导读:这是一篇非常完整全面的应用技术干货,手把手教你如何使用 Doris+Iceberg+Flink CDC 构建实时湖仓一体的联邦查询分析架构。按照本文中步骤一步步完成,完整体验搭建操作的完整过程。
1.概览
这篇教程将展示如何使用 Doris+Iceberg+Flink CDC 构建实时湖仓一体的联邦查询分析,Doris 1.1版本提供了Iceberg的支持,本文主要展示Doris和Iceberg怎么使用,同时本教程整个环境是都基于伪分布式环境搭建,大家按照步骤可以一步步完成。完整体验整个搭建操作的过程。
1.1 软件环境
本教程的演示环境如下:
- Centos7
- Apahce doris 1.1
- Hadoop 3.3.3
- hive 3.1.3
- Fink 1.14.4
- flink-sql-connector-mysql-cdc-2.2.1
- Apache Iceberg 0.13.2
- JDK 1.8.0_311
- MySQL 8.0.29
wget https://archive.apache.org/dist/hadoop/core/hadoop-3.3.3/hadoop-3.3.3.tar.gz
wget https://archive.apache.org/dist/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz
wget https://dlcdn.apache.org/flink/flink-1.14.4/flink-1.14.4-bin-scala_2.12.tgz
wget https://search.maven.org/remotecontent?filepath=org/apache/iceberg/iceberg-flink-runtime-1.14/0.13.2/iceberg-flink-runtime-1.14-0.13.2.jar
wget https://repository.cloudera.com/artifactory/cloudera-repos/org/apache/flink/flink-shaded-hadoop-3-uber/3.1.1.7.2.9.0-173-9.0/flink-shaded-hadoop-3-uber-3.1.1.7.2.9.0-173-9.0.jar
1.2 系统架构
我们整理架构图如下
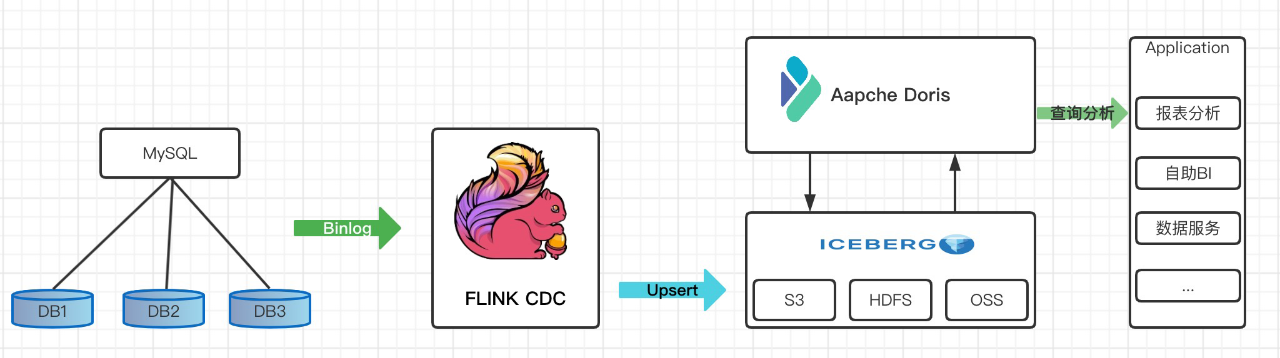
- 首先我们从Mysql数据中使用Flink 通过 Binlog完成数据的实时采集
- 然后再Flink 中创建 Iceberg 表,Iceberg的元数据保存在hive里
- 最后我们在Doris中创建Iceberg外表
- 在通过Doris 统一查询入口完成对Iceberg里的数据进行查询分析,供前端应用调用,这里iceberg外表的数据可以和Doris内部数据或者Doris其他外部数据源的数据进行关联查询分析
Doris湖仓一体的联邦查询架构如下:
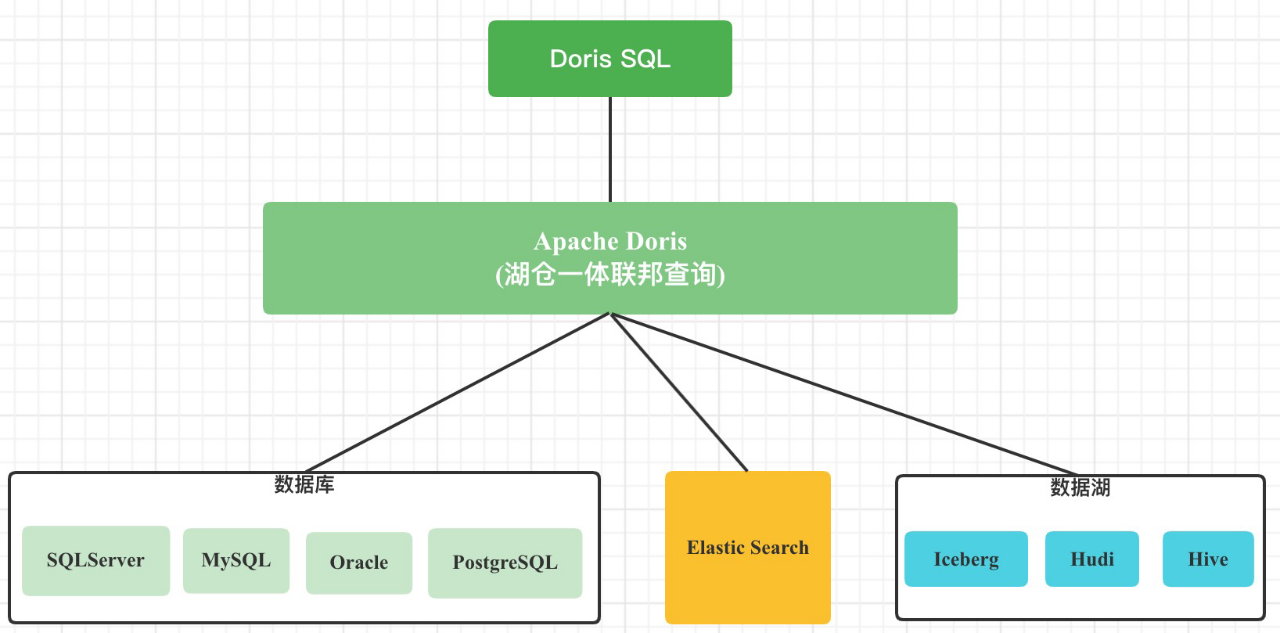
- Doris 通过 ODBC 方式支持:MySQL,Postgresql,Oracle ,SQLServer
- 同时支持 Elasticsearch 外表
- 1.0版本支持Hive外表
- 1.1版本支持Iceberg外表
- 1.2版本支持Hudi 外表
2.环境安装部署
2.1 安装Hadoop、Hive
tar zxvf hadoop-3.3.3.tar.gz
tar zxvf apache-hive-3.1.3-bin.tar.gz
配置系统环境变量
export HADOOP_HOME=/data/hadoop-3.3.3
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HIVE_HOME=/data/hive-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin:$HIVE_HOME/bin:$HIVE_HOME/conf
2.2 配置hdfs
2.2.1 core-site.xml
vi etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
2.2.2 hdfs-site.xml
vi etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/hdfs/datanode</value>
</property>
</configuration>
2.2.3 修改Hadoop启动脚本
sbin/start-dfs.sh
sbin/stop-dfs.sh
在文件开始加上下面的内容
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
sbin/start-yarn.sh
sbin/stop-yarn.sh
在文件开始加上下面的内容
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
2.3 配置yarn
这里我改变了Yarn的一些端口,因为我是单机环境和Doris 的一些端口冲突。你可以不启动yarn
vi etc/hadoop/yarn-site.xml
<property>
<name>yarn.resourcemanager.address</name>
<value>jiafeng-test:50056</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>jiafeng-test:50057</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>jiafeng-test:50058</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>jiafeng-test:50059</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>jiafeng-test:9090</value>
</property>
<property>
<name>yarn.nodemanager.localizer.address</name>
<value>0.0.0.0:50060</value>
</property>
<property>
<name>yarn.nodemanager.webapp.address</name>
<value>0.0.0.0:50062</value>
</property>
vi etc/hadoop/mapred-site.xm
<property>
<name>mapreduce.jobhistory.address</name>
<value>0.0.0.0:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>0.0.0.0:19888</value>
</property>
<property>
<name>mapreduce.shuffle.port</name>
<value>50061</value>
</property>
2.2.4 启动hadoop
sbin/start-all.sh
2.4 配置Hive
2.4.1 创建hdfs目录
hdfs dfs -mkdir -p /user/hive/warehouse
hdfs dfs -mkdir /tmp
hdfs dfs -chmod g+w /user/hive/warehouse
hdfs dfs -chmod g+w /tmp
2.4.2 配置hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>MyNewPass4!</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
