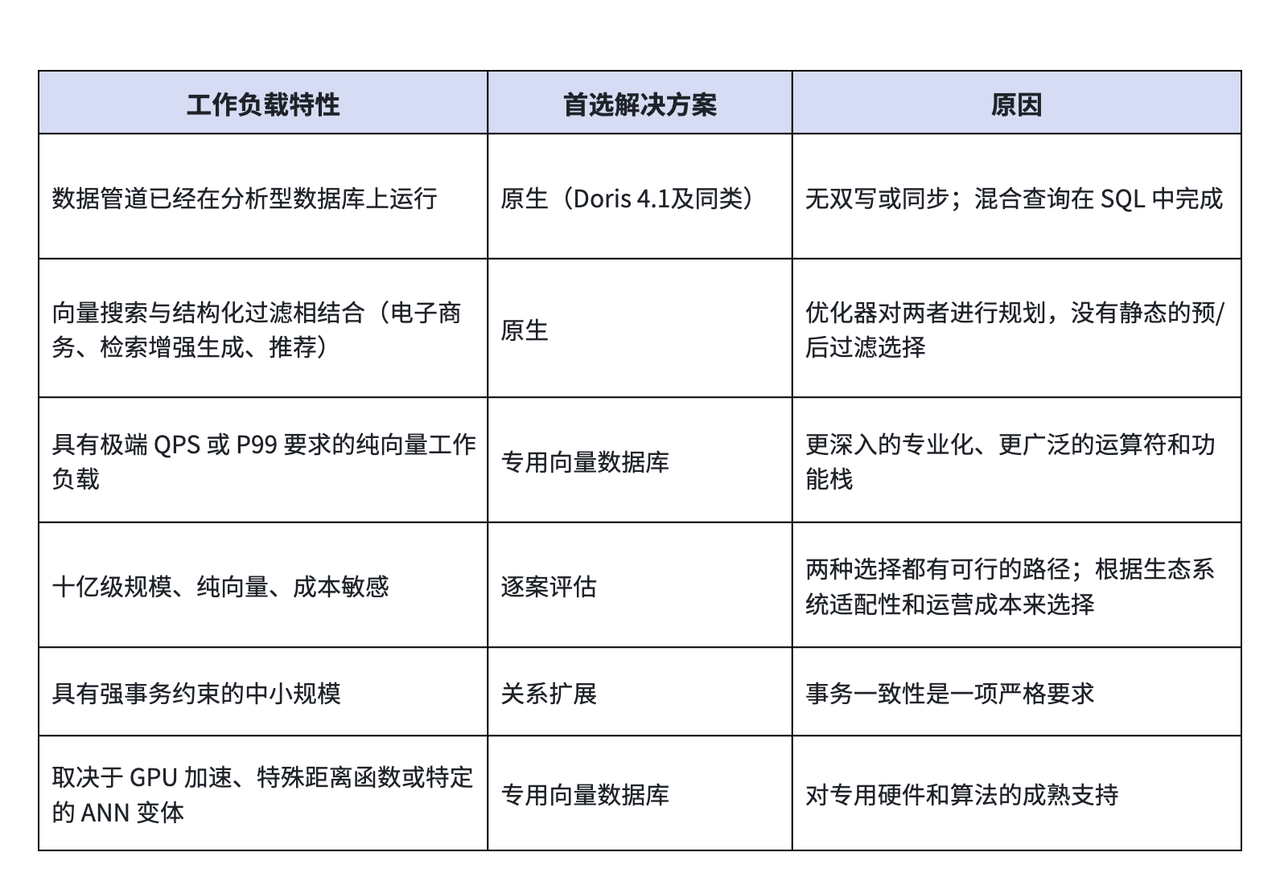
结束语
过去几年,向量数据库经历了快速爆发期。但随着 AI 应用真正进入生产环境,行业逐渐意识到,真正困难的并不是把向量搜出来,而是如何与结构化数据协同、如何降低系统复杂度、如何控制 TB 级资源成本、以及如何统一 SQL、全文、向量与分析能力。
越来越多的分析型数据库开始原生集成向量能力,向量检索正在从独立系统重新回归数据库体系。Apache Doris 4.1 的方向,正是这一趋势演进的缩影。当向量检索成为 SQL 的原生能力,开发者终于可以把精力重新集中在业务创新上,而不是复杂的系统运维上。
本文相关参考:


