
在快递行业,运单数据贯穿业务全流程,每一单的流转状态、时效分析、异常监控,都离不开实时数据的支撑。作为行业领军企业,中通快递每天新增的运单数据超过 6 亿条(80% 为更新操作),总数据量高达 45 亿条,单表字段超过 200 个——这是一个超大规模、超高维度的实时分析场景。
面对如此庞大的数据规模,如何让数据分析快起来,让业务人员随时能查到想看的运单信息,成为技术团队必须攻克的难题。今天,我们就来聊聊中通快递如何通过技术架构升级,让运单数据分析从分钟级提升至秒级。
日增数据 6+ 亿,旧架构难以支撑
1. 第一代:TP 数据库瓶颈
在业务发展初期,数据量不大时,MySQL、PostgreSQL 这类事务型数据库就能满足运单查询和管理需求。但随着数据规模日益庞大,业务产生大量分析型查询,高 QPS、低延迟的多维度实时查询需求变得极为迫切,比如按时间、地区、状态等多维度统计运单。此时,TP 数据库在处理多维度聚合计算时存在性能瓶颈,无法同时满足实时更新、高并发、低延迟的综合要求。因此,技术架构需要转向专用的 AP(分析型)数据库。
2. 第二代:基于 HTAP 的架构
为了解决 TP 数据库的分析瓶颈,同时适配运单业务的核心数据特性 —— 80% 都是更新操作,普通 OLAP 分析系统无法支撑如此高比例的实时更新需求,我们选用了 HTAP 架构方案,搭建了一套基于 Flink + 行存 + 列存双引擎的过渡架构。该架构先通过行存承接 Flink 任务的高频实时写入,保障写入的灵活性与实时性,数据库内部自动同步生成列存副本,专门用于支撑分析查询,逻辑上分为四层:
- 上游消息队列:通过消息队列实时同步多类核心数据;
- Flink 处理层:按表拆分多个任务,对宽表进行部分列更新;
- 存储层:更新数据最终写入 HTAP 数据库的单张无分区宽表中;
- 应用层:直接查询该数据库,支撑各类数据监控与分析需求。