<property>
<name>hive.metastore.uris</name>
<value/>
<description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description>
</property>
<property>
<name>javax.jdo.PersistenceManagerFactoryClass</name>
<value>org.datanucleus.api.jdo.JDOPersistenceManagerFactory</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
</property>
</configuration>
2.4.3 配置 hive-env.sh
加入一下内容
HADOOP_HOME=/data/hadoop-3.3.3
2.4.4 hive元数据初始化
schematool -initSchema -dbType mysql
2.4.5 启动hive metaservice
后台运行
nohup bin/hive --service metaservice 1>/dev/null 2>&1 &
验证
lsof -i:9083
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 20700 root 567u IPv6 54605348 0t0 TCP *:emc-pp-mgmtsvc (LISTEN)
2.5 安装MySQL
2.5.1 创建MySQL数据库表并初始化数据
CREATE DATABASE demo;
USE demo;
CREATE TABLE userinfo (
id int NOT NULL AUTO_INCREMENT,
name VARCHAR(255) NOT NULL DEFAULT 'flink',
address VARCHAR(1024),
phone_number VARCHAR(512),
email VARCHAR(255),
PRIMARY KEY (`id`)
)ENGINE=InnoDB ;
INSERT INTO userinfo VALUES (10001,'user_110','Shanghai','13347420870', NULL);
INSERT INTO userinfo VALUES (10002,'user_111','xian','13347420870', NULL);
INSERT INTO userinfo VALUES (10003,'user_112','beijing','13347420870', NULL);
INSERT INTO userinfo VALUES (10004,'user_113','shenzheng','13347420870', NULL);
INSERT INTO userinfo VALUES (10005,'user_114','hangzhou','13347420870', NULL);
INSERT INTO userinfo VALUES (10006,'user_115','guizhou','13347420870', NULL);
INSERT INTO userinfo VALUES (10007,'user_116','chengdu','13347420870', NULL);
INSERT INTO userinfo VALUES (10008,'user_117','guangzhou','13347420870', NULL);
INSERT INTO userinfo VALUES (10009,'user_118','xian','13347420870', NULL);
2.6 安装 Flink
tar zxvf flink-1.14.4-bin-scala_2.12.tgz
然后需要将下面的依赖拷贝到Flink安装目录下的lib目录下,具体的依赖的lib文件如下:
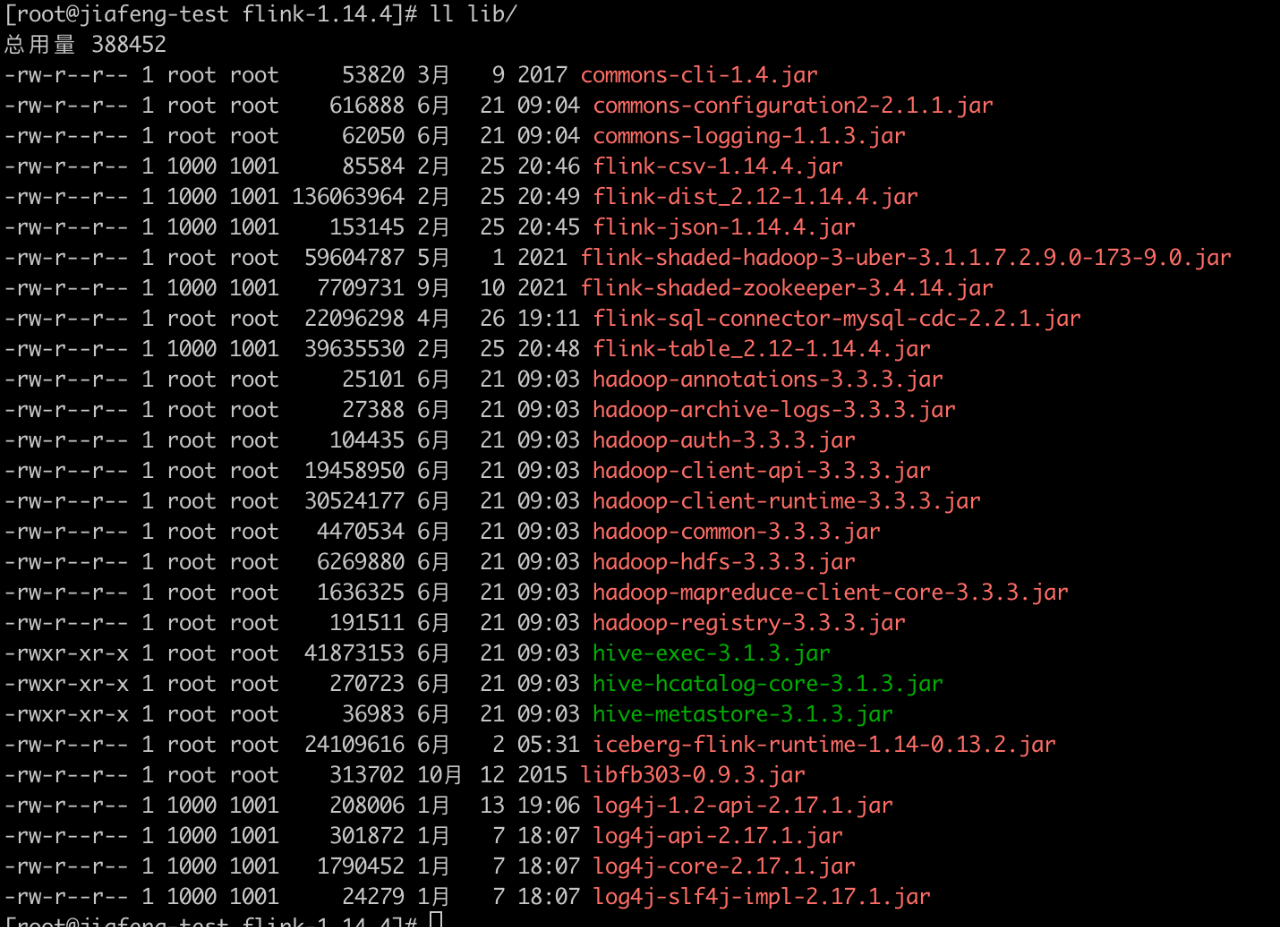
下面将几个Hadoop和Flink里没有的依赖下载地址放在下面
wget https://repo1.maven.org/maven2/com/ververica/flink-sql-connector-mysql-cdc/2.2.1/flink-sql-connector-mysql-cdc-2.2.1.jar
wget https://repo1.maven.org/maven2/org/apache/thrift/libfb303/0.9.3/libfb303-0.9.3.jar
wget https://search.maven.org/remotecontent?filepath=org/apache/iceberg/iceberg-flink-runtime-1.14/0.13.2/iceberg-flink-runtime-1.14-0.13.2.jar
wget https://repository.cloudera.com/artifactory/cloudera-repos/org/apache/flink/flink-shaded-hadoop-3-uber/3.1.1.7.2.9.0-173-9.0/flink-shaded-hadoop-3-uber-3.1.1.7.2.9.0-173-9.0.jar
其他的:
hadoop-3.3.3/share/hadoop/common/lib/commons-configuration2-2.1.1.jar
hadoop-3.3.3/share/hadoop/common/lib/commons-logging-1.1.3.jar
hadoop-3.3.3/share/hadoop/tools/lib/hadoop-archive-logs-3.3.3.jar
hadoop-3.3.3/share/hadoop/common/lib/hadoop-auth-3.3.3.jar
hadoop-3.3.3/share/hadoop/common/lib/hadoop-annotations-3.3.3.jar
hadoop-3.3.3/share/hadoop/common/hadoop-common-3.3.3.jar
adoop-3.3.3/share/hadoop/hdfs/hadoop-hdfs-3.3.3.jar
hadoop-3.3.3/share/hadoop/client/hadoop-client-api-3.3.3.jar
hive-3.1.3/lib/hive-exec-3.1.3.jar
hive-3.1.3/lib/hive-metastore-3.1.3.jar
hive-3.1.3/lib/hive-hcatalog-core-3.1.3.jar
2.6.1 启动Flink
bin/start-cluster.sh
启动后的界面如下:
2.6.2 进入 Flink SQL Client
bin/sql-client.sh embedded
开启 checkpoint,每隔3秒做一次 checkpoint
Checkpoint 默认是不开启的,我们需要开启 Checkpoint 来让 Iceberg 可以提交事务。 并且,mysql-cdc 在 binlog 读取阶段开始前,需要等待一个完整的 checkpoint 来避免 binlog 记录乱序的情况。
注意:
这里是演示环境,checkpoint的间隔设置比较短,线上使用,建议设置为3-5分钟一次checkpoint。
Flink SQL> SET execution.checkpointing.interval = 3s;
[INFO] Session property has been set.