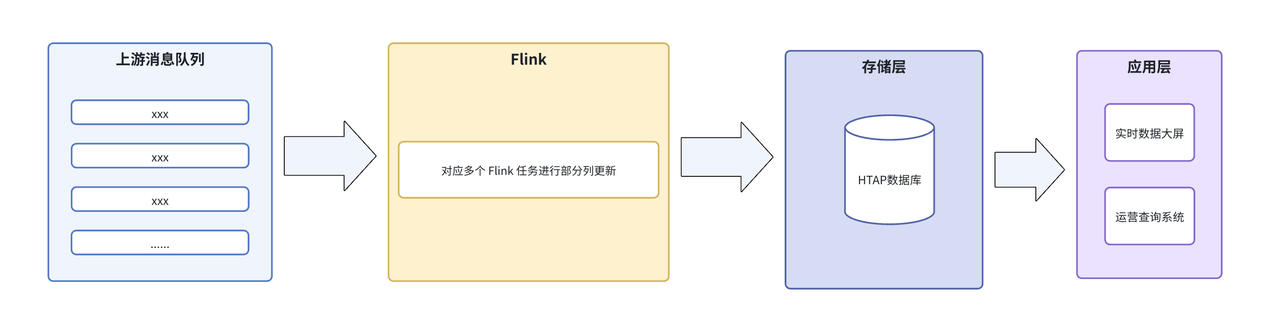
随着数据量激增至日增 6 亿条,架构的设计缺陷逐渐凸显:
- 查询耗时长:执行多维度等值筛选类查询时,耗时超 1 分钟;执行≥3 维的多维度聚合计算类查询时,单条 SQL 耗时达 5-10 分钟,远无法满足实时查询的技术要求。
- 并发低:业务高峰期,各类数据应用的并发查询超 50 个时,数据库 CPU 利用率飙升至 95% 以上,30% 的查询出现超时,部分上层应用服务无法正常响应。
- 成本高:表扫描 + 无索引的查询方式长期占用大量 CPU 与 IO,机器负载长期处于 90% 以上,资源冗余度接近于 0。存储层的硬件机器持续扩容,但仍频繁出现磁盘 IO 满载、CPU 资源抢占问题。
这主要是 HTAP 方案中的列存无分区和倒排索引的特性,查询仍依赖全表扫描;同时缺乏精细化的资源隔离与管控能力,高并发下查询稳定性无法保障。
引入 SelectDB,重构实时分析底座
面对旧架构的种种问题,我们开始了新一轮的技术选型。核心诉求很明确,要求:
- 能够支持高频部分列更新
- 能够支持倒排索引加速多维查询
- 能够支持高并发低延迟
调研发现,SelectDB 能同时满足这些诉求。
SelectDB(www.selectdb.com/) 作为 Apache Doris 的核心贡献者和商业化团队,是在 Doris 开源内核基础上,提供了企业级特性、全托管运维服务及专业技术支持,帮助企业更便捷地将 Doris 能力应用于生产环境。
新架构依然沿用 Flink 做数据加工,但存储引擎换成了 SelectDB,整体流程如下:
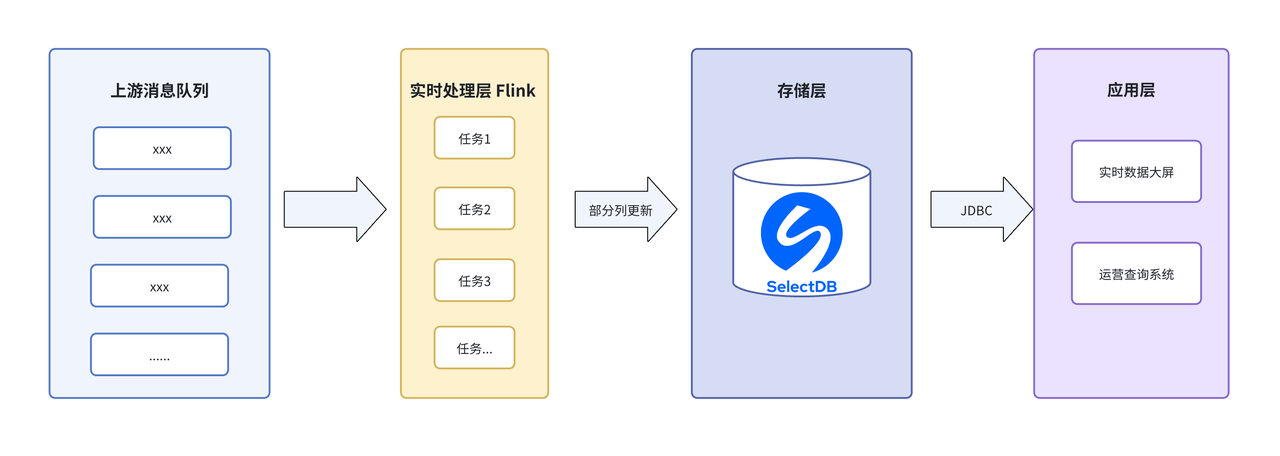

下面,我们来拆解几个关键技术点:
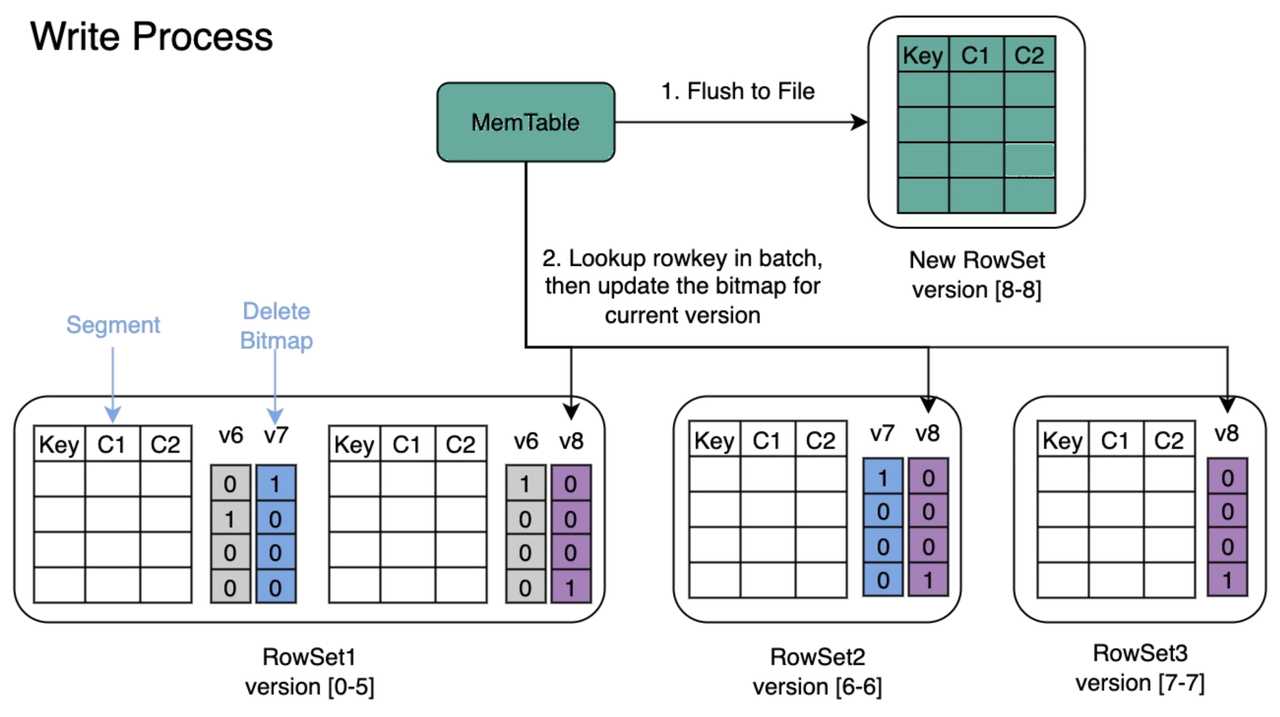
1. Merge-On-Write:保障数据唯一与实时更新
运单数据必须以单号为唯一标识,而且同一个运单在流转中会多次更新状态。SelectDB 的 Merge-On-Write 模式能在数据写入时直接完成合并,确保查询时拿到的都是最新版本,适配高频更新场景(上游分钟级更新)。相比传统的读取时合并模式,查询时不用再翻历史数据,精确匹配实时数据查询与监控的低延迟需求。
2. 部分列更新:降低写入成本,适配多源数据整合
前面提到,上游数据来自不同业务模块,每个模块只更新自己那部分字段。如果每次更新都把整行 200 多个字段重写一遍,成本太高。SelectDB 主键模型支持更新部分列数据的功能,不需要先读取整行数据,从而大幅提升更新效率。
3. Unique Key 日期更新:保证数据一致性
运单宽表以单号 + 时间维度字段为 Unique Key,实际应用中存在时间维度字段的调整需求,需在保障数据全局唯一性的前提下完成字段更新,避免出现重复数据记录。
新架构基于 Flink 开发专属实时任务处理时间维度字段变更,核心逻辑如下:
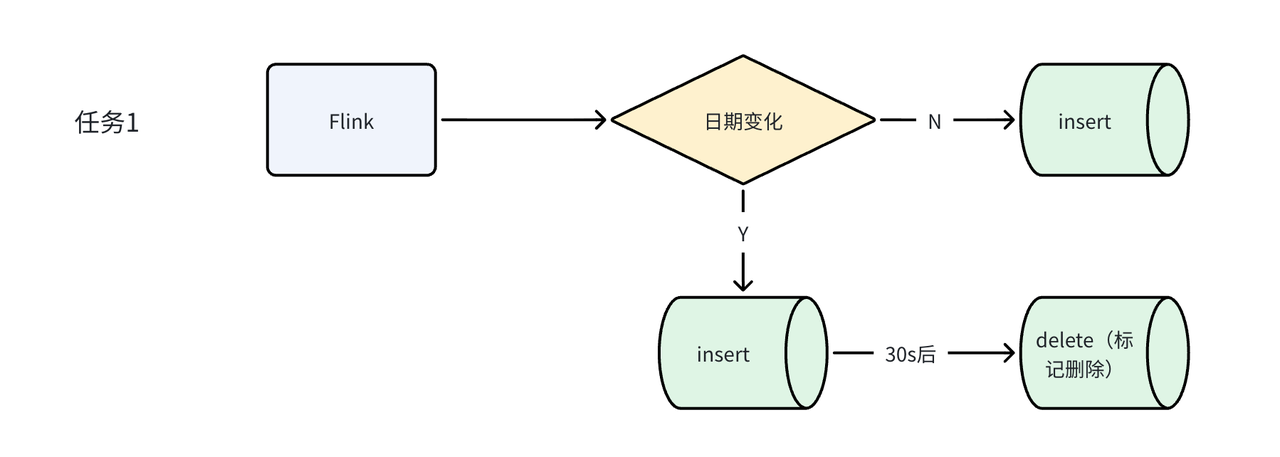
- Flink 实时读取上游的时间维度字段变更数据,检测目标数据的时间维度字段是否发生变化;
- 若无变化(N):直接执行 INSERT 操作,将数据正常写入宽表;
- 若有变化(Y):先执行 INSERT 操作写入包含新时间维度字段的数据,30 秒后执行标记删除操作删除旧时间维度字段的历史数据。
4. 倒排索引:加速宽表多维查询
运单宽表包含 200 + 列,日常查询中高频涉及时间、维度 ID、数据状态等维度的等值 / 范围筛选,以及基于这些维度的多指标聚合计算。未加索引时所有查询均需全表扫描,单查询耗时超分钟级,无法支撑实时查询的低延迟需求。