2.6.3 创建Iceberg Catalog
CREATE CATALOG hive_catalog WITH (
'type'='iceberg',
'catalog-type'='hive',
'uri'='thrift://localhost:9083',
'clients'='5',
'property-version'='1',
'warehouse'='hdfs://localhost:8020/user/hive/warehouse'
);
查看catalog
Flink SQL> show catalogs;
+-----------------+
| catalog name |
+-----------------+
| default_catalog |
| hive_catalog |
+-----------------+
2 rows in set
2.6.4 创建 Mysql CDC 表
CREATE TABLE user_source (
database_name STRING METADATA VIRTUAL,
table_name STRING METADATA VIRTUAL,
`id` DECIMAL(20, 0) NOT NULL,
name STRING,
address STRING,
phone_number STRING,
email STRING,
PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'localhost',
'port' = '3306',
'username' = 'root',
'password' = 'MyNewPass4!',
'database-name' = 'demo',
'table-name' = 'userinfo'
);
查询CDC表:
select * from user_source;

2.6.5 创建Iceberg表
---查看catalog
show catalogs;
---使用catalog
use catalog hive_catalog;
--创建数据库
CREATE DATABASE iceberg_hive;
--使用数据库
use iceberg_hive;
2.6.5.1 创建表
CREATE TABLE all_users_info (
database_name STRING,
table_name STRING,
`id` DECIMAL(20, 0) NOT NULL,
name STRING,
address STRING,
phone_number STRING,
email STRING,
PRIMARY KEY (database_name, table_name, `id`) NOT ENFORCED
) WITH (
'catalog-type'='hive'
);
从CDC表里插入数据到Iceberg表里
use catalog default_catalog;
insert into hive_catalog.iceberg_hive.all_users_info select * from user_source;
在web界面可以看到任务的运行情况
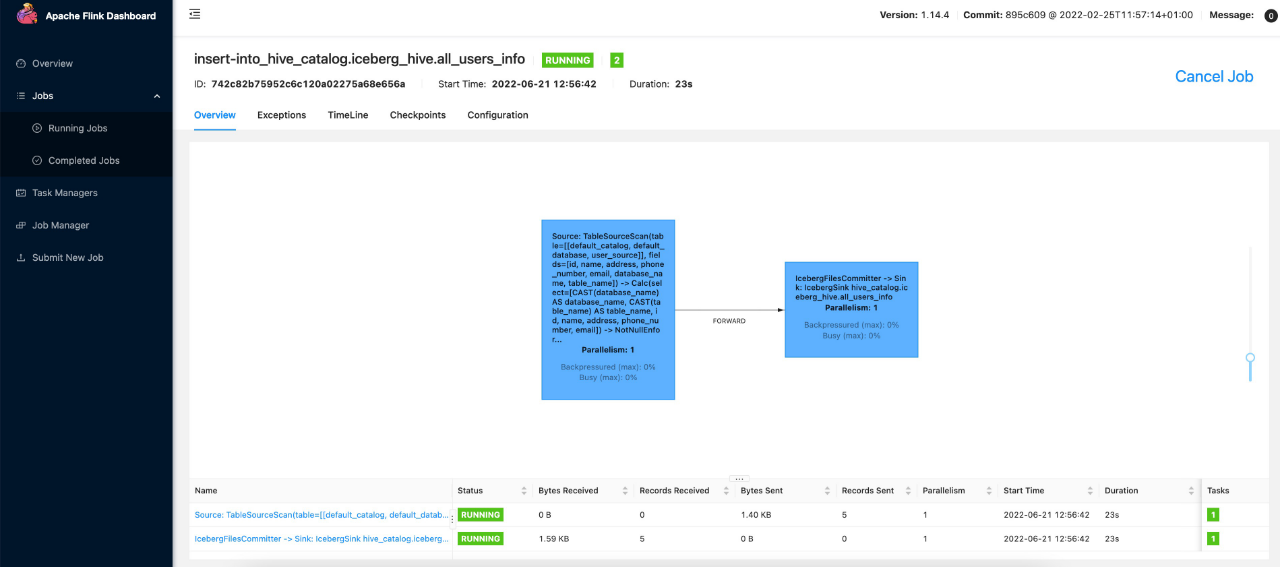