基于 SelectDB,为这些高频查询字段构建了倒排索引。覆盖实时监控、多维统计、精准筛选等核心查询场景。其原理是将字段值(如维度ID='xxx'、数据状态='xxx')映射到对应的行地址,查询时直接定位目标行,有效降低了 IO 和 CPU 消耗。同时,倒排索引也能高效支持日期范围筛选(如 time_col >= '2025-12-01' and time_col < '2026-01-01')。
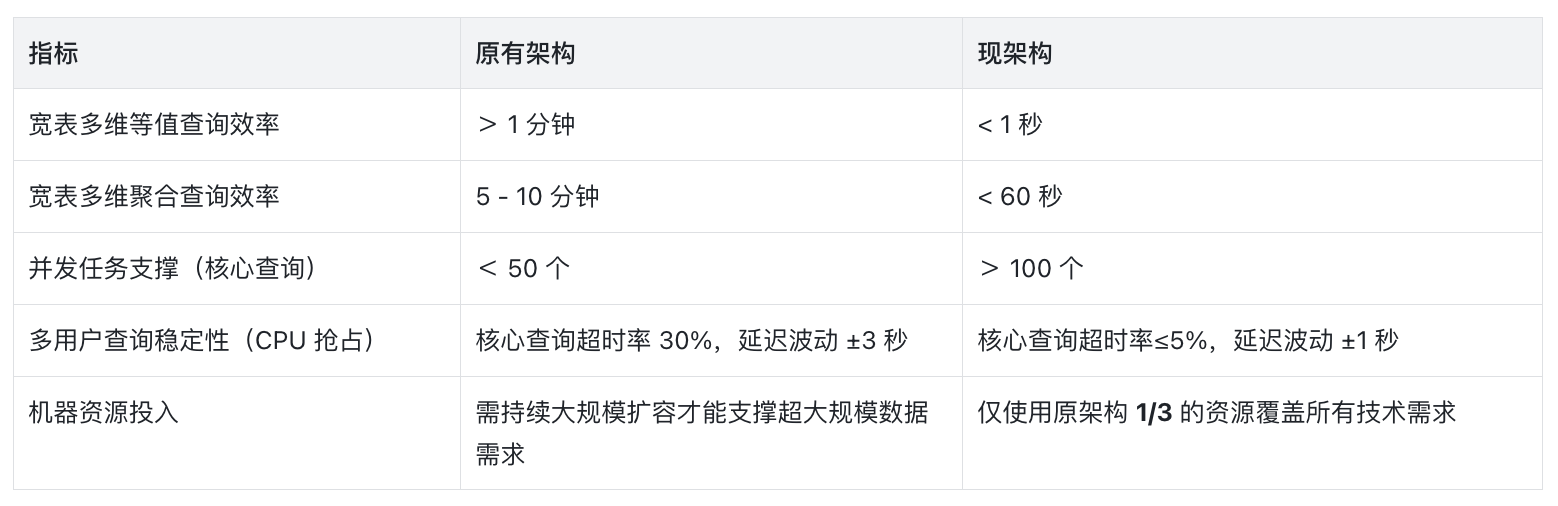
优化后效果显著:多维等值筛选查询耗时从 1 分钟降至 1 秒内;多维聚合的查询耗时从 5 - 10 分钟降至 60 秒内,足以匹配实时查询的技术需求。
5. Workload Group 资源隔离:避免多用户 CPU 抢占
基于 SelectDB 的 Workload Group 机制,按用户查询场景划分专属资源组,为各资源组配置 CPU 权重、最大并发数等规则,同时将不同场景的用户绑定至对应资源组,实现 CPU 资源的隔离分配与精细化管控。优化后:
- 高并发下不同场景、不同用户的查询互不抢占,核心查询的延迟波动从 ±3 秒缩短至 ±1 秒;
- 核心查询场景的超时率从 30% 降至 5% 以下,显著提升高并发下的查询服务稳定性。
整体收益及效果
本次架构优化围绕写入、查询、资源三大核心维度实现技术突破,原有架构的痛点均得到彻底解决,核心技术指标优化效果如下表所示:
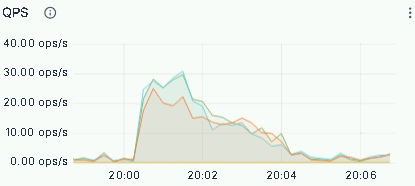
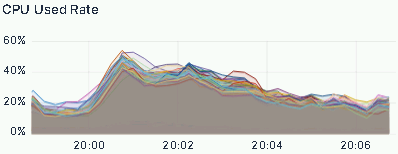
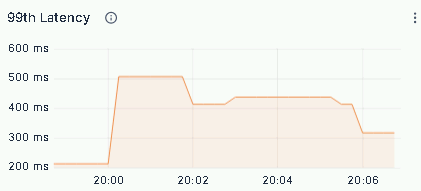