然后停掉任务,我们去查询iceberg表
select * from hive_catalog.iceberg_hive.all_users_info
可以看到下面的结果

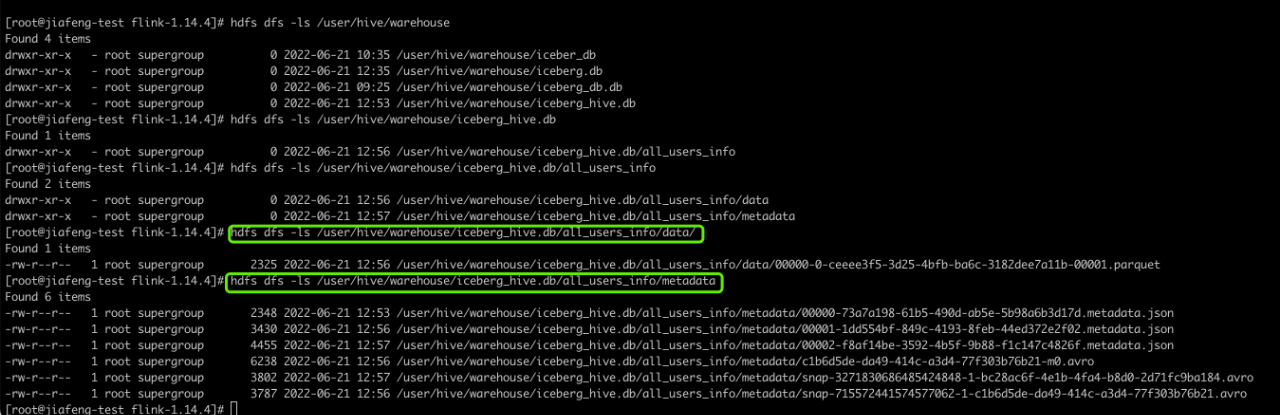
我们去hdfs上可以看到hive目录下的数据及对应的元数据
我们也可以通过Hive建好Iceberg表,然后通过Flink将数据插入到表里
下载Iceberg Hive运行依赖
wget https://repo1.maven.org/maven2/org/apache/iceberg/iceberg-hive-runtime/0.13.2/iceberg-hive-runtime-0.13.2.jar
在hive shell下执行:
SET engine.hive.enabled=true;
SET iceberg.engine.hive.enabled=true;
SET iceberg.mr.catalog=hive;
add jar /path/to/iiceberg-hive-runtime-0.13.2.jar;
创建表
CREATE EXTERNAL TABLE iceberg_hive(
`id` int,
`name` string)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://localhost:8020/user/hive/warehouse/iceber_db/iceberg_hive'
TBLPROPERTIES (
'iceberg.mr.catalog'='hadoop',
'iceberg.mr.catalog.hadoop.warehouse.location'='hdfs://localhost:8020/user/hive/warehouse/iceber_db/iceberg_hive'
);
然后再Flink SQL Client下执行下面语句将数据插入到Iceber表里
INSERT INTO hive_catalog.iceberg_hive.iceberg_hive values(2, 'c');
INSERT INTO hive_catalog.iceberg_hive.iceberg_hive values(3, 'zhangfeng');
查询这个表
select * from hive_catalog.iceberg_hive.iceberg_hive
可以看到下面的结果

3. Doris 查询 Iceberg
Apache Doris 提供了 Doris 直接访问 Iceberg 外部表的能力,外部表省去了繁琐的数据导入工作,并借助 Doris 本身的 OLAP 的能力来解决 Iceberg 表的数据分析问题:
- 支持 Iceberg 数据源接入Doris
- 支持 Doris 与 Iceberg 数据源中的表联合查询,进行更加复杂的分析操作
3.1安装Doris
这里我们不在详细讲解Doris的安装,如果你不知道怎么安装Doris请参照官方文档:快速入门
3.2 创建Iceberg外表
CREATE TABLE `all_users_info`
ENGINE = ICEBERG