为进一步验证现架构在高压力场景下的性能表现与稳定性,针对业务高峰期的系统运行状态进行了实测分析,从 QPS、CPU 资源消耗、核心查询 99 分位延迟三个维度开展指标监控,实测结果如下:
QPS:
CPU 消耗:
多维等值查询 99 延迟:
多维聚合查询 99 延迟:
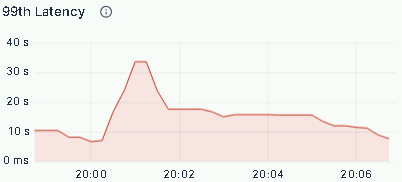
- QPS 峰值超过 80 次/秒,系统无任何请求堆积;
- CPU 使用率始终平稳,没有出现飙升;
- 99%的查询延迟:等值查询维持在毫秒级,聚合查询稳定控制在 1 分钟以内。
结束语
基于 SelectDB 构建的全新实时分析架构,突破了原有架构的设计瓶颈,实现了全链路性能、效率与稳定性的提升。本次架构优化的核心,是依托 SelectDB 在高频实时更新与倒排索引加速多维查询两大方向的独有技术能力,核心优化逻辑可总结为三点:
- 写入层优化:依托 SelectDB 原生的部分列更新 + MOW 模式,完美适配运单场景日均 80% 的更新需求,解决了多源数据整合的高吞吐写入问题,实现数据从业务产生到可查询的秒级可见,同时大幅降低写入 IO 消耗,提升硬件资源利用效率;
- 存储层优化:以单号 + 时间维度字段为 Unique Key,保障运单数据的全局唯一性,同时支持时间维度字段的动态更新,适配实际应用中的数据调整需求,确保运单数据的一致性与准确性;
- 查询层优化:通过为高频筛选字段构建倒排索引,实现多维等值 / 聚合查询效率的数量级提升,满足实时查询与监控的低延迟需求;同时基于 Workload Group 实现按场景的资源隔离与精细化管控,解决了多用户 CPU 资源抢占问题,保障核心查询的稳定性。
最终,新架构成功支撑了日增 6 亿、总量 45 亿、200 + 列的超大规模运单多维实时分析需求,实现了超大规模数据的实时整合、低延迟查询与精细化资源管控,成为支撑各类实时数据应用的核心技术底座。