PROPERTIES (
"iceberg.database" = "iceberg_hive",
"iceberg.table" = "all_users_info",
"iceberg.hive.metastore.uris" = "thrift://localhost:9083",
"iceberg.catalog.type" = "HIVE_CATALOG"
);
参数说明:
-
ENGINE 需要指定为 ICEBERG
-
PROPERTIES 属性:
iceberg.hive.metastore.uris:Hive Metastore 服务地址iceberg.database:挂载 Iceberg 对应的数据库名iceberg.table:挂载 Iceberg 对应的表名,挂载 Iceberg database 时无需指定。iceberg.catalog.type:Iceberg 中使用的 catalog 方式,默认为HIVE_CATALOG,当前仅支持该方式,后续会支持更多的 Iceberg catalog 接入方式。
mysql> CREATE TABLE `all_users_info`
-> ENGINE = ICEBERG
-> PROPERTIES (
-> "iceberg.database" = "iceberg_hive",
-> "iceberg.table" = "all_users_info",
-> "iceberg.hive.metastore.uris" = "thrift://localhost:9083",
-> "iceberg.catalog.type" = "HIVE_CATALOG"
-> );
Query OK, 0 rows affected (0.23 sec)
mysql> select * from all_users_info;
+---------------+------------+-------+----------+-----------+--------------+-------+
| database_name | table_name | id | name | address | phone_number | email |
+---------------+------------+-------+----------+-----------+--------------+-------+
| demo | userinfo | 10004 | user_113 | shenzheng | 13347420870 | NULL |
| demo | userinfo | 10005 | user_114 | hangzhou | 13347420870 | NULL |
| demo | userinfo | 10002 | user_111 | xian | 13347420870 | NULL |
| demo | userinfo | 10003 | user_112 | beijing | 13347420870 | NULL |
| demo | userinfo | 10001 | user_110 | Shanghai | 13347420870 | NULL |
| demo | userinfo | 10008 | user_117 | guangzhou | 13347420870 | NULL |
| demo | userinfo | 10009 | user_118 | xian | 13347420870 | NULL |
| demo | userinfo | 10006 | user_115 | guizhou | 13347420870 | NULL |
| demo | userinfo | 10007 | user_116 | chengdu | 13347420870 | NULL |
+---------------+------------+-------+----------+-----------+--------------+-------+
9 rows in set (0.18 sec)
3.3 同步挂载
当 Iceberg 表 Schema 发生变更时,可以通过 REFRESH 命令手动同步,该命令会将 Doris 中的 Iceberg 外表删除重建。
-- 同步 Iceberg 表
REFRESH TABLE t_iceberg;
-- 同步 Iceberg 数据库
REFRESH DATABASE iceberg_test_db;
3.4 Doris 和 Iceberg 数据类型对应关系
支持的 Iceberg 列类型与 Doris 对应关系如下表:
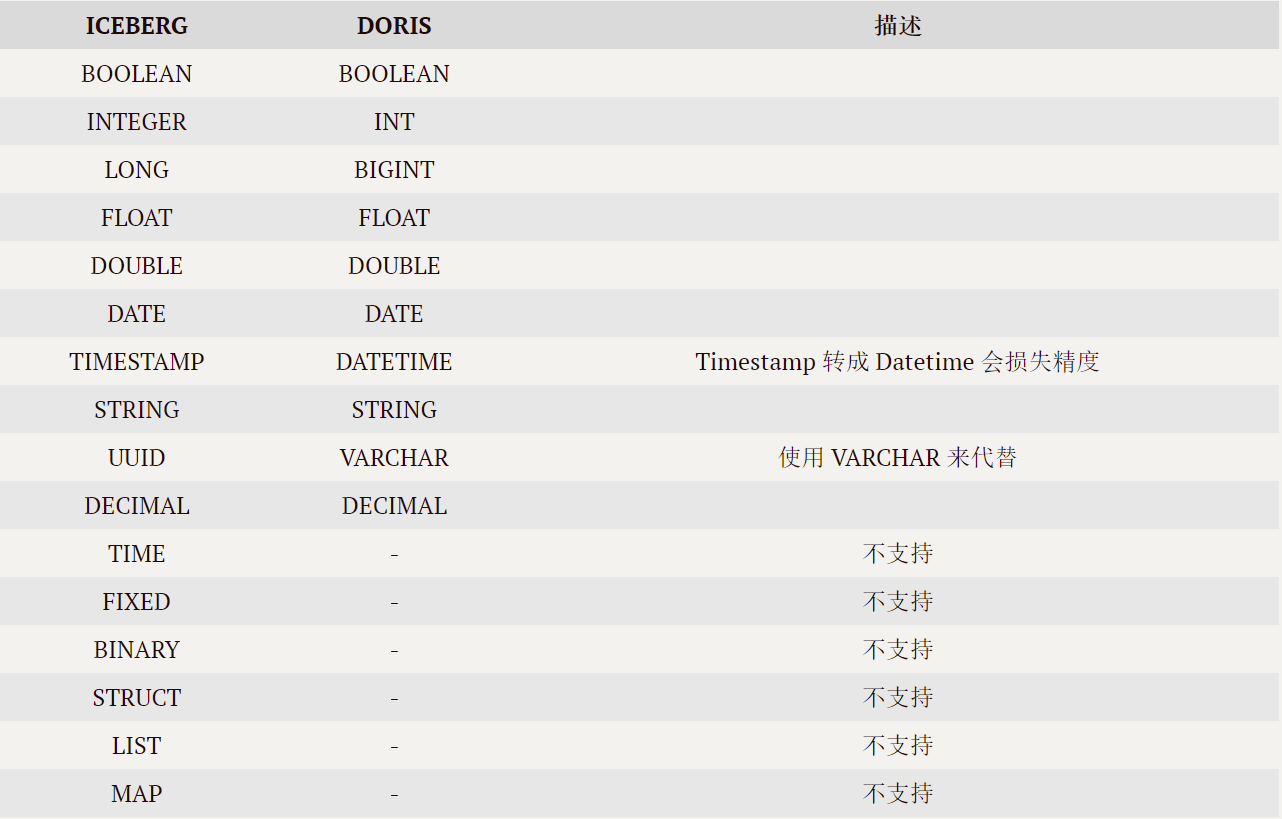
3.5 注意事项
- Iceberg 表 Schema 变更不会自动同步,需要在 Doris 中通过
REFRESH命令同步 Iceberg 外表或数据库。 - 当前默认支持的 Iceberg 版本为 0.12.0,0.13.x,未在其他版本进行测试。后续后支持更多版本。
3.6 Doris FE 配置
下面几个配置属于 Iceberg 外表系统级别的配置,可以通过修改 fe.conf 来配置,也可以通过 ADMIN SET CONFIG 来配置。
-
iceberg_table_creation_strict_mode创建 Iceberg 表默认开启 strict mode。 strict mode 是指对 Iceberg 表的列类型进行严格过滤,如果有 Doris 目前不支持的数据类型,则创建外表失败。
-
iceberg_table_creation_interval_second自动创建 Iceberg 表的后台任务执行间隔,默认为 10s。
-
max_iceberg_table_creation_record_sizeIceberg 表创建记录保留的最大值,默认为 2000. 仅针对创建 Iceberg 数据库记录。
4. 总结
这里Doris On Iceberg我们只演示了Iceberg单表的查询,你还可以联合Doris的表,或者其他的ODBC外表,Hive外表,ES外表等进行联合查询分析,通过Doris对外提供统一的查询分析入口。
自此我们完整从搭建Hadoop,hive、flink 、Mysql、Doris 及Doris On Iceberg的使用全部介绍完了,Doris 朝着数据仓库和数据融合的架构演进,支持湖仓一体的联邦查询,给我们的开发带来更多的便利,更高效的开发,省去了很多数据同步的繁琐工作,快快来体验吧.
